











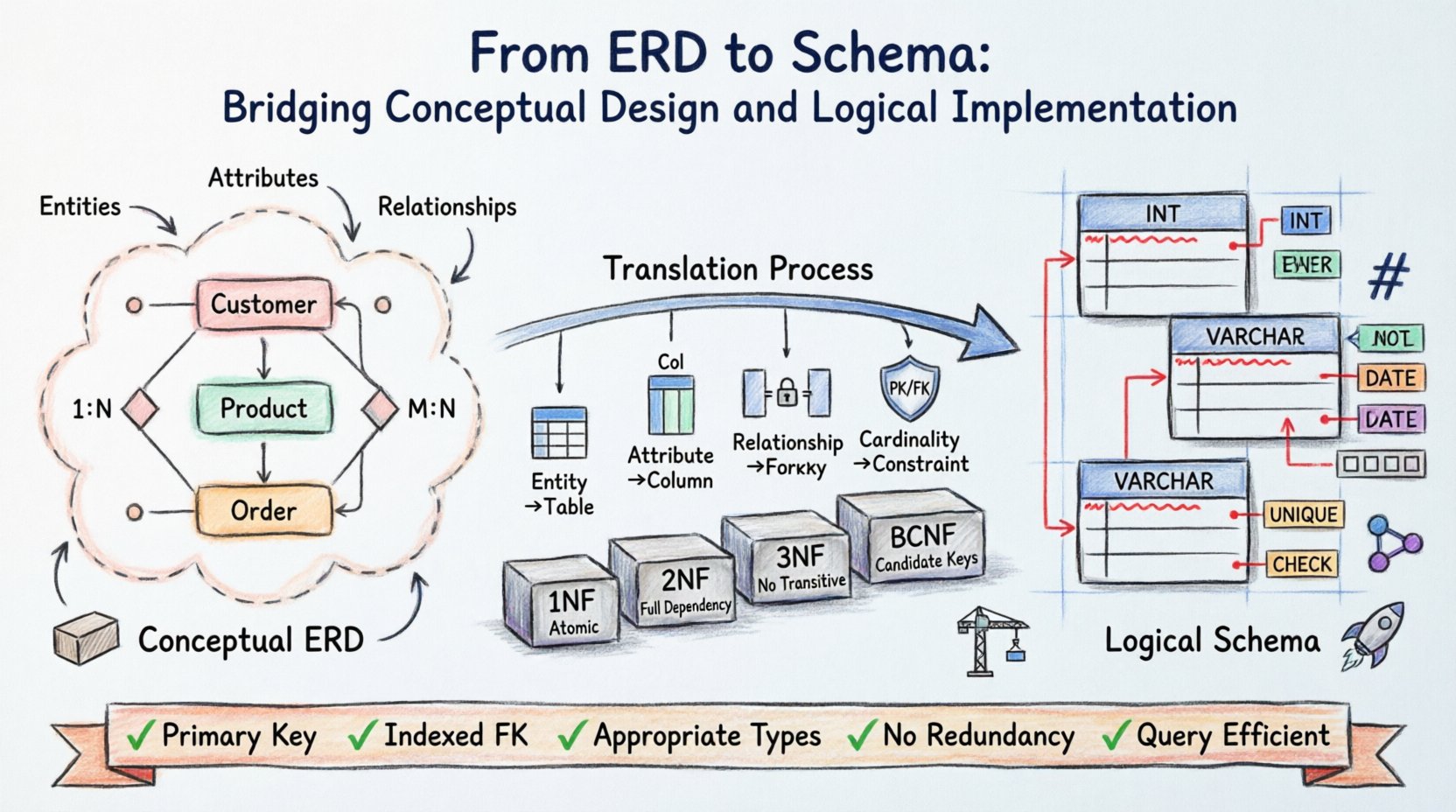
Архитектура базы данных начинается с видения. До написания первой строки кода структуры данных должны быть концептуализированы, организованы и проверены. Диаграмма сущностей и отношений (ERD) служит чертежом для этой структуры, переводя реальные требования в визуальную модель. Однако диаграмма сама по себе не хранит данные. Логическая схема — это осязаемая реализация, которая определяет, как информация физически хранится, извлекается и защищается.
Переход от абстрактной ERD к конкретной схеме требует точности. Это включает в себя сопоставление сущностей с таблицами, отношений с ключами, а атрибутов — с колонками. Этот процесс определяет целостность и производительность всей системы. Понимание нюансов этого перевода гарантирует, что база данных останется устойчивой при нагрузке и адаптируемой к будущим потребностям.
Понимание концептуальной основы 🧱
Диаграмма сущностей и отношений работает на концептуальном уровне. Она фокусируется на «что», а не на «как». На этом этапе заинтересованные стороны и архитекторы определяют основные объекты, представляющие интерес в рамках домена.
- Сущности: Они представляют отдельные объекты или понятия, такие как Клиент, Продукт или Заказ.
- Атрибуты: Они определяют свойства сущности, такие как Имя, Цена или Дата.
- Отношения: Они описывают, как сущности взаимодействуют, например, Клиент размещает Заказ.
На этом этапе технические ограничения второстепенны. Цель — ясность. Если концептуальная модель неоднозначна, то получившаяся схема будет ошибочной. Распространённые ошибки включают смешение атрибутов с сущностями или неправильное определение кардинальности.
Кардинальность и участие
Одним из наиболее важных аспектов проектирования ERD является определение кардинальности. Это определяет количественные отношения между сущностями.
- Один к одному (1:1): Одна запись в таблице A связана с точной одной записью в таблице B.
- Один ко многим (1:N): Одна запись в таблице A связана с несколькими записями в таблице B.
- Многие ко многим (M:N): Несколько записей в таблице A связаны с несколькими записями в таблице B.
Ограничения участия дополнительно уточняют эту модель. Отношение обязательное или необязательное? Если Клиент должен разместить Заказ, участие является обязательным. Если он может существовать без Заказа, участие — необязательное. Эти различия напрямую влияют на возможность значений NULL в столбцах логической схемы.
Логическая схема: структурная реализация 🏗️
Логическая схема служит мостом между теорией и физическим хранением. В то время как ERD независима от платформы, логическая схема готовит данные к конкретным механизмам хранения. На этом уровне вводятся конкретные правила, касающиеся типов данных, ограничений и нормализации.
В отличие от концептуальной модели, логическая схема должна явно учитывать целостность данных. Это достигается с помощью первичных ключей, внешних ключей и уникальных ограничений. Эти правила предотвращают появление «сиротских» записей и обеспечивают стабильность связей.
Правила перевода ключей
Перевод ключей с ERD на схему требует строгого соблюдения теории реляционных баз данных.
- Первичные ключи: У каждой сущности должен быть уникальный идентификатор. В ERD он часто подчёркивается. В схеме он становится ограничением PRIMARY KEY.
- Внешние ключи: Отношения реализуются с помощью внешних ключей. Отношение «многие ко многим» обычно требует ассоциативной таблицы с двумя внешними ключами для разрешения кардинальности.
- Составные ключи: Если сущность зависит от нескольких атрибутов для уникальности, они должны быть объединены в логическом определении.
Сопоставление сущностей таблицам 🔄
Процесс преобразования сущности в таблицу прост, но требует внимания к деталям. Каждая сущность обычно отображается в одной таблице. Однако сложные сценарии могут потребовать разделения или объединения.
Обработка специализации и обобщения
Когда сущности имеют общие атрибуты, они могут быть смоделированы как подклассы. Например, сущность Транспортное средство может иметь подклассы, такие как Автомобиль и Грузовик.
Существует два основных подхода к реализации этого в схеме:
- Наследование в одной таблице: Все подклассы хранятся в одной таблице с столбцом-дискриминатором. Это уменьшает количество соединений, но увеличивает количество значений NULL.
- Наследование через таблицы классов: Каждый подкласс получает собственную таблицу, связанную с родителем с помощью внешнего ключа. Это более нормализовано, но требует более сложных запросов.
Сопоставление атрибутов
Атрибуты из диаграммы ERD должны соответствовать определениям столбцов. Не все атрибуты переводятся напрямую.
- Простые атрибуты: Непосредственно отображаются на столбцы.
- Составные атрибуты: Должны быть разбиты на отдельные столбцы (например, Адрес разделяется на Улица, Город, Индекс).
- Многозначные атрибуты: Не могут храниться в одном столбце. Для них требуется отдельная таблица, связанная внешним ключом (например, Номера телефонов для пользователя).
- Производные атрибуты: Они вычисляются на основе других данных (например, Возраст из Даты рождения). Часто они опускаются из схемы, чтобы избежать избыточности, если оптимизация производительности не является критичной.
Глубокое погружение в нормализацию 📊
Нормализация — это процесс организации данных для уменьшения избыточности и повышения целостности. При переходе от ERD к схеме разработчики должны обеспечить соответствие модели определённым нормальным формам.
Первая нормальная форма (1NF)
Таблица находится в 1НФ, если она содержит атомарные значения. Ни один столбец не должен содержать список или набор значений. Если сущность имеет несколько значений для одного атрибута, необходимо создать новую таблицу.
Вторая нормальная форма (2НФ)
2НФ требует, чтобы таблица находилась в 1НФ и не имела частичных зависимостей. Все атрибуты, не являющиеся ключевыми, должны зависеть от всего первичного ключа, а не только от его части. Это особенно важно для таблиц с составными ключами.
Третья нормальная форма (3НФ)
3НФ требует отсутствия транзитивных зависимостей. Атрибут, не являющийся ключевым, не должен зависеть от другого атрибута, не являющегося ключевым. Например, если Город зависит от Почтовый индекс, и Почтовый индекс зависит от Идентификатор клиента, Город должен быть перемещен в отдельную таблицу.
Нормальная форма Бойса-Кодда (НФБК)
НФБК — более строгая версия 3НФ. Она учитывает случаи, когда таблица имеет несколько кандидатских ключей, а не ключевой атрибут зависит от подмножества этих ключей.
| Нормальная форма | Требование | Фокус |
|---|---|---|
| 1НФ | Атомарные значения | Устранить повторяющиеся группы |
| 2НФ | Полная зависимость | Устранить частичные зависимости |
| 3НФ | Отсутствие транзитивных зависимостей | Устранить косвенные зависимости |
| BCNF | Зависимость кандидатского ключа | Устранить перекрывающиеся ключи |
Типы данных и ограничения 🔒
Выбор правильного типа данных имеет решающее значение для эффективности хранения и производительности запросов. ERD редко указывает точные типы данных, оставляя это на этапе логического проектирования.
Целое число против числового
Целые числа хранят целые числа и быстрее для вычислений. Числовые или десятичные типы используются для финансовых данных, чтобы сохранить точность. Использование целых чисел для валюты может привести к ошибкам округления.
Дата и время
Метки времени должны различать UTC и местное время. Хранение дат в виде строк — распространенная ошибка, которая мешает эффективной сортировке и фильтрации. Используйте стандартные типы дат, предоставляемые движком базы данных.
Ограничения
Ограничения обеспечивают соблюдение бизнес-правил на уровне базы данных.
- НЕ ПУСТО:Обеспечивает, что столбец всегда содержит значение.
- УНИКАЛЬНО:Предотвращает дублирование значений в столбце.
- ПРОВЕРКА:Проверяет данные на соответствие определённому условию (например, возраст > 0).
- ПО УМОЛЧАНИЮ: Предоставляет значение по умолчанию, если значение не указано.
Распространённые ошибки и проверка ⚠️
Даже при наличии надёжного плана ошибки могут возникнуть во время реализации. Раннее распознавание этих ошибок экономит значительное время в будущем.
- Чрезмерная нормализация:Создание слишком большого количества таблиц может замедлить и усложнить запросы. Для рабочих нагрузок с высокой интенсивностью чтения может потребоваться денормализация.
- Слабые ключи:Использование естественных ключей (например, адресов электронной почты) в качестве первичных ключей опасно. Они могут изменяться и вызывать цепные сбои. Суррогатные ключи (автоинкрементные идентификаторы) часто безопаснее.
- Отсутствующие индексы:Внешние ключи должны быть проиндексированы. Без них объединение таблиц становится узким местом производительности.
- Циклические зависимости:Обеспечение того, чтобы таблицы не создавали циклы в отношениях, критически важно для поддержания целостности ссылок.
Чек-лист проверки
Прежде чем завершить схему, пройдитесь по этому списку проверки:
- Имеет ли каждая таблица первичный ключ?
- Проиндексированы ли все внешние ключи правильно?
- Подходят ли типы данных для ожидаемого объема?
- Есть ли избыточные столбцы, которые можно удалить?
- Поддерживает ли схема необходимые запросы эффективно?
Рассмотрение производительности 🚀
Логическая схема — это не только правильность, но и скорость. По мере роста данных структура должна справляться с увеличивающейся нагрузкой.
Разделение
Большие таблицы можно разделить на более мелкие и управляемые части. Это можно сделать горизонтально (по строкам) или вертикально (по столбцам). Разделение позволяет запросам получать доступ только к соответствующим сегментам данных.
Архитектурные паттерны
Паттерны проектирования, такие как шардирование, распределяют данные по нескольким серверам. Это требует тщательного планирования на этапе логического проектирования, чтобы обеспечить, чтобы связанная информация оставалась вместе, где это возможно.
Обзор лучших практик ✅
Создание схемы базы данных — это итеративный процесс. Требуется балансировать теоретическую чистоту с практическими ограничениями.
- Документируйте всё:Поддерживайте четкую документацию, связывающую элементы ERD с определениями схемы.
- Контроль версий:Рассматривайте изменения схемы как код. Используйте скрипты миграции для отслеживания изменений с течением времени.
- Регулярно проводите обзор:По мере изменения бизнес-потребностей должна меняться и схема. Планируйте периодические аудиты, чтобы обеспечить соответствие текущим требованиям.
- Сотрудничайте:Привлекайте разработчиков, аналитиков и заинтересованные стороны на ранних этапах. Разные точки зрения выявляют крайние случаи, которые может упустить один дизайнер.
Переход от диаграммы сущность-связь к логической схеме — это основа инженерии данных. Он превращает абстрактные идеи в функциональную систему. Соблюдая правила нормализации, выбирая подходящие типы данных и учитывая потребности в производительности, полученная база данных станет надежной основой для приложений.
В конечном счете, качество схемы определяет долговечность системы. Хорошо структурированный дизайн минимизирует технический долг и способствует будущему росту. Сосредоточьтесь на ясности, целостности и масштабируемости, чтобы создавать системы, выдерживающие испытание временем.