










设计健壮的数据库模式不仅需要列出表和列,更需要深入理解实体之间的相互关系。在实体-关系图(ERD)中,最具威力但也最复杂的概念之一就是继承。这一机制使我们能够建模现实世界中的层级结构,其中对象共享共同特征,同时也具有独特的属性。在数据库设计的语境下,这转化为超类型和子类型。🧩
当我们建模继承时,实际上是在捕捉“是一种”的关系。例如,一个车辆是一种产品,而一个汽车是一种车辆。这种层级结构允许我们在较高层级复用属性,同时在较低层级定义特定的行为或数据。理解如何在关系型数据库中实现这一点,对于数据完整性和查询性能至关重要。🗄️
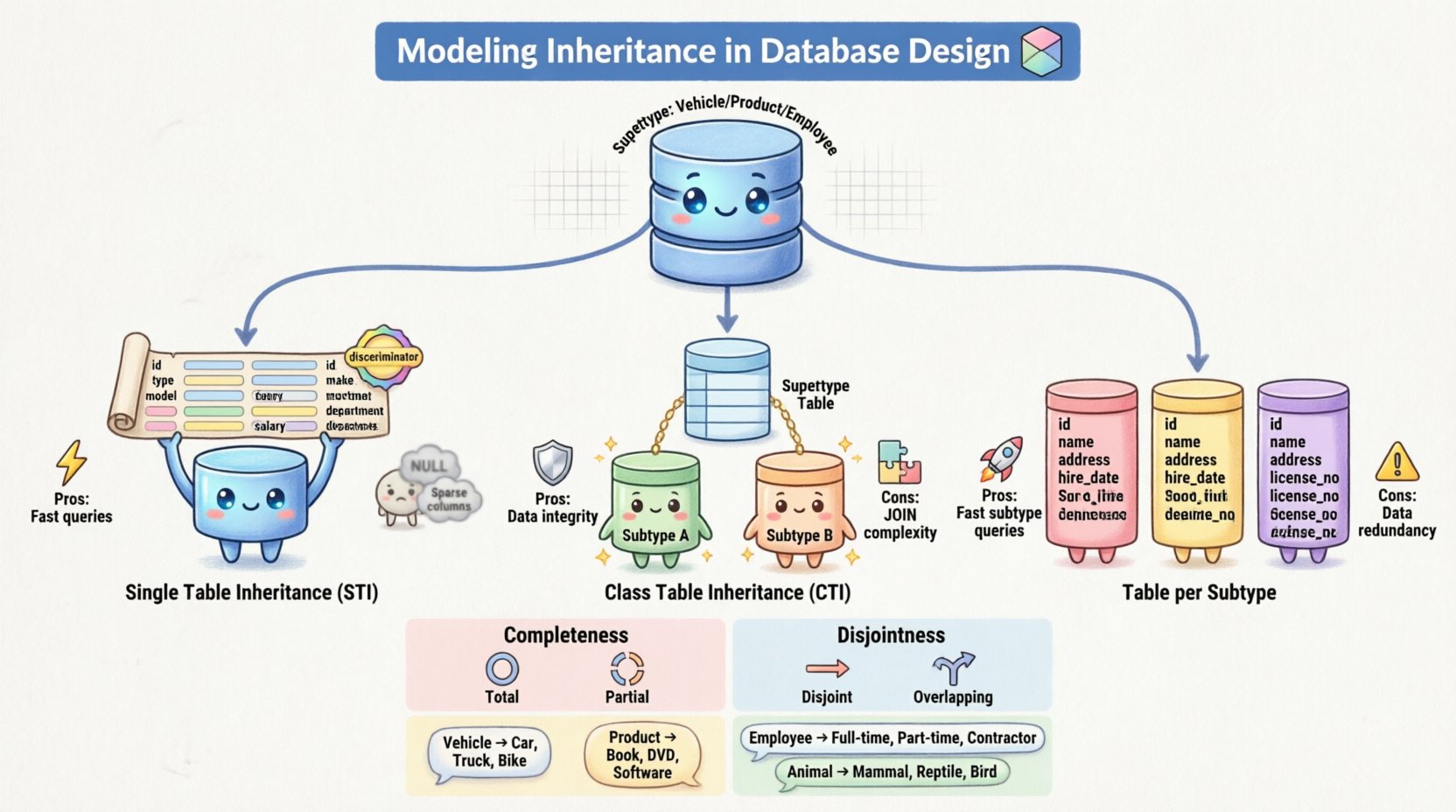
🔑 核心概念:超类型和子类型
在深入实现之前,我们必须清晰地定义术语。数据库建模中的继承不仅仅是关于代码,更关乎数据的结构化表示。
- 超类型: 这是父实体。它包含所有相关实体共有的属性,代表一般类别。例如,员工可以是一个超类型。
- 子类型: 这些是子实体。它们从超类型继承属性,但也可能拥有自己的独特属性。例如经理或开发人员.
- 实体类别:超类型有时被称为实体类别,用于将子类型归为一组。
- 区分符: 超类型中的一个特定属性,用于标识某个实例属于哪个子类型。这在物理实现中经常使用。
超类型与子类型之间的关系是严格的。子类型的每一个实例也必须是超类型的实例。然而,并非超类型的每一个实例都必须是某个特定子类型的实例。这一区别对于数据建模的准确性至关重要。✅
📊 实现策略
将逻辑ERD模型转换为物理数据库模式需要特定的映射策略。在关系系统中表示继承主要有三种主要方法。每种方法在存储、检索速度和数据完整性方面都有各自的权衡。🛠️
1. 单表继承(STI)
在此方法中,超类型和所有子类型的全部属性都被合并到一个表中。该表包含整个继承层次结构中定义的每个属性的列。为了区分属于不同子类型的行,会添加一个鉴别器列。
- 优点: 读取数据时极为高效。一个简单的
SELECT就能获取所有信息,而无需复杂的连接操作。 - 缺点: 该表可能变得非常宽,包含许多
NULL对于不适用于特定子类型的属性,会包含大量空值。如果子类型特定的约束发生变化,更新也会变得困难。
2. 类表继承(CTI)
在此方法中,超类型和每个子类型都被映射到各自独立的表中。超类型表包含公共属性和主键。每个子类型表包含独有的属性以及一个外键,用于链接回超类型的主键。
- 优点: 高度规范化。对于不适用的属性,不存在
NULL值。严格强制参照完整性。 - 缺点: 获取数据需要多次
JOIN操作,这可能会影响大型数据集上的性能。同时也会使INSERT操作变得复杂,因为数据必须写入多个表。
3. 每子类型一个表(具体表继承)
此策略为每个子类型(包括超类型)创建一个表。然而,每个子类型表都包含超类型属性的副本。没有直接链接回中心超类型表。
- 优点: 查询特定子类型非常快速,因为所有数据都在一个位置。它避免了STI的
NULL问题。 - 缺点: 数据冗余。如果超类型中的公共属性发生变化,则必须在每个子类型表中更新。这增加了数据不一致的风险。
⚖️ 继承上的约束
并非所有的继承关系都相同。我们必须定义约束,以规范实例与其类型之间的关系。这些约束确保数据保持逻辑性和一致性。📝
完整性约束
此约束决定了每个超类型实例是否必须属于一个子类型。
- 完整: 超类型中的每个实例都必须至少属于一个子类型。不存在“通用”实例。例如,每个动物必须是哺乳动物或鸟类.
- 部分: 超类型的一个实例不一定属于任何子类型。它可以作为一个通用实体存在。当层次结构用于分类而非严格分类时,这种情况很常见。
互斥性约束
此约束决定了一个实例是否可以同时属于多个子类型。
- 互斥: 一个实例只能属于一个子类型。它不能同时是经理和开发人员在该模型中同时存在。
- 重叠: 一个实例可以属于多个子类型。这允许复杂角色,例如一个员工可以担任多个职位或分类。
结合这些约束会产生四种不同的建模场景。在创建模式之前,理解哪种场景符合您的业务逻辑至关重要。🧠
| 约束类型 | 定义 | 示例场景 |
|---|---|---|
| 不相交 + 完全 | 仅一个子类型,无通用实例 | 订单状态:待处理、已发货、已送达 |
| 不相交 + 部分 | 仅一个子类型,子类型可选 | 客户:VIP 或 普通客户(有些既不是) |
| 重叠 + 完全 | 允许多个子类型,必须属于其中一个 | 用户角色:管理员和编辑(必须至少拥有一个) |
| 重叠 + 部分 | 允许多个子类型,可选 | 产品:可售、促销(可以两者兼具,也可以都不具备) |
🔍 查询与数据检索
映射策略的选择会显著影响你编写查询的方式。在规范化环境中,你通常需要遍历继承层次结构,才能获得实体的完整视图。🔍
- 检索子类型数据: 如果你需要访问特定于子类型的属性,就必须连接子类型表。这是类表继承中的标准做法。
- 检索父类型数据: 如果你需要的是通用属性,可以直接查询父类型表。
- 多态查询: 在查询所有实例(无论子类型如何)时,单表方法速度最快。然而,如果使用多张表,则必须使用
UNION操作或复杂的连接。
考虑性能影响。一个需要连接五张表来获取单条记录的查询,可能比在非规范化单表上的查询更慢。然而,非规范化的表可能会违反规范化规则,导致更新异常。平衡这些因素是模式设计的关键。⚖️
🛠️ 维护与演进
模式并非一成不变。业务需求会变化,数据库结构也必须随之调整。继承建模提供了灵活性,但在维护过程中也引入了复杂性。🔄
添加新子类型
添加新子类型通常很简单。你可以在CTI中创建新表,或在STI的鉴别列中添加新值。然而,必须确保现有查询和应用逻辑能够支持新类型。未能更新代码可能导致运行时错误。
修改父类型属性
如果向父类型添加属性,在使用CTI或每子类型一张表时,必须在每个子类型表中体现。在STI中,只需在单张表中添加一次。这使得STI在处理通用变更时更易于维护,但在处理特定变更时更难维护。
数据迁移
重构继承模型是一项重大任务。从单个表迁移到规范化结构需要在多个表之间迁移数据。此过程必须谨慎管理,以避免数据丢失或损坏。 🚧
📈 规范化与继承
继承建模与数据库规范化密切相关。规范化的目的是减少冗余并提高数据完整性。如果处理不当,继承有时会与这些目标产生冲突。
- 第一范式(1NF): 继承模型通常满足1NF,因为属性是原子的。
- 第二范式(2NF): 在STI中,如果鉴别字段不包含在主键中,表中可能包含不完全依赖于主键的属性。这需要仔细设计主键。
- 第三范式(3NF): 在CTI中,将属性分离到子类型表中通常有助于实现3NF,通过消除传递依赖。
设计超类型时,确保共用属性确实是共用的。如果某个属性仅被一个子类型使用,它很可能不应放在超类型中。这可以防止超类型变成难以查询的“上帝表”。 👁️
🎯 模式设计的最佳实践
为确保您的继承模型保持可维护性和高性能,请遵循以下指南。
- 限制层级深度: 避免过深的继承层次。通常建议的继承层级最多为三层。超过这个范围,查询和维护的复杂性将超过其带来的好处。
- 使用清晰的命名: 命名应反映层级关系。车辆, 汽车, 卡车 这是清晰的。实体1, 实体2 这不是。
- 为增长做好规划: 预见未来的子类型。如果你预计会有许多新的子类型,单个表可能会变得难以管理。如果你预计子类型很少,CTI可能更合适。
- 记录约束条件: 清晰地记录不相交性和完备性约束。未来的开发人员需要知道一个实例是否可以属于多个子类型。
- 索引策略: 如果使用CTI,应在子类型表的外键列上建立索引以加快连接操作。如果使用STI,应为区分符列建立索引以支持过滤。
🧪 现实世界场景
让我们看看这如何应用于实际的数据建模挑战。
场景1:人力资源
在人力资源系统中,你有人员作为超类型。子类型包括员工, 合同工,以及实习生。每个子类型都有其独特数据:员工有薪资编号,合同工有计费费率。一个人员表保存姓名和地址。这非常适合类表继承模型。
场景2:库存管理
考虑一个产品目录。产品是超类型。子类型包括电子产品, 家具,以及服装. 电子产品具有保修期. 服装具有尺寸和颜色。如果您查询所有具有保修期的产品,必须连接电子产品表。这突显了查询性能的权衡。🔍
场景3:金融交易
在银行系统中,账户是超类型。子类型包括储蓄, 支票,以及贷款。一个储蓄账户具有利率。一个贷款账户有到期日。此场景通常采用单表方法,以简化所有账户类型的余额计算。
🚀 性能考虑
性能通常是选择映射策略时的决定性因素。大型数据集会放大不同方法之间的差异。
- 写入性能: STI 在插入时最快,因为它只需要一条
INSERT语句。CTI 需要多条插入语句,这会增加事务开销。 - 读取性能: 如果您经常查询特定子类型,CTI 比 STI 更快,因为您只需读取相关列。如果您查询所有实例,STI 更快。
- 存储: STI 由于
NULL填充。CTI 由于存在重复的主键和外键而占用更多存储空间,但因不存在NULL填充而占用更少。
对应用程序进行性能分析至关重要。理论性能并不总能匹配实际使用模式。只有通过使用真实数据量进行测试,才能确认您的选择。📊
🛡️ 数据完整性和验证
在继承模型中保持数据完整性需要严格的验证规则。您必须确保输入子类型表中的数据符合超类型约束。
- 外键约束: 确保子类型行始终链接到有效的超类型行。这可以防止出现孤立数据。
- 检查约束: 使用检查约束来强制执行业务规则。例如,确保 利率 在 储蓄 子类型中永远不会为负数。
- 触发器: 在某些复杂场景中,数据库触发器可能需要在更新期间保持表间的一致性。
自动化测试应涵盖继承场景。验证创建新的子类型实例是否正确更新了超类型。验证删除超类型实例时,是否按预期行为正确级联到子类型。🧪
📝 最终考虑事项
建模继承是在灵活性和复杂性之间的权衡。没有单一的“正确”方式。最佳选择取决于您的特定数据访问模式、业务规则和性能要求。
- 从对领域的清晰理解开始。在担心表之前,先映射实体。
- 选择与您最频繁查询相匹配的映射策略。
- 记录您的决策。未来的维护将依赖于此文档。
- 定期审查模式。随着业务的发展,模型可能需要更改。
通过精心设计超类型和子类型,您可以创建一个稳健、可扩展且易于理解的数据库。这一基础为依赖它的应用程序提供支持,确保长期的稳定性和效率。 🏗️