










Создание архитектуры технологий, поддерживающей рост, требует больше, чем просто сбор компонентов. Это требует стратегического подхода, который предвидит спрос, обеспечивает устойчивость и поддерживает производительность под нагрузкой. Когда организации стремятся к масштабируемости, они не просто ищут скорость; они ищут выносливость и адаптивность. В этом руководстве рассматриваются принципы, рамки и структурные элементы, необходимые для планирования архитектуры технологий для масштабируемой инфраструктуры. Мы подробно изучим, как проверенные методологии, такие как фреймворк TOGAF, могут направлять эти решения без привязки к конкретным решениям поставщиков.
Масштабируемость — это способность системы обрабатывать увеличение нагрузки за счёт добавления ресурсов. Однако истинная архитектурная масштабируемость подразумевает проектирование систем, в которых рост не ставит под угрозу стабильность. Это требует глубокого понимания нефункциональных требований, потоков данных и взаимодействия между аппаратными и программными слоями. Ориентируясь на основополагающие принципы, команды могут создавать среды, которые органично расширяются вместе с потребностями бизнеса.
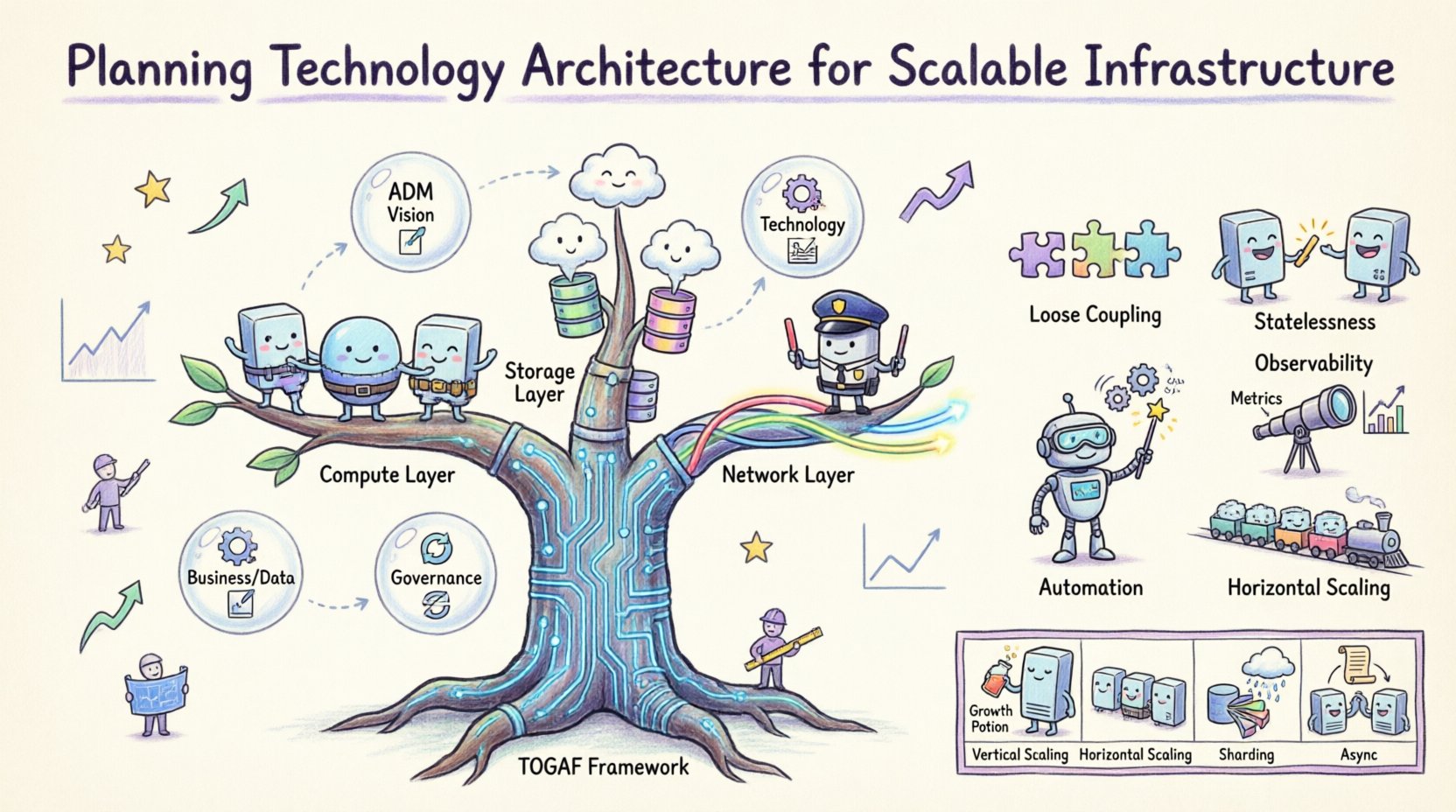
Понимание TOGAF в контексте инфраструктуры 🧭
Фреймворк архитектуры The Open Group (TOGAF) обеспечивает структуированный подход к проектированию, планированию, реализации и управлению архитектурой информационных систем предприятия. Хотя он часто ассоциируется с высоким уровнем бизнес-стратегии, применение Методологии разработки архитектуры (ADM) в TOGAF чрезвычайно эффективно для планирования инфраструктуры. TOGAF обеспечивает соответствие технических решений бизнес-целям, предотвращая создание изолированных систем, которые не могут взаимодействовать или эффективно масштабироваться.
При применении TOGAF к архитектуре технологий акцент смещается на этап архитектуры технологий. На этом этапе определяются аппаратные, программные и сетевые возможности, необходимые для поддержки приоритетных бизнес-процессов. Он служит мостом между логическими бизнес-требованиями и физической реализацией.
- Согласованность:Обеспечивает, чтобы инфраструктура поддерживала текущие и будущие бизнес-цели.
- Стандартизация:Снижает сложность за счёт внедрения общих стандартов технологий.
- Интеграция:Обеспечивает плавный обмен данными между различными уровнями системы.
- Управляемость:Упрощает эксплуатацию и обслуживание на протяжении всего жизненного цикла системы.
Использование такого фреймворка предотвращает произвольное масштабирование, при котором новые ресурсы добавляются без согласованного плана. Вместо этого оно способствует комплексному подходу, при котором масштабирование представляет собой планомерное развитие, а не реактивное решение.
Цикл методологии разработки архитектуры (ADM) ⏳
Цикл ADM является основой методологии TOGAF. Он итеративный, что позволяет архитекторам уточнять свои проекты по мере изменения требований. Для планирования инфраструктуры конкретные этапы предоставляют критически важные сведения.
Этап A: Видение архитектуры 🎯
На этом этапе определяется охват и ограничения, задавая основу для дальнейшей работы. При планировании инфраструктуры это включает понимание прогнозируемых темпов роста, регуляторных требований и показателей производительности. Заинтересованные стороны согласовывают определение масштабируемости в организации. Цель — обрабатывать в десять раз больше нагрузки, чем сейчас, или поддерживать новые географические регионы? Эти вопросы формируют технический путь развития.
Этапы B и C: Архитектура бизнеса и информационных систем 📊
Прежде чем проектировать серверы или сети, необходимо понимать данные и приложения, которые будут на них работать. Этап B выявляет бизнес-процессы. Этап C определяет архитектуру данных и архитектуру приложений. Масштабируемость в значительной степени зависит от того, как структурированы и доступны данные. Если модель данных жёсткая, инфраструктура не сможет эффективно масштабироваться. На этом этапе обеспечивается ранняя документация логических требований к объёму данных и скорости транзакций.
Этап D: Архитектура технологий 🖥️
Это критически важный этап для планирования инфраструктуры. Он переводит логические требования этапа C в физические спецификации. Охватывает выбор платформы, топологию сети и архитектуру безопасности. Цель — создать чертёж, который обеспечивает необходимую пропускную способность и доступность. Ключевые аспекты включают:
- Вычислительные ресурсы:Определение баланса между вычислительной мощностью и объёмом памяти.
- Стратегии хранения:Принятие решения между локальными и распределёнными решениями хранения.
- Пропускная способность сети:Обеспечение достаточной ёмкости для передачи данных между узлами.
- Устойчивость: Проектирование с избыточностью для предотвращения узких мест.
Этапы E–H: возможности, планирование, управление и изменения 🔄
Эти этапы управляют внедрением и непрерывной эволюцией. Масштабируемость — это не разовое событие, а непрерывный процесс. Управление обеспечивает, чтобы изменения в инфраструктуре не снижали производительность. Управление изменениями позволяет архитектуре адаптироваться к новым технологиям или изменяющимся рыночным требованиям без необходимости полной перестройки.
Ключевые архитектурные принципы роста 📈
Для достижения масштабируемости определённые принципы должны руководить каждым решением. Эти принципы выступают в роли ограничителей, обеспечивая, чтобы архитектура оставалась надёжной при расширении.
- Разделённая связь:Компоненты должны работать независимо. Если один сервис выходит из строя или требует масштабирования, это не должно повлиять на другие. Это позволяет выделять ресурсы целенаправленно.
- Безсостоятельность:Серверы приложений не должны хранить данные сессий пользователей локально. Это позволяет любому серверу обрабатывать любой запрос, упрощая распределение нагрузки.
- Автоматизация: Ручное масштабирование медленное и подвержено ошибкам. Процессы выделения и настройки ресурсов должны быть автоматизированы.
- Наблюдаемость: Система должна обеспечивать чёткую видимость своего собственного состояния. Метрики, журналы и трассировки необходимы для выявления узких мест до того, как они приведут к сбоям.
- Горизонтальное масштабирование: Добавление дополнительных узлов в кластер часто более эффективно и экономически выгодно, чем увеличение мощности одного узла.
Соблюдение этих принципов снижает технический долг и создаёт основу, способную поддерживать быстрое расширение.
Разбор компонентов инфраструктуры 💻
Масштабируемая инфраструктура состоит из нескольких взаимосвязанных уровней. Каждый уровень должен быть спроектирован так, чтобы справляться с ростом нагрузки без возникновения узких мест.
Уровень вычислений
Уровень вычислений — это место, где выполняется бизнес-логика. Для масштабируемости акцент делается на эластичности. Ресурсы должны выделяться динамически в зависимости от спроса. Это включает группировку вычислительных ресурсов в пулы, которые могут автоматически расширяться или сокращаться. Ключевые аспекты включают:
- Архитектура процессора: Выбор наборов инструкций, оптимизированных для конкретной рабочей нагрузки.
- Управление памятью: Обеспечение достаточного объёма ОЗУ для обработки одновременных процессов без использования подкачки.
- Контейнеризация: Использование лёгкой упаковки для изоляции приложений и эффективного управления ограничениями ресурсов.
Уровень хранения
Рост данных неизбежен. Архитектура хранения должна обеспечивать обработку растущих объёмов данных при сохранении низкой задержки. Для крупномасштабных сред часто предпочтительнее распределённые системы хранения данных, чем централизованные массивы. Они обеспечивают лучшую отказоустойчивость и возможность постепенного увеличения ёмкости.
- Разделение данных: Разделение данных между несколькими узлами для распределения нагрузки на чтение и запись.
- Репликация: Создание копий данных в разных местах для обеспечения доступности и ускорения доступа.
- Кэширование: Хранение часто запрашиваемых данных в быстрых слоях памяти для снижения нагрузки на базу данных.
Слой сети
Сеть выступает в роли соединительной ткани. Если сеть не справляется, вся система замедляется. Масштабируемый дизайн сети ориентирован на пропускную способность, задержку и эффективность маршрутизации.
- Балансировка нагрузки: Распределение входящего трафика между несколькими серверами для предотвращения перегрузки.
- Доставка контента: Расположение контента ближе к пользователю для снижения задержки.
- Управление пропускной способностью: Приоритизация критического трафика для обеспечения реактивности важных служб.
Таблица: шаблоны масштабируемости и случаи использования
| Шаблон | Функция | Наилучшее применение |
|---|---|---|
| Вертикальное масштабирование | Добавление ресурсов к существующим узлам | Базы данных, требующие высокой производительности одного узла |
| Горизонтальное масштабирование | Добавление дополнительных узлов в группу | Веб-приложения и микросервисы |
| Шардинг | Разделение данных между базами данных | Высокомасштабные транзакционные данные |
| Кэширование | Хранение копий данных для быстрого доступа | Нагрузки с преобладанием чтения |
| Асинхронная обработка | Очереди задач для последующего выполнения | Фоновые задания и уведомления |
Управление данными в условиях высокого роста 💾
Данные часто являются основным ограничением при масштабировании. По мере роста объема транзакций производительность базы данных может быстро снижаться. Планирование масштабируемости данных требует перехода от традиционных реляционных моделей к более гибким архитектурам.
Реплики для чтения: Создание копий основной базы данных, которые обрабатывают запросы только на чтение. Это снижает нагрузку на основную систему и улучшает время отклика для пользователей.
Разделение базы данных (шардинг): Это включает разделение большой базы данных на более мелкие, быстрее работающие и легче управляемые части, называемые шардами. Каждый шард — это отдельная экземпляр базы данных. Это позволяет масштабировать систему за счет добавления новых шардов вместо обновления одного крупного сервера.
Архитектура, основанная на событиях: Вместо того чтобы системы опрашивали друг друга за данными, они реагируют на события. Это разделяет компоненты и позволяет каждой части системы масштабироваться независимо в зависимости от конкретной нагрузки событий.
При проектировании хранения данных архитекторы также должны учитывать политики хранения данных. Архивирование старых данных в холодное хранилище делает активную систему более легкой и быстрой. Это гарантирует, что ресурсы высокой производительности будут выделены для текущих операционных потребностей.
Рассмотрение сетевых и соединительных аспектов 🌐
Масштабируемая инфраструктура зависит от надежной сети. По мере роста количества подключенных устройств и сервисов сложность сети возрастает. Проектирование должно учитывать задержки, пропускную способность и безопасность.
Микросегментация: Разделение сети на более мелкие зоны для ограничения распространения угроз безопасности. Это также позволяет осуществлять детальный контроль трафика, обеспечивая приоритет критически важным сервисам.
Развертывание в нескольких регионах: Расположение инфраструктуры в нескольких географических регионах снижает задержку для пользователей в разных регионах. Это также обеспечивает возможности восстановления после аварий. Если один регион выходит из строя, трафик можно перенаправить в другой.
Шлюзы API: Они выступают единым входом для всех запросов клиентов. Они обрабатывают аутентификацию, ограничение скорости и маршрутизацию. Это защищает бэкенд-сервисы от перегрузки прямым трафиком.
Оптимизация пропускной способности: Сжатие передачи данных и минимизация размера полезной нагрузки снижает нагрузку на сеть. Должны использоваться эффективные протоколы, чтобы обеспечить максимальную пропускную способность при минимальных накладных расходах.
Управление и управление жизненным циклом 🛡️
Без управления масштабирование может привести к хаосу. Управление гарантирует, что изменения в инфраструктуре документируются, проверяются и утверждаются. Это поддерживает согласованность во всей организации.
- Контроль изменений: Каждое изменение в инфраструктуре должно быть отслежено. Это предотвращает отклонение конфигурации и гарантирует, что производственные среды соответствуют проектным спецификациям.
- Управление затратами: Масштабируемость часто приводит к увеличению затрат. Управление гарантирует эффективное использование ресурсов и соответствие расходов бюджетным ограничениям.
- Соответствие требованиям безопасности: Меры безопасности должны масштабироваться вместе с инфраструктурой. При добавлении новых узлов они должны автоматически наследовать политики безопасности, чтобы предотвратить уязвимости.
Управление жизненным циклом охватывает весь путь ресурса от создания до вывода из эксплуатации. Автоматизированные инструменты должны отвечать за выделение и вывод ресурсов из эксплуатации. Это снижает количество ошибок, вызванных человеком, и гарантирует, что неиспользуемые ресурсы не создают ненужных расходов.
Оценка рисков и стратегии их снижения ⚠️
Масштабирование вводит новые риски. Чем сложнее система, тем выше потенциал появления точек отказа. Превентивный подход к управлению рисками является обязательным.
- Одиночные точки отказа:Определите любой компонент, выход из строя которого приведёт к полному отказу системы. Обеспечьте избыточность для всех критически важных компонентов.
- Планирование ёмкости: Регулярно оценивайте текущее использование по сравнению с прогнозируемым ростом. Убедитесь, что ресурсы можно добавить до того, как спрос превысит ёмкость.
- Восстановление после катастрофы: Регулярно тестируйте процедуры резервного копирования и восстановления. В кризисной ситуации способность быстро восстановить сервис является жизненно важной.
- Зависимость от поставщика: Зависимость от одного поставщика может ограничить гибкость. Где возможно, используйте открытые стандарты, чтобы обеспечить переносимость и переговорные позиции.
Регулярное тестирование на стресс и нагрузку помогает выявить слабые места до того, как они станут критическими проблемами. Симулируя пиковые нагрузки, команды могут проверить, что инфраструктура работает так, как ожидается, под давлением.
Подготовка к будущему расширению 🔮
Технологическая среда быстро меняется. Архитектура, разработанная сегодня, должна быть адаптивной к требованиям завтрашнего дня. Это включает в себя постоянное информирование о новых технологиях и отраслевых тенденциях.
- Модульность: Проектируйте системы как модульные компоненты. Это позволяет обновлять или заменять отдельные части системы без влияния на всю систему.
- Взаимодействие: Убедитесь, что различные системы могут взаимодействовать с использованием стандартных протоколов. Это облегчает интеграцию с новыми инструментами и сервисами.
- Масштабируемая безопасность: Меры безопасности должны развиваться вместе с инфраструктурой. Новые угрозы требуют новых защитных мер, а архитектура должна обеспечивать бесшовные обновления.
- Непрерывное улучшение: Рассматривайте архитектуру как живой документ. Регулярные обзоры гарантируют, что дизайн остаётся согласованным с бизнес-целями и техническими реалиями.
Инвестирование в документацию и обмен знаниями гарантирует, что команда понимает архитектуру. При смене персонала институциональные знания сохраняются, что поддерживает целостность системы.
Заключительные соображения для архитекторов 🏁
Планирование архитектуры технологий для масштабируемой инфраструктуры — сложная задача, требующая балансировки противоречивых требований. Производительность, стоимость, безопасность и гибкость должны быть учтены. Используя структурированные методологии и придерживаясь проверенных принципов, организации могут создавать системы, способные выдержать испытание временем.
Путь не заканчивается с развертыванием. Для поддержания масштабируемости необходим непрерывный мониторинг и оптимизация. По мере изменения бизнес-потребностей архитектура должна развиваться вместе с ними. Это гарантирует, что технология остаётся драйвером роста, а не ограничением.
Сосредоточьтесь на основах: чистом дизайне, автоматизации и наблюдаемости. Эти краеугольные камни поддерживают устойчивую инфраструктуру, способную справляться с вызовами будущего. При тщательном планировании и дисциплинированной реализации масштабируемые системы становятся реальностью, способствующей успеху бизнеса.