











Построение надежной инфраструктуры базы данных требует точности на каждом этапе разработки. Диаграмма сущностей и связей (ERD) служит чертежом для этой структуры. Она определяет, как взаимодействуют сущности данных, как протекает информация и как поддерживается целостность на протяжении всего жизненного цикла системы. Пропуск тщательной проверки ERD может привести к дорогостоящей рефакторингу, повреждению данных и узким местам производительности в будущем. Данное руководство предоставляет подробный, выполнимый чек-лист для проверки вашей схемы перед началом реализации.
Архитекторы баз данных и разработчики должны подходить к проектированию схемы с критическим взглядом. Стоимость исправления структурной ошибки в рабочей среде значительно выше, чем затраты на её исправление на этапе проектирования. Следуя структурированному процессу проверки, команды обеспечивают, что итоговая база данных поддерживает бизнес-логику, соответствует принципам нормализации и остается масштабируемой.
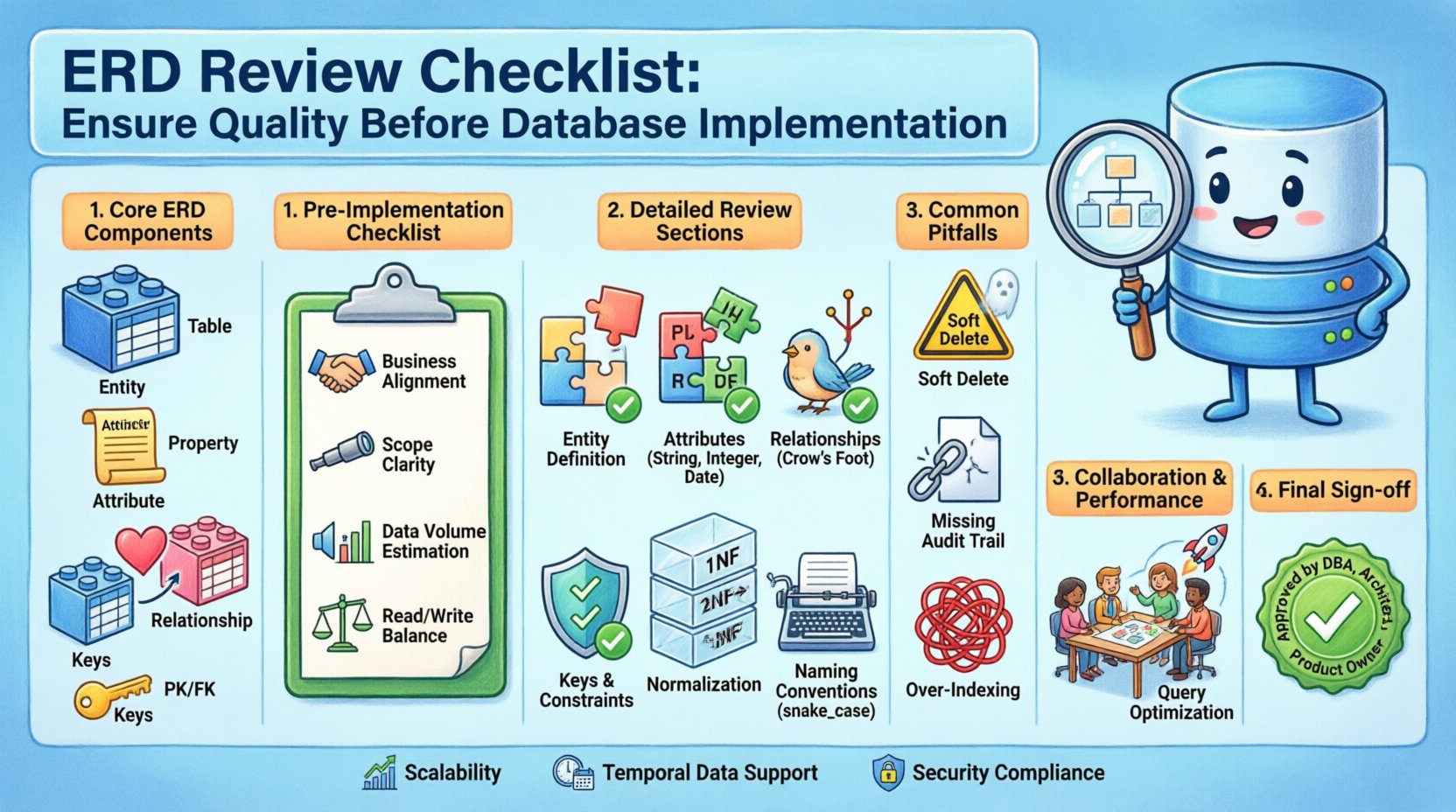
Понимание основных компонентов ERD 🔍
Прежде чем приступать к чек-листу, необходимо понимать основные элементы, из которых состоит стандартная диаграмма сущностей и связей. Эти компоненты формируют лексику вашей модели данных.
- Сущности: Они представляют реальные объекты или понятия, по которым хранятся данные. В реляционном контексте сущности обычно отображаются в таблицах.
- Атрибуты: Они описывают свойства или характеристики сущности. Они отображаются в столбцах таблицы.
- Связи: Они определяют взаимосвязи между сущностями. Они показывают, как данные в одной таблице связаны с данными в другой.
- Кардинальность и ключи: Кардинальность определяет числовое отношение между сущностями (например, один к одному, многие ко многим). Ключи обеспечивают уникальную идентификацию и связность.
Высококачественная ERD должна четко выражать эти элементы. Неоднозначность на диаграмме напрямую превращается в неоднозначность в коде, что приводит к ошибкам при реализации.
Шаги предварительной проверки перед реализацией ✅
Прежде чем применять конкретные пункты чек-листа, общее понимание базы данных должно соответствовать бизнес-требованиям. На этом этапе обеспечивается соответствие модели её цели.
- Соответствие бизнес-требованиям: Убедитесь, что каждая сущность и связь соответствуют конкретному бизнес-правилу или пользовательской истории.
- Определение границ: Подтвердите границы данных. Мы проектируем для одного приложения, микросервиса или корпоративного хранилища данных?
- Оценка объема данных: Учитывайте ожидаемый объем записей. Это влияет на решения по стратегиям индексации и партиционирования.
- Соотношение чтения/записи: Понимайте профиль рабочей нагрузки. Приложение с высокой нагрузкой на чтение может потребовать денормализации, тогда как система с высокой нагрузкой на запись ставит во главу угла строгую целостность.
Подробный чек-лист проверки ERD 📝
В этом разделе рассматриваются конкретные технические атрибуты, которые требуют тщательной проверки. Используйте этот список как инструмент проверки во время сессий обзора проекта.
1. Определение сущности и таблицы
Каждая сущность на диаграмме должна быть уникальной и хорошо определенной. Распространённая ошибка — создание перекрывающихся сущностей, которые следует объединить, или избыточное разделение одного понятия на несколько таблиц.
- Уникальность: Убедитесь, что каждая таблица представляет уникальное понятие. Избегайте таблиц, хранящих схожие данные для разных целей без четкого различия.
- Детализация: Проверьте, не слишком ли детализированы таблицы. Избыточное разделение может привести к сложным соединениям и ухудшению производительности.
- Соглашения об именовании: Проверьте согласованность. Имена таблиц должны быть в единственном числе (например,
КлиентвместоКлиенты) для согласования с паттернами объектно-ориентированного отображения. - Метаданные: Убедитесь, что в каждой таблице присутствуют временные метки создания и изменения, чтобы поддерживать аудит и отслеживание происхождения данных.
2. Атрибуты и типы данных
Атрибуты определяют характер хранящихся данных. Правильный выбор типа данных критически важен для эффективного использования хранилища и производительности запросов.
- Основные типы данных: Убедитесь, что целые числа, строки и логические значения используются правильно. Избегайте использования строк для дат или чисел.
- Ограничения длины: Определите максимальную длину для строковых полей. Это предотвращает избыточное использование памяти и обеспечивает согласованность при проверке ввода.
- Допустимость пустых значений: Явно определите, может ли поле быть пустым. Большинство полей не должны допускать пустые значения, если бизнес-логика не разрешает этого.
- Значения по умолчанию: Проверьте, необходимы ли значения по умолчанию. Например, поле статуса может иметь значение «активен» по умолчанию, вместо того чтобы требовать первоначальный ввод.
- Перечисляемые значения: При необходимости используйте перечисляемые списки для ограничения значений. Это предотвращает ввод недопустимых данных на исходном уровне.
3. Связи и кардинальность
Связи — это то, что объединяет модель данных. Ошибки здесь приводят к несвязанным записям или дублированию данных.
| Тип связи | Описание | Примечание по реализации |
|---|---|---|
| Один к одному (1:1) | Одна запись в таблице A связана ровно с одной записью в таблице B. | Обычно реализуется путем размещения первичного ключа A в качестве внешнего ключа в B. |
| Один ко многим (1:М) | Одна запись в таблице А связана с несколькими записями в таблице Б. | Разместите первичный ключ А в качестве внешнего ключа в Б. |
| Многие ко многим (М:М) | Записи в А могут быть связаны с несколькими в Б, и наоборот. | Требуется промежуточная таблица, связывающая два первичных ключа. |
- Проверка кардинальности:Просмотрите нотацию клювов или эквивалентную ей, чтобы убедиться, что направление отношения правильное.
- Опциональность:Различайте обязательные и необязательные отношения. Ограничение внешнего ключа должно отражать, должен ли существовать связанный запись.
- Рекурсивные отношения: Проверьте наличие самоссылочных таблиц (например, таблица
Сотрудниксвязывается сРуководителемID в той же таблице). - Циклические зависимости: Убедитесь, что отношения не создают циклические цепочки, которые усложняют загрузку или запрос данных.
4. Ключи и ограничения
Ключи — это механизм обеспечения уникальности и связи. Без правильных ключей целостность данных рушится.
- Первичные ключи: У каждой таблицы должен быть первичный ключ. Он должен быть уникальным и никогда не быть пустым.
- Суррогатные ключи: Рассмотрите возможность использования системно генерируемых идентификаторов (суррогатных ключей) вместо естественных бизнес-ключей. Это предотвратит влияние изменений в бизнес-логике на структуру базы данных.
- Внешние ключи: Убедитесь, что все внешние ключи ссылаются на действительные первичные ключи в родительских таблицах.
- Ограничения уникальности: Определите поля, которые должны быть уникальными (например, адреса электронной почты, номера счетов), но не являются первичным ключом.
- Ограничения проверки: Ищите логические правила, которые нельзя обеспечить только типами данных (например,
дата_началадолжен быть додата_окончания).
5. Нормализация
Нормализация уменьшает избыточность и улучшает целостность данных. Хотя чрезмерная нормализация может негативно сказаться на производительности, недостаточная нормализация приводит к аномалиям.
- Первое нормальное формат (1NF): Обеспечьте атомарные значения. Не должно быть повторяющихся групп или массивов в одной ячейке.
- Второе нормальное формат (2NF): Убедитесь, что все неключевые атрибуты полностью зависят от первичного ключа, а не только от его части.
- Третье нормальное формат (3NF): Убедитесь, что нет транзитивных зависимостей. Неключевые атрибуты должны зависеть только от первичного ключа, а не от других неключевых атрибутов.
- Стратегия денормализации: Если производительность является проблемой, документируйте, где и почему применяется денормализация. Это должно быть осознанное решение, а не упущение.
6. Правила именования
Согласованное именование снижает когнитивную нагрузку для разработчиков и уменьшает вероятность ошибок.
- Имена таблиц: Используйте единственное число (например,
Заказ, а неЗаказы). - Имена столбцов: Используйте snake_case для согласованности (например,
создано_в). - Избегайте зарезервированных слов: Убедитесь, что имена столбцов не конфликтуют с ключевыми словами SQL (например,
пользователь,порядок,группа). - Четкость: Имена должны быть описательными. Избегайте сокращений, если они не являются отраслевыми стандартами.
Распространенные ошибки, которые следует избегать ⚠️
Даже опытные дизайнеры могут упустить важные детали. Осознание распространенных ловушек помогает поддерживать чистую схему.
- Пренебрежение мягким удалением: Определите, нужно ли полностью удалять данные или логически помечать их как неактивные. Флаг
is_deletedчасто безопаснее, чем физическое удаление. - Отсутствие следов аудита: Убедитесь, что есть механизм отслеживания, кто изменил данные и когда. Это критически важно для соблюдения требований.
- Чрезмерное индексирование: Слишком большое количество индексов замедляет операции записи. Проверьте шаблоны запросов, чтобы обосновать размещение индексов.
- Жестко закодированные значения: Избегайте хранения конкретных значений, таких как коды стран, в виде строк, если они могут быть сопоставлены со справочной таблицей.
- Неявные предположения: Не предполагайте, что поле является необязательным, если бизнес-логика требует его наличия. Четко документируйте предположения.
Сотрудничество и документирование 🤝
Схема ERD — это не просто технический артефакт; это инструмент коммуникации. Ее должны понимать заинтересованные стороны, а не только администраторы баз данных.
- Обзор заинтересованных сторон: Пусть бизнес-аналитики проверят схему, чтобы убедиться, что она соответствует их представлению о процессе.
- Контроль версий: Рассматривайте ERD как код. Храните его в системе контроля версий, чтобы отслеживать изменения с течением времени.
- Документация: Включите словарь данных вместе со схемой. Определите, что означает каждое поле и его допустимый диапазон.
- Управление изменениями: Установите процесс изменения схемы. Изменения должны быть проверены и одобрены, а не применены вручную.
Рассмотрение производительности 🚀
Хотя ERD является логическим, он должен соответствовать физическим целям производительности. Некоторые решения в проектировании напрямую влияют на производительность.
- Сложность соединений:Минимизируйте количество соединений, необходимых для типичных запросов. Сложные соединения могут нагружать оптимизатор запросов.
- Готовность к партиционированию: Проектируйте таблицы с учетом партиционирования, если ожидается, что объем данных станет чрезвычайно большим.
- Поисковая способность: Убедитесь, что поля, которые часто используются в поиске, индексированы. Учитывайте требования к полнотекстовому поиску для полей с большим объемом текста.
- Параллелизм: Оцените стратегии блокировки. В средах с высокой конкуренцией могут потребоваться определенные уровни изоляции или особые схемы таблиц.
Финальные критерии утверждения 🏁
Прежде чем приступать к реализации, ERD должен соответствовать определенным критериям приемки. Это обеспечивает плавный переход от проектирования к разработке.
- Полнота: Все сущности и связи, необходимые в рамках охвата, присутствуют.
- Согласованность: Правила именования и типы данных применяются единообразно.
- Целостность: Ограничения первичных и внешних ключей правильно определены.
- Четкость: Диаграмма читаема и понятна команде разработчиков.
- Утверждение: Ключевые заинтересованные стороны утвердили проект.
Соблюдение этого чек-листа гарантирует прочность базы данных. Это снижает технический долг и способствует более плавному циклу разработки. Хорошо проверенный ERD — это первый шаг к устойчивой архитектуре данных.
Проверка ERD на будущую масштабируемость
Проектирование только для настоящего недостаточно. Модель данных должна обеспечивать рост без необходимости полной перестройки.
- Горизонтальное масштабирование: Учитывайте, как шардирование может повлиять на связи. Внешние ключи между шардами сложны и часто избегаются.
- Вертикальное масштабирование: Убедитесь, что типы данных могут обрабатывать большие значения. Например, использование
BIGINTвместоЦЕЛЫЕдля счетчиков. - Флаги функций: Разработайте таблицы для поддержки мягких флагов функций. Это позволяет включать или отключать новую функциональность без изменений схемы.
- Обратная совместимость: Планируйте миграции схемы. Добавление столбцов не должно нарушать существующие запросы.
Обработка особых случаев, таких как временные данные
Время — критический аспект моделирования данных. Правильная обработка истории часто игнорируется.
- Даты действия: Для сущностей, которые изменяются со временем, включите даты начала и окончания для отслеживания истории.
- Часовые пояса: Храните метки времени в формате UTC, чтобы избежать неоднозначности в разных регионах.
- Снимки: Определите, требуются ли исторические снимки. Это может потребовать отдельной таблицы истории.
- Временные таблицы: Некоторые системы поддерживают встроенные временные таблицы. Оцените, соответствует ли это архитектурным ограничениям.
Безопасность и соответствие в схеме
Безопасность данных начинается на уровне таблицы. Структура должна поддерживать требования к конфиденциальности и защите.
- Обработка ПИИ: Определите поля, содержащие персональную информацию. Эти поля требуют шифрования или маскировки.
- Контроль доступа: Разработайте роли и разрешения на основе чувствительности данных, определенной в схеме.
- Шифрование при хранении: Убедитесь, что движок базы данных поддерживает шифрование для чувствительных полей.
- Политики хранения: Определите поля, указывающие, когда данные могут быть удалены в соответствии с законодательными требованиями.
Применяя эти проверки строго, база данных становится надежным активом, а не угрозой. Вложения усилий на этапе проверки ERD окупаются в плане поддерживаемости и производительности.