











資料庫架構始於遠見。在撰寫任何程式碼之前,必須先概念化、組織並驗證資料結構。實體-關係圖(ERD)即是此結構的藍圖,將現實世界的需求轉化為視覺化模型。然而,僅有圖表本身無法儲存資料。邏輯資料結構是具體的實作,規範資訊如何被實際儲存、取得與保護。
從抽象的ERD過渡到具體的資料結構,需要精確性。這包括將實體對應至資料表、關係對應至索引鍵、屬性對應至欄位。此過程決定了整個系統的完整性與效能。理解此轉換的細節,可確保資料庫在負載下仍具穩健性,並能適應未來的需求。
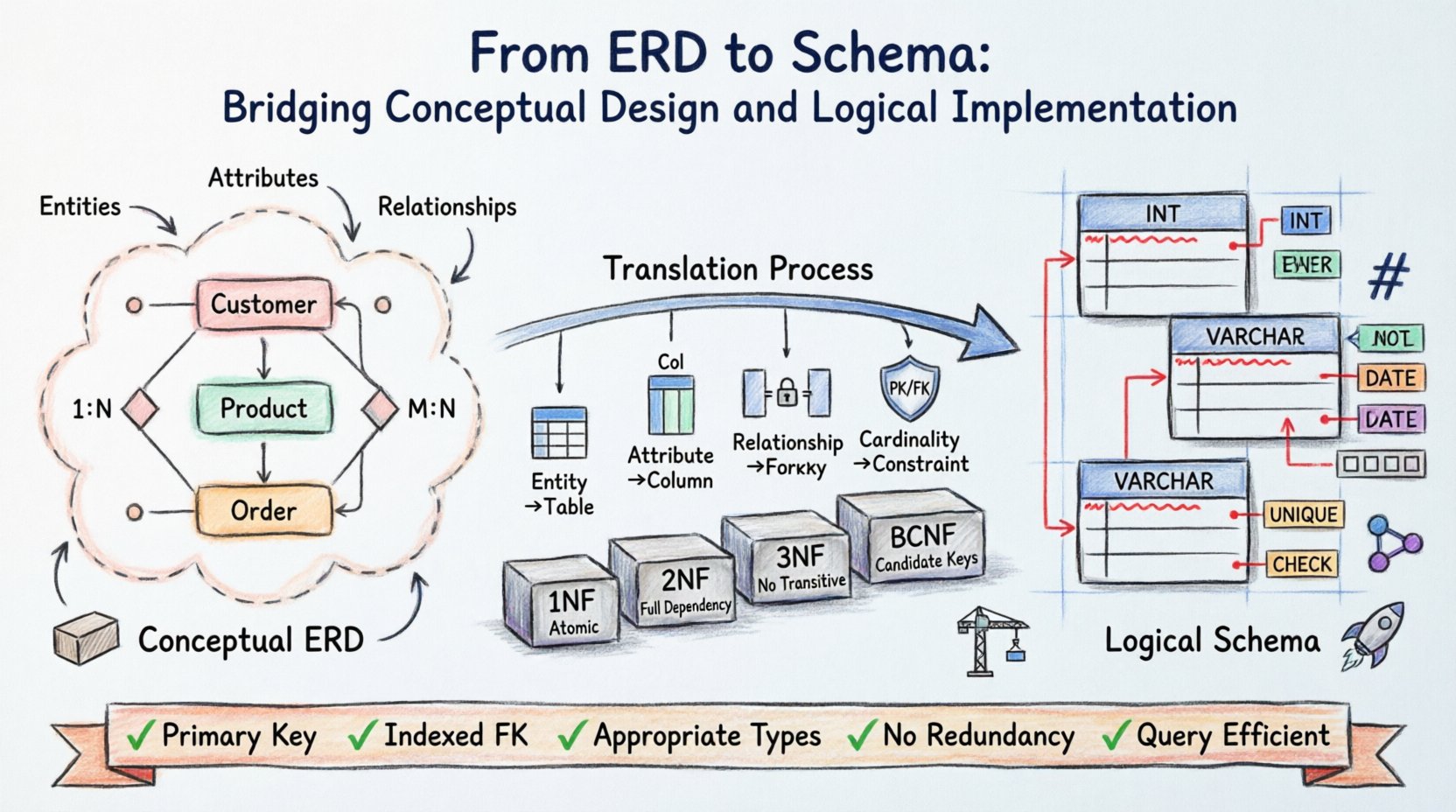
理解概念基礎 🧱
實體-關係圖運作於概念層級。它關注的是「什麼」而非「如何」。在此階段,利害關係人與架構師會識別出領域內的核心物件。
- 實體: 這些代表獨立的物件或概念,例如客戶、產品或訂單。
- 屬性: 這些定義實體的屬性,例如姓名、價格或日期。
- 關係: 這些描述實體之間的互動方式,例如客戶下訂單。
在此階段,技術限制屬於次要考量。目標是清晰明確。若概念模型含糊不清,所產生的資料結構將存在缺陷。常見錯誤包括將屬性與實體混淆,或未能正確定義基數。
基數與參與
ERD設計中最關鍵的要素之一是定義基數。這決定了實體之間的數量關係。
- 一對一(1:1): 表A中的單筆記錄僅與表B中的單筆記錄相關。
- 一對多(1:N): 表A中的單筆記錄可與表B中的多筆記錄相關。
- 多對多(M:N): 表A中的多筆記錄與表B中的多筆記錄相關。
參與限制進一步細化此模型。關係是強制性的還是可選的?若客戶必須下訂單,則參與為強制性。若客戶可無訂單存在,則為可選。這些區別直接影響邏輯資料結構中欄位的可空性。
邏輯資料結構:結構化實作 🏗️
邏輯資料結構彌補了理論與實際儲存之間的差距。雖然ERD與平台無關,但邏輯資料結構則為特定儲存機制準備資料。此層引入關於資料類型、限制條件與正規化的特定規則。
與概念模型不同,邏輯資料結構必須明確處理資料完整性。這透過主鍵、外鍵與唯一性限制來實現。這些規則可防止孤兒記錄,並確保關係始終一致。
關鍵轉換規則
將ERD中的鍵轉換為資料結構,需嚴格遵循關係理論。
- 主鍵: 每個實體都必須具備唯一識別碼。在ERD中,這通常以底線標示。在資料結構中,則轉為PRIMARY KEY限制。
- 外鍵: 關係透過外鍵來實作。多對多關係通常需要一個關聯表,並包含兩個外鍵以解決基數問題。
- 複合金鑰: 如果實體依賴多個屬性來確保唯一性,則必須在邏輯定義中將這些屬性結合起來。
將實體映射到資料表 🔄
將實體轉換為資料表的過程雖然簡單,但需要細心處理。每個實體通常對應一個資料表。然而,在複雜情境下,可能需要拆分或合併資料表。
處理專化與一般化
當實體共享共同的屬性時,它們可能被建模為子類別。例如,一個 車輛 實體可能有像 汽車 和 卡車.
在資料結構中實現此設計有兩種主要策略:
- 單一資料表繼承: 所有子類別都儲存在一個資料表中,並使用鑑別欄位區分。這可以減少連接操作,但會增加 NULL 值的數量。
- 類別資料表繼承: 每個子類別都擁有自己的資料表,並透過外鍵與父類別連結。這種方式更符合規範化,但需要更複雜的查詢。
屬性映射
ERD 中的屬性必須對應到欄位定義。並非所有屬性都能直接轉換。
- 簡單屬性: 直接對應到欄位。
- 複合屬性: 必須拆解為單獨的欄位(例如,地址需拆分為街道、城市、郵遞區號)。
- 多值屬性: 無法儲存在單一欄位中。這類屬性需要建立一個獨立的資料表,並透過外鍵連結(例如,使用者的電話號碼)。
- 衍生屬性: 這些屬性是根據其他資料計算得出的(例如,根據出生日期計算年齡)。通常會從資料結構中省略,以避免重複,除非性能優化至關重要。
規範化深入探討 📊
規範化是組織資料以減少冗餘並提升完整性的一種過程。從ERD轉換到資料結構時,設計者必須確保模型符合特定的規範形式。
第一範式(1NF)
如果一個表格包含原子值,則該表格處於第一範式(1NF)。任何欄位都不應包含清單或一組值。如果一個實體對於單一屬性具有多個值,則必須建立一個新表格。
第二範式(2NF)
2NF 要求表格處於 1NF,且不存在部分依賴。所有非鍵屬性都必須依賴於整個主鍵,而不能僅僅依賴於主鍵的一部分。這對於具有複合鍵的表格尤為重要。
第三範式(3NF)
3NF 要求不存在傳遞依賴。非鍵屬性不應依賴於另一個非鍵屬性。例如,如果城市依賴於郵遞區號,且郵遞區號依賴於客戶編號, 城市應移至另一個獨立的表格中。
博伊斯-科德範式(BCNF)
BCNF 是 3NF 的更嚴格版本。它處理表格具有多個候選鍵,且非鍵屬性依賴於這些鍵的子集的情況。
| 範式 | 要求 | 重點 |
|---|---|---|
| 1NF | 原子值 | 消除重複群組 |
| 2NF | 完全依賴 | 消除部分依賴 |
| 3NF | 無傳遞依賴 | 消除間接依賴 |
| BCNF | 候選鍵依賴 | 消除重疊鍵 |
資料類型與約束 🔒
選擇正確的資料類型對於儲存效率和查詢效能至關重要。ERD 很少指定精確的資料類型,這部分通常留待邏輯設計階段處理。
整數 vs. 數值
整數儲存整數,計算速度更快。數值或小數類型用於財務資料以保持精確度。使用整數儲存貨幣可能會導致四捨五入錯誤。
日期與時間
時間戳應區分 UTC 與本地時間。將日期儲存為字串是一種常見錯誤,會導致無法有效排序與過濾。應使用資料庫引擎提供的標準日期類型。
約束
約束在資料庫層級強制執行業務規則。
- NOT NULL:確保欄位始終包含值。
- UNIQUE:防止欄位中出現重複值。
- CHECK:根據特定條件驗證資料(例如:年齡 > 0)。
- DEFAULT:若未提供值,則提供預設值。
常見陷阱與驗證 ⚠️
即使有穩固的計畫,實作過程中仍可能出現錯誤。及早識別這些陷阱可大幅節省後續時間。
- 過度規範化:建立過多資料表會使查詢變慢且複雜。對於讀取密集型工作負載,可能需要反規範化。
- 弱鍵:使用自然鍵(如電子郵件地址)作為主要鍵具有風險。它們可能變更,並引發連鎖問題。代理鍵(自動遞增 ID)通常更安全。
- 遺漏索引:外鍵應建立索引。若無索引,表之間的連接會成為效能瓶頸。
- 循環依賴:確保資料表不會在關係中形成迴圈,對於維持參照完整性至關重要。
驗證清單
在最終確定模式之前,請逐一核對此驗證清單:
- 每個資料表是否都具有主鍵?
- 所有外鍵是否都已正確建立索引?
- 資料類型是否適合預期的資料量?
- 是否有任何重複的欄位可以刪除?
- 該模式是否能有效支援所需的查詢?
效能考量 🚀
邏輯模式不僅僅是正確性問題,也涉及速度。隨著資料量增加,結構必須能應對更高的負載。
分割
大型資料表可分割為較小且更易管理的片段。這可以水平(按資料列)或垂直(按資料欄)進行。分割可讓查詢僅存取相關的資料區段。
架構模式
如分片(sharding)等設計模式可將資料分散至多個伺服器。這需要在邏輯設計階段仔細規劃,以確保相關資料盡可能保持在一起。
最佳實務總結 ✅
建立資料庫模式是一個迭代的過程。需要在理論純粹性與實際限制之間取得平衡。
- 記錄所有內容:維持清晰的文件,將ERD元件與模式定義連結起來。
- 版本控制:將模式變更視為程式碼。使用遷移腳本來追蹤隨時間的變更。
- 定期審查:隨著業務需求的演變,模式也應隨之調整。安排定期審查,以確保符合當前需求。
- 協作:盡早讓開發人員、分析師和利害關係人參與。不同的觀點能揭示單一設計者可能忽略的邊界案例。
從實體-關係圖轉換為邏輯模式,是資料工程的骨幹。它將抽象概念轉化為可運作的系統。透過遵循正規化規則、選擇合適的資料類型,並預見效能需求,所產生的資料庫將成為應用程式的可靠基礎。
最終,模式的品質決定了系統的壽命。良好的結構設計能最小化技術負債,並促進未來的成長。專注於清晰性、完整性與可擴展性,以建立能經得起時間考驗的系統。