











A arquitetura de banco de dados começa com uma visão. Antes de escrever uma única linha de código, as estruturas de dados devem ser concebidas, organizadas e validadas. O Diagrama Entidade-Relacionamento (ERD) serve como o projeto para essa estrutura, traduzindo requisitos do mundo real em um modelo visual. No entanto, um diagrama sozinho não armazena dados. O esquema lógico é a implementação tangível que regula como as informações são armazenadas, recuperadas e protegidas fisicamente.
Transitar do ERD abstrato para o esquema concreto exige precisão. Envolve mapear entidades para tabelas, relacionamentos para chaves e atributos para colunas. Esse processo determina a integridade e o desempenho de todo o sistema. Compreender as nuances dessa tradução garante que o banco de dados permaneça robusto sob carga e adaptável às necessidades futuras.
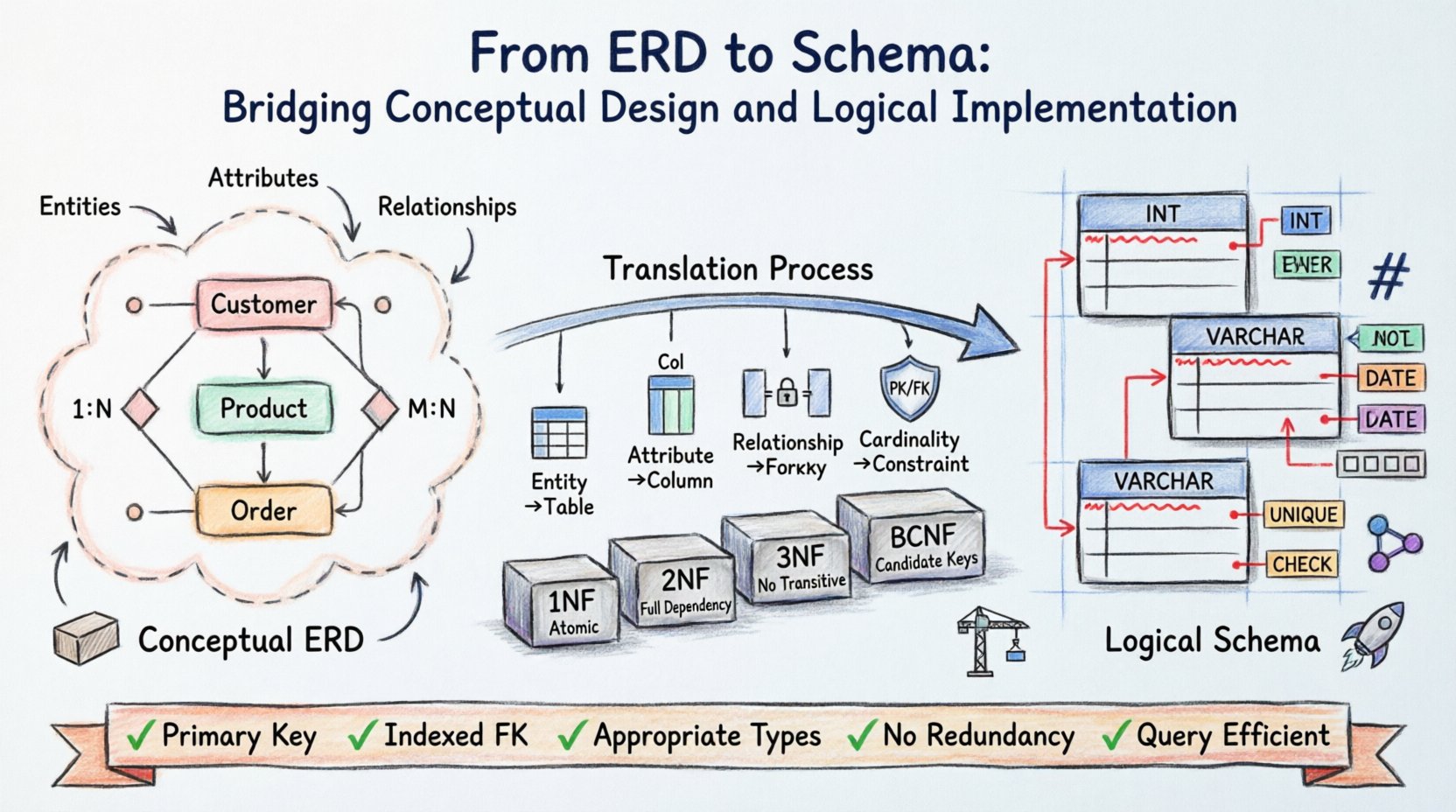
Compreendendo a Fundação Conceitual 🧱
O Diagrama Entidade-Relacionamento opera no nível conceitual. Ele se concentra no ‘o quê’ em vez do ‘como’. Nesta fase, partes interessadas e arquitetos identificam os objetos centrais de interesse dentro do domínio.
- Entidades: Elas representam objetos ou conceitos distintos, como um Cliente, Produto ou Pedido.
- Atributos: Elas definem as propriedades de uma entidade, como um Nome, Preço ou Data.
- Relacionamentos: Elas descrevem como as entidades interagem, como um Cliente fazendo um Pedido.
Nesta fase, as restrições técnicas são secundárias. O objetivo é clareza. Se o modelo conceitual for ambíguo, o esquema resultante será defeituoso. Erros comuns incluem confundir atributos com entidades ou falhar em definir corretamente a cardinalidade.
Cardinalidade e Participação
Uma das partes mais críticas do design do ERD é definir a cardinalidade. Isso determina a relação quantitativa entre entidades.
- Um para Um (1:1): Um único registro na Tabela A está relacionado a exatamente um registro na Tabela B.
- Um para Muitos (1:N): Um único registro na Tabela A está relacionado a múltiplos registros na Tabela B.
- Muitos para Muitos (M:N): Múltiplos registros na Tabela A estão relacionados a múltiplos registros na Tabela B.
As restrições de participação aprimoram ainda mais esse modelo. O relacionamento é obrigatório ou opcional? Se um Cliente deve fazer um Pedido, a participação é obrigatória. Se ele pode existir sem um Pedido, é opcional. Essas distinções influenciam diretamente a possibilidade de nulidade das colunas no esquema lógico.
O Esquema Lógico: Implementação Estrutural 🏗️
O esquema lógico pontua a lacuna entre a teoria e o armazenamento físico. Enquanto o ERD é independente de plataforma, o esquema lógico prepara os dados para mecanismos de armazenamento específicos. Essa camada introduz regras específicas sobre tipos de dados, restrições e normalização.
Diferentemente do modelo conceitual, o esquema lógico deve abordar explicitamente a integridade dos dados. Isso é alcançado por meio de chaves primárias, chaves estrangeiras e restrições únicas. Essas regras impedem registros órfãos e garantem que as relações permaneçam consistentes.
Regras de Tradução de Chaves
Traduzir chaves do ERD para o esquema exige aderência rigorosa à teoria relacional.
- Chaves Primárias: Cada entidade deve ter um identificador único. No ERD, isso geralmente é sublinhado. No esquema, torna-se a restrição PRIMARY KEY.
- Chaves Estrangeiras: Os relacionamentos são implementados por meio de chaves estrangeiras. Um relacionamento Muitos para Muitos geralmente exige uma tabela associativa com duas chaves estrangeiras para resolver a cardinalidade.
- Chaves Compostas: Se uma entidade depende de múltiplos atributos para sua unicidade, esses devem ser combinados na definição lógica.
Mapeamento de Entidades para Tabelas 🔄
O processo de converter uma Entidade em uma Tabela é simples, mas exige atenção aos detalhes. Cada entidade geralmente mapeia para uma tabela. No entanto, cenários complexos podem exigir divisão ou fusão.
Tratamento de Especialização e Generalização
Quando entidades compartilham atributos comuns, elas podem ser modeladas como subclasses. Por exemplo, uma Veículo entidade pode ter subclasses como Carro e Caminhão.
Existem duas estratégias principais para implementar isso em um esquema:
- Herança em Tabela Única: Todas as subclasses são armazenadas em uma única tabela com uma coluna discriminadora. Isso reduz as junções, mas aumenta os valores NULL.
- Herança em Tabela de Classes: Cada subclass tem sua própria tabela vinculada ao pai por uma chave estrangeira. Isso é mais normalizado, mas exige consultas mais complexas.
Mapeamento de Atributos
Atributos do ERD devem mapear para definições de coluna. Nem todos os atributos se traduzem diretamente.
- Atributos Simples: Mapeiam diretamente para colunas.
- Atributos Compostos: Devem ser divididos em colunas individuais (por exemplo, Endereço é dividido em Rua, Cidade, CEP).
- Atributos Multivalorados: Não podem ser armazenados em uma única coluna. Isso exige uma tabela separada vinculada por uma chave estrangeira (por exemplo, Números de Telefone para um Usuário).
- Atributos Derivados: São calculados a partir de outros dados (por exemplo, Idade a partir da Data de Nascimento). Geralmente são omitidos do esquema para evitar redundância, a menos que a otimização de desempenho seja crítica.
Aprofundamento na Normalização 📊
A normalização é o processo de organizar os dados para reduzir a redundância e melhorar a integridade. Ao passar do ERD para o esquema, os designers devem garantir que o modelo siga formas normais específicas.
Primeira Forma Normal (1FN)
Uma tabela está na 1FN se contém valores atômicos. Nenhuma coluna deve conter uma lista ou um conjunto de valores. Se uma entidade possui múltiplos valores para um único atributo, uma nova tabela deve ser criada.
Segunda Forma Normal (2FN)
A 2FN exige que a tabela esteja na 1FN e não tenha dependências parciais. Todos os atributos não-chave devem depender da chave primária inteira, e não apenas de parte dela. Isso é crucial para tabelas com chaves compostas.
Terceira Forma Normal (3FN)
A 3FN exige que não haja dependências transitivas. Um atributo não-chave não deve depender de outro atributo não-chave. Por exemplo, se Cidade depende de Código Postal, e Código Postal depende de ID do Cliente, Cidade deve ser movido para uma tabela separada.
Forma Normal de Boyce-Codd (FNBC)
A FNBC é uma versão mais rigorosa da 3FN. Ela trata casos em que uma tabela possui múltiplas chaves candidatas e um atributo não-chave depende de um subconjunto dessas chaves.
| Forma Normal | Requisito | Foco |
|---|---|---|
| 1FN | Valores Atômicos | Eliminar grupos repetidos |
| 2FN | Dependência Completa | Eliminar dependências parciais |
| 3FN | Sem Dependência Transitiva | Eliminar dependências indiretas |
| FNBC | Dependência de Chave Candidata | Elimine chaves sobrepostas |
Tipos de Dados e Restrições 🔒
Escolher o tipo de dado correto é vital para a eficiência de armazenamento e o desempenho das consultas. O diagrama ER raramente especifica tipos de dados exatos, deixando isso para a fase de design lógico.
Inteiro vs. Numérico
Inteiros armazenam números inteiros e são mais rápidos para cálculos. Tipos numéricos ou decimais são usados para dados financeiros para preservar precisão. Usar inteiros para moedas pode levar a erros de arredondamento.
Data e Hora
Os timestamps devem distinguir entre UTC e o horário local. Armazenar datas como strings é um erro comum que impede a classificação e filtragem eficientes. Use tipos de data padrão fornecidos pelo motor do banco de dados.
Restrições
As restrições aplicam regras de negócios ao nível do banco de dados.
- NÃO NULO: Garante que uma coluna sempre contenha um valor.
- ÚNICO: Impede valores duplicados em uma coluna.
- CHECK: Valida dados com base em uma condição específica (por exemplo, Idade > 0).
- PADRÃO: Fornece um valor padrão caso nenhum seja fornecido.
Armadilhas Comuns e Validação ⚠️
Mesmo com um plano sólido, erros podem ocorrer durante a implementação. Reconhecer essas armadilhas cedo economiza muito tempo no futuro.
- Sobrenormalização: Criar muitas tabelas pode tornar as consultas lentas e complexas. A desnormalização pode ser necessária para cargas de trabalho com leitura intensiva.
- Chaves Fracas: Usar chaves naturais (como endereços de e-mail) como chaves primárias é arriscado. Elas podem mudar e causar problemas em cascata. Chaves de substituição (IDs autoincrementáveis) são geralmente mais seguras.
- Índices Ausentes: Chaves estrangeiras devem ser indexadas. Sem elas, a junção de tabelas torna-se um gargalo de desempenho.
- Dependências Circulares: Garantir que as tabelas não criem ciclos em relacionamentos é essencial para manter a integridade referencial.
Lista de Verificação de Validação
Antes de finalizar o esquema, percorra esta lista de verificação:
- Cada tabela possui uma chave primária?
- Todas as chaves estrangeiras estão corretamente indexadas?
- Os tipos de dados são adequados para o volume esperado?
- Há colunas redundantes que podem ser removidas?
- O esquema suporta eficientemente as consultas necessárias?
Considerações de Desempenho 🚀
O esquema lógico não se trata apenas de correção; também se trata de velocidade. À medida que os dados crescem, a estrutura deve lidar com a carga aumentada.
Particionamento
Tabelas grandes podem ser divididas em pedaços menores e mais gerenciáveis. Isso pode ser feito horizontalmente (por linhas) ou verticalmente (por colunas). O particionamento permite que consultas acessem apenas os segmentos de dados relevantes.
Padrões Arquitetônicos
Padrões de design como sharding distribuem dados entre múltiplos servidores. Isso exige planejamento cuidadoso na fase de design lógico para garantir que os dados relacionados permaneçam juntos, quando possível.
Resumo das Melhores Práticas ✅
Construir um esquema de banco de dados é um processo iterativo. Exige equilibrar a pureza teórica com as restrições práticas.
- Documente Tudo:Mantenha documentação clara que ligue os elementos do ERD às definições do esquema.
- Controle de Versão:Trate as alterações no esquema como código. Use scripts de migração para rastrear alterações ao longo do tempo.
- Revise Regularmente:À medida que as necessidades do negócio evoluem, o esquema também deve evoluir. Agende auditorias periódicas para garantir alinhamento com os requisitos atuais.
- Colabore:Envolve desenvolvedores, analistas e partes interessadas desde cedo. Perspectivas diferentes revelam casos extremos que um único designer poderia ignorar.
A transição do Diagrama Entidade-Relacionamento para o Esquema Lógico é a base da engenharia de dados. Ela transforma ideias abstratas em um sistema funcional. Ao seguir as regras de normalização, selecionar tipos de dados apropriados e antecipar necessidades de desempenho, o banco de dados resultante servirá como uma base confiável para aplicativos.
Em última análise, a qualidade do esquema determina a longevidade do sistema. Um design bem estruturado minimiza a dívida técnica e facilita o crescimento futuro. Foque na clareza, integridade e escalabilidade para construir sistemas que resistam ao teste do tempo.