











Der Aufbau eines Datenbanksystems ist vergleichbar mit dem Bau des Fundaments eines Hochhauses. Wenn der Bauplan fehlerhaft ist, wird die Struktur letztendlich unter Druck zerbrechen. Ein Entity-Relationship-Diagramm (ERD) ist genau dieser Bauplan. Er definiert, wie Daten miteinander verbunden sind, fließen und innerhalb Ihrer Anwendung persistieren. Wenn Ihre Benutzerbasis wächst und die Datenmenge explodiert, wird ein statisches Design oft zur Engstelle. Um Langlebigkeit zu gewährleisten, müssen Sie skalierbare ERD-Designprinzipien von Anfang an anwenden. Dieser Leitfaden untersucht die technischen Strategien, die erforderlich sind, um Systeme zu schaffen, die Bestand haben.
Verständnis der Grundlagen der Datenmodellierung 🧱
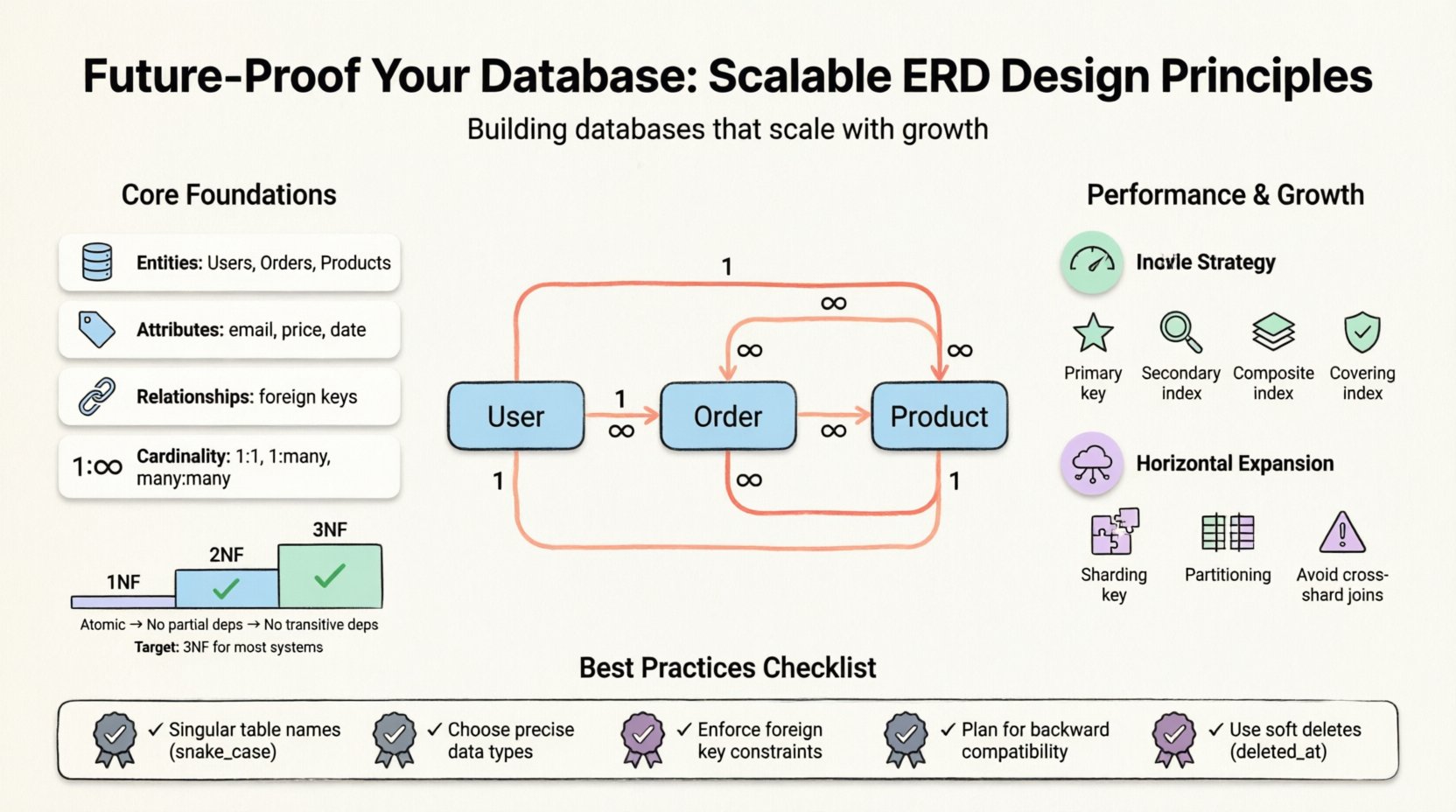
Bevor Sie spezifische Strategien ergründen, ist es unerlässlich zu verstehen, was ein ERD darstellt. Er visualisiert die logische Struktur einer Datenbank. Er ordnet Entitäten (Tabellen), Attribute (Spalten) und Beziehungen (Schlüssel) zu. Ein gut gestaltetes Modell findet die Balance zwischen Datenintegrität und Leistung. Allerdings variiert die „beste Praxis“ je nach Arbeitslast. Eine an Lesevorgängen orientierte Anwendung erfordert eine andere Optimierung als ein schreibintensives Transaktionssystem.
Zu den zentralen Komponenten gehören:
- Entitäten: Die primären Objekte, wie Benutzer, Bestellungen oder Produkte.
- Attribute: Die Eigenschaften, die eine Entität definieren, wie E-Mail-Adressen oder Preise.
- Beziehungen: Wie Entitäten miteinander interagieren, oft definiert durch Fremdschlüssel.
- Kardinalität: Die numerische Beziehung zwischen Entitäten (eins-zu-eins, eins-zu-viele, viele-zu-viele).
Normalisierung: Das Gleichgewicht zwischen Redundanz und Geschwindigkeit ⚖️
Die Normalisierung ist der Prozess der Datenorganisation, um Redundanz zu reduzieren und die Integrität zu verbessern. Obwohl sie oft als strikte Regel behandelt wird, ist sie eine Abwägung. Hohe Normalisierung minimiert Anomalien, kann aber die Komplexität von Abfragen durch Joins erhöhen. Geringe Normalisierung (Denormalisierung) beschleunigt Lesevorgänge, birgt aber das Risiko von Dateninkonsistenzen.
Stufen der Normalisierung
Das Verständnis der Standardformen hilft Ihnen zu entscheiden, wo Sie aufhören sollen. Jede Form behebt spezifische Datenanomalien.
- Erste Normalform (1NF): Stellt Atomarität sicher. Jede Spalte muss unteilbare Werte enthalten. Keine sich wiederholenden Gruppen oder Arrays innerhalb einer einzigen Zelle.
- Zweite Normalform (2NF): Baut auf 1NF auf. Alle nichtschlüsselbasierten Attribute müssen sich auf den gesamten Primärschlüssel beziehen, nicht nur auf einen Teil davon. Dadurch werden partielle Abhängigkeiten eliminiert.
- Dritte Normalform (3NF): Baut auf 2NF auf. Nichtschlüsselbasierte Attribute dürfen sich nicht auf andere nichtschlüsselbasierte Attribute beziehen. Dadurch werden transitive Abhängigkeiten entfernt.
- Boyce-Codd-Normalform (BCNF): Eine strengere Version der 3NF. Sie behandelt Fälle, in denen Determinanten keine Kandidatenschlüssel sind.
Für die meisten skalierbaren Systeme ist die Erreichung der 3NF das übliche Ziel. Weitere Stufen bringen oft abnehmende Erträge und erhöhen die Wartungskosten. Für datenanalyseintensive Systeme ist jedoch eine kontrollierte Rückkehr zur Denormalisierung üblich.
Tabelle mit Normalisierungs-Abwägungen
| Normalisierungsstufe | Hauptvorteil | Hauptnachteil |
|---|---|---|
| 1NF | Atomare DatenSpeicherung | Keine |
| 2NF | Beseitigt partielle Abhängigkeiten | Mehr Joins erforderlich |
| 3NF | Beseitigt transitive Abhängigkeiten | Erhöhte Joinkomplexität |
| Entnormalisiert | Schnellere Leseabfragen | Datenspeicherung und Aktualisierungsanomalien |
Schema-Design für Wachstum und Flexibilität 📈
Das Gestalten für die Gegenwart reicht nicht aus. Sie müssen die zukünftige Entwicklung des Schemas vorhersehen. Starre Strukturen brechen zusammen, wenn sich die Geschäftslogik ändert. Flexible Gestaltung ermöglicht eine Erweiterung, ohne eine vollständige Systemmigration erforderlich zu machen.
1. Namenskonventionen und Standards
Konsistenz ist für die Wartbarkeit entscheidend. Ein chaotisches Namensschema führt zu Verwirrung und Fehlern. Legen Sie früh einen Standard fest und setzen Sie ihn im gesamten Team durch.
- Verwenden Sie Singular-Bezeichnungen:Tabellen sollten eine einzelne Entität darstellen (z. B.
Benutzer, nichtBenutzer). - Konsistente Trennzeichen:Verwenden Sie snake_case für Tabellennamen und Spalten, um Kompatibilität über verschiedene Betriebssysteme und Werkzeuge hinweg zu gewährleisten.
- Präfixe zur Spezifizierung:Verwenden Sie Präfixe wie
fk_für Fremdschlüssel oderidx_für Indizes, um ihren Zweck deutlich zu machen. - Vermeide reservierte Wörter: Verwende niemals Schlüsselwörter wie
order,group, oderselectals Spaltennamen.
2. Datentypen und Genauigkeit
Die Auswahl des richtigen Datentyps beeinflusst Speicherplatz und Abfragegeschwindigkeit. Zu generische Typen verschwenden Speicherplatz und verlangsamen die Verarbeitung.
- Ganze Zahlen: Verwende
TINYINTfür Flags (0-1) oder kleine Zählungen. VerwendeBIGINTnur, wenn du eine massive Skalierung erwarten musst. - Zeichenketten: Vermeide
TEXTfür kurze Werte. VerwendeVARCHARmit einer bestimmten Länge, um Speicherplatz zu sparen und Indizierung zu ermöglichen. - Datumsangaben: Verwende
TIMESTAMPfür bestimmte Zeitpunkte undDATEnur für Kalenderdaten. Speichere immer in UTC, um Verwirrung durch Zeitzone zu vermeiden. - Dezimalzahlen: Für Finanzdaten verwende Festkomma-Dezimalzahlen anstelle von Gleitkommazahlen, um Rundungsfehler zu vermeiden.
Beziehungen und Kardinalitätsverwaltung 🔗
Wie Entitäten miteinander verbunden sind, bestimmt die Integrität Ihrer Daten. Falsch verwaltete Beziehungen führen zu verwaisten Datensätzen und Datenverlust.
1. Fremdschlüsselbeschränkungen
Fremdschlüssel gewährleisten die Referenzintegrität. Sie stellen sicher, dass ein Datensatz in einer Tabelle keinen Verweis auf einen nicht existierenden Datensatz in einer anderen Tabelle enthält. Obwohl einige Entwickler diese aus Leistungsgründen deaktivieren, verarbeiten moderne Datenbank-Engines sie effizient. Sich auf Überprüfungen auf Anwendungsebene zu verlassen, ist fehleranfällig.
2. Behandlung von Many-to-Many-Beziehungen
Eine Many-to-Many-Beziehung (z. B. Schüler und Kurse) kann nicht direkt in zwei Tabellen dargestellt werden. Sie erfordert eine Verbindungstabelle (assoziative Entität).
- Erstellen Sie eine neue Tabelle, die die Primärschlüssel beider zugehöriger Tabellen enthält.
- Fügen Sie einen zusammengesetzten Primärschlüssel hinzu, der aus beiden Fremdschlüsseln besteht.
- Verwenden Sie diese Tabelle, um zusätzliche Attribute spezifisch für die Beziehung zu speichern, wie z. B. Einschreibedaten.
3. Optionale vs. obligatorische Beziehungen
Definieren Sie klar, ob eine Beziehung erforderlich ist. Ein NULLWert in einer Fremdschlüsselspalte zeigt eine optionale Beziehung an. Diese Entscheidung beeinflusst die Validierungslogik auf der Anwendungsebene.
Indizierungsstrategien für Leseleistung 🏎️
Indizes sind der primäre Mechanismus zur Beschleunigung der Datenabrufung. Sie sind jedoch nicht kostenlos. Jeder Index verbraucht Speicherplatz und verlangsamt Schreibvorgänge (Einfügungen, Aktualisierungen, Löschungen).
1. Primäre Indizes
Jede Tabelle benötigt einen Primärschlüssel. Dieser ist oft gruppiert, was bedeutet, dass die physischen Daten in der Reihenfolge des Schlüssels gespeichert werden. Wählen Sie einen Schlüssel, der stabil ist und nie aktualisiert wird. Sogenannte Ersatzschlüssel (auto-inkrementierende Ganzzahlen) sind oft besser als natürliche Schlüssel (wie E-Mail-Adressen) hinsichtlich der Leistung.
2. Sekundäre Indizes
Verwenden Sie sekundäre Indizes, um Abfragen zu optimieren, die auf nicht-primären Spalten filtern oder sortieren. Häufige Szenarien sind:
- Suche nach E-Mail-Adresse.
- Filtern nach Status oder Kategorie.
- Sortieren der Ergebnisse nach Datum.
3. Zusammengesetzte Indizes
Wenn nach mehreren Spalten abgefragt wird, kann ein zusammengesetzter Index effizienter sein als getrennte Einzelspaltenindizes. Die Reihenfolge der Spalten im Index ist wichtig. Platzieren Sie die selektivste Spalte zuerst.
4. Abdeckende Indizes
Ein abdeckender Index enthält alle Spalten, die benötigt werden, um eine Abfrage zu erfüllen. Dadurch kann die Datenbank die Daten direkt aus dem Index abrufen, ohne die Haupttabelle zugreifen zu müssen, was die I/O-Operationen erheblich reduziert.
Entwurf für horizontales Skalieren 🌐
Vertikales Skalieren (Hinzufügen von Leistung zu einem einzelnen Server) hat Grenzen. Letztendlich müssen Sie die Daten auf mehrere Knoten verteilen. Das ERD-Design muss dieser Realität Rechnung tragen.
1. Sharding-Schlüssel
Sharding beinhaltet die Aufteilung von Daten über mehrere Datenbanken. Die Wahl des Sharding-Schlüssels ist entscheidend. Er sollte häufig in Abfragen verwendet werden, um Datenlokalität zu gewährleisten. Wenn Sie sharding nach “benutzer_id, können Sie leicht alle Daten für diesen Benutzer auf einem einzigen Knoten abfragen.
- Gute Sharding-Schlüssel: Hohe Kardinalität, häufig in Abfragen verwendet.
- Schlechte Sharding-Schlüssel: Geringe Kardinalität (z. B.
land_code) oder selten verwendet.
2. Vermeidung von Join-Vorgängen über Shard-Grenzen hinweg
Joins über verschiedene Shards hinweg sind kostspielig und komplex. Gestalten Sie Ihr Schema so, dass der Bedarf an solchen Joins minimiert wird. Wenn Sie Daten aus zwei Entitäten benötigen, die sich möglicherweise auf unterschiedlichen Shards befinden, überlegen Sie, die Daten zu denormalisieren. Speichern Sie die erforderlichen Fremdschlüsseldaten direkt in der Tabelle, um den Join zu vermeiden.
3. Partitionierung
Die Partitionierung teilt eine große Tabelle in kleinere, überschaubare Teile auf. Dies kann nach Bereich (Datumsbereiche), Liste (Kategorien) oder Hash erfolgen. Sie verbessert die Wartbarkeit und die Abfrageleistung, ohne die Anwendungslogik signifikant zu verändern.
Schema-Evolution und Migration 🔄
Anforderungen ändern sich. Neue Funktionen erfordern neue Spalten. Alte Funktionen werden abgeschaltet. Ein robustes ERD ermöglicht Änderungen, ohne bestehende Funktionalität zu stören.
1. Rückwärtskompatibilität
Beim Hinzufügen neuer Funktionen stellen Sie sicher, dass alte Clients weiterhin funktionieren. Fügen Sie neue Spalten zunächst als nullable hinzu. Füllen Sie sie schrittweise auf. Entfernen Sie Spalten nicht sofort; markieren Sie sie als veraltet und behalten Sie sie während eines Migrationszeitraums bei.
2. Versionsverwaltung von Datenmodellen
Verfolgen Sie die Schema-Versionen. Dadurch können Sie Änderungen rückgängig machen, falls eine Migration zu kritischen Fehlern führt. Verwenden Sie idempotente Migrations-Skripte, die mehrfach ausgeführt werden können, ohne Fehler zu verursachen.
3. Behandlung von Datenmigrationen
Das Verschieben großer Datenmengen erfordert sorgfältige Planung. Große Sperrungen können Produktionsverkehr blockieren. Führen Sie Migrationen während Zeiten geringen Verkehrs durch oder verwenden Sie gegebenenfalls Blue-Green-Bereitstellungstrategien.
Häufige Fehler, die vermieden werden sollten ⚠️
Selbst erfahrene Architekten machen Fehler. Die Aufmerksamkeit für häufige Fehler hilft Ihnen, sie zu umgehen.
- Überdimensionierung: Gestaltung für eine Skalierung, die Sie noch nicht haben. Wenn Sie beginnen, halten Sie es einfach. Komplexität erhöht Kosten und Risiken.
- Ignorieren von Weichen Löschungen: Löschen Sie sensible Datensätze niemals sofort dauerhaft. Verwenden Sie stattdessen ein
gelöscht_amZeitstempel. Dadurch bleiben Audit-Protokolle erhalten und eine Wiederherstellung ist möglich. - Namenskonflikte: Die Verwendung desselben Namens für eine Tabelle und eine Spalte erzeugt Mehrdeutigkeit. Halten Sie sich an die Regel der einzelnen Tabelle.
- Fehlende Einschränkungen:Die alleinige Abhängigkeit von Anwendungslogik zur Durchsetzung von Geschäftsregeln führt zu Datenkorruption. Setzen Sie Einschränkungen auf Datenbankebene durch.
- Ignorieren der Sicherheit:Das Design muss Felder für die Zugriffssteuerung enthalten. Stellen Sie sicher, dass die rollenbasierte Zugriffssteuerung in der Entwurfsphase des Schemas berücksichtigt wird.
Abschließende Überlegungen zur Langlebigkeit 🏁
Die Erstellung einer skalierbaren Datenbank ist ein fortlaufender Prozess. Er erfordert Überwachung, Analyse und Anpassung. Kein Entwurf ist beim Start perfekt. Das Ziel ist es, eine Grundlage zu schaffen, die leicht zu ändern ist.
Führen Sie regelmäßig Audits Ihrer Abfragen durch. Identifizieren Sie langsame Operationen und optimieren Sie das zugrundeliegende Schema. Verwenden Sie Profiling-Tools, um zu verstehen, wie auf Ihre Daten zugegriffen wird. Diese Rückkopplungsschleife stellt sicher, dass Ihre Architektur auch bei wachsenden Daten effizient bleibt.
Denken Sie daran, dass die Technologie sich weiterentwickelt. Neue Speicher-Engines und Abfragesprachen entstehen. Ein flexibles Schema passt sich diesen Veränderungen besser an als ein starres. Konzentrieren Sie sich auf die zentralen Beziehungen und die Datenintegrität. Diese bleiben auch bei sich ändernden Werkzeugen konstant.
Durch die Einhaltung dieser Prinzipien bauen Sie Systeme auf, die widerstandsfähig sind. Sie bewältigen das Wachstum reibungslos und behalten ihre Leistungsfähigkeit unter Last. Das ist das Wesen der Zukunftssicherung Ihrer Datenbankinfrastruktur.