











Der Aufbau eines robusten Online-Shops erfordert mehr als nur eine Frontend-Oberfläche. Die Grundlage jedes erfolgreichen digitalen Marktplatzes liegt in seiner Datenarchitektur. Ein Entity-Relationship-Diagramm (ERD) dient als Bauplan dafür, wie Informationen gespeichert, miteinander verknüpft und abgerufen werden. Beim Entwerfen für Skalierbarkeit steigt die Komplexität erheblich. Sie müssen Integrität der Daten mit Leistungsfähigkeit abwägen, um sicherzustellen, dass jede Transaktion auch bei hoher Last reibungslos verarbeitet wird.
Diese Anleitung untersucht die entscheidenden Komponenten des E-Commerce-Datenbankdesigns. Wir werden die zentralen Entitäten, ihre Beziehungen und die Muster untersuchen, die erforderlich sind, um Hochvolumen-Verkehr zu unterstützen. Indem Sie diese strukturellen Prinzipien befolgen, können Sie ein System aufbauen, das stabil bleibt, während sich Ihre Kundenbasis vergrößert. Der Fokus liegt auf logischem Design, Normalisierung und Strategien, die Engpässe bereits vor ihrem Auftreten verhindern.
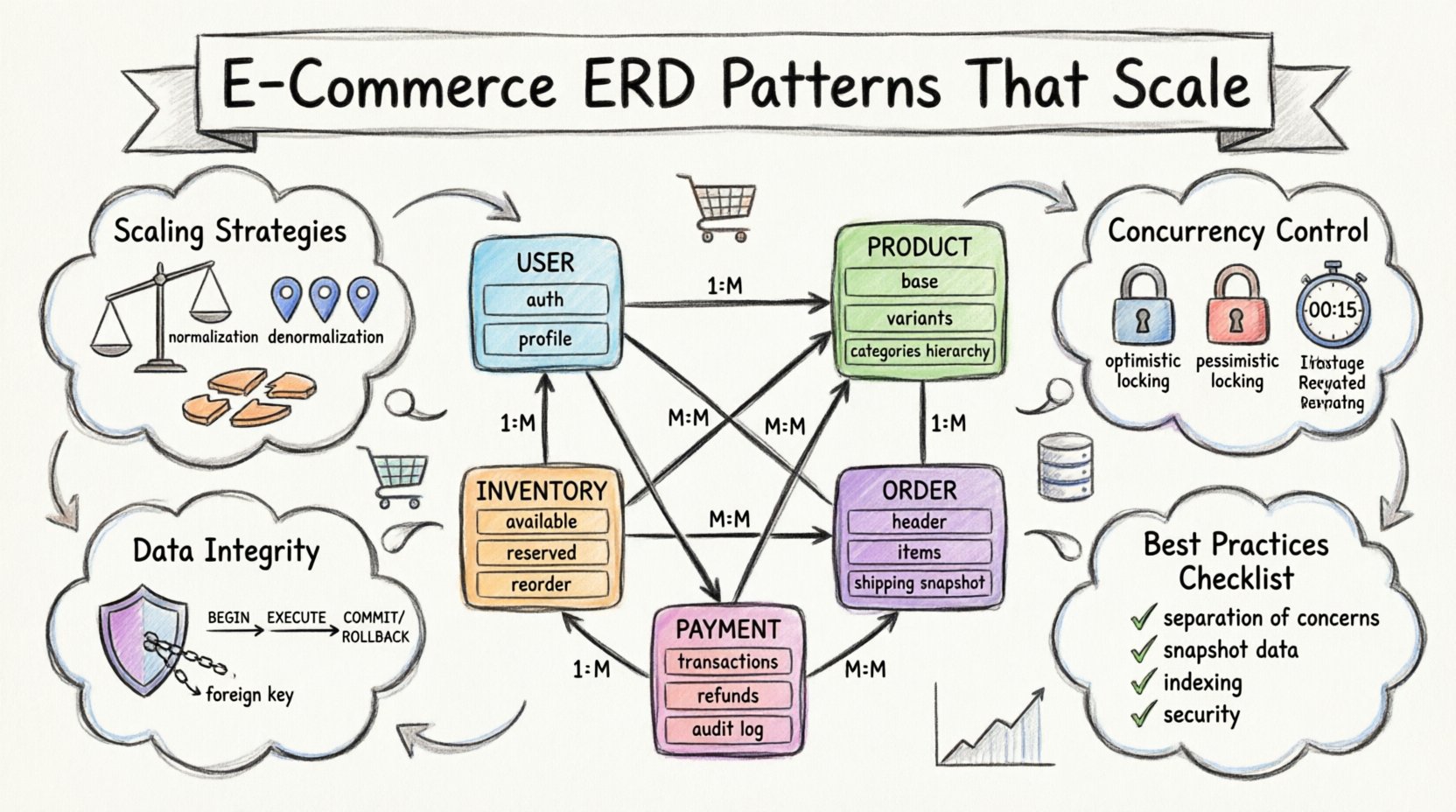
Grundlegende Entitäten und zentrale Beziehungen 🏗️
Jede E-Commerce-Plattform beginnt mit den grundlegenden Datenpunkten, die das Geschäft definieren. Dazu gehören die Identität der Kunden, was sie kaufen und wie Artikel kategorisiert werden. Die Gestaltung dieser zentralen Tabellen bestimmt die Flexibilität des gesamten Systems.
1. Die Benutzer-Entität
Die Benutzertabelle ist der Einstiegspunkt für die Authentifizierung und Profilverwaltung. Die Trennung von Authentifizierungsdaten und Benutzerprofilinformationen ist jedoch ein verbreiteter Ansatz. Diese Trennung ermöglicht Sicherheitsupdates, ohne die umfassende Benutzerdatenstruktur zu stören.
- Authentifizierungsdaten:Speichert Anmeldedaten, Sitzungstoken und Kontostatus. Diese Daten erfordern hohe Sicherheit und minimale Offenlegung.
- Profil-Daten:Enthält Namen, Kontaktdaten und Versandpräferenzen. Diese Daten werden häufiger aktualisiert.
- Beziehungen:Zwischen Benutzern und ihrer Bestellhistorie besteht eine ein-zu-viele-Beziehung. Jeder Benutzer kann mehrere Bestellungen haben, aber eine Bestellung gehört genau einem Benutzer.
Es ist wichtig, Datenschutzvorschriften in diesem Stadium zu berücksichtigen. Die Speicherung personenbezogener Daten (PII) erfordert spezifische Behandlung. Verschlüsselung im Ruhezustand und strenge Zugriffssteuerungen sind Standardpraktiken für diese Entität.
2. Das Produktkatalog
Die Produktverwaltung ist oft der komplexeste Teil eines E-Commerce-Schemas. Ein einzelnes physisches Produkt kann in mehreren Varianten existieren, beispielsweise in verschiedenen Größen oder Farben. Dies erfordert eine flexible Struktur, die keine ständigen Schemaänderungen erfordert.
- Tabelle für Produktbasis:Speichert allgemeine Informationen wie Titel, Beschreibung und Grundpreis.
- Tabelle für Varianten:Speichert spezifische Attribute wie SKU, Farbe, Größe und individuelle Preise.
- Tabelle für Kategorien:Definiert die Hierarchie. Kategorien können verschachtelt sein, was eine selbstbezügliche Beziehung oder eine Pfad-Enumeration erfordert.
Hier wird oft auf eine Denormalisierung zurückgegriffen. Während die Normalisierung Redundanz reduziert, erfordert das Lesen von Daten für eine Produktliste das Verknüpfen mehrerer Tabellen. Bei hohem Verkehr kann das Cachen der verknüpften Daten oder die Denormalisierung bestimmter Felder die Abfragegeschwindigkeit verbessern.
3. Bestands- und Lagerverwaltung
Die Verfolgung von Lagerbeständen ist entscheidend, um Überverkäufe zu verhindern. Die Bestandstabelle muss direkt mit Produktvarianten verknüpft sein. Sie sollte die aktuell verfügbare Menge, die reservierte Menge und die Gesamtkapazität speichern.
- Verfügbarer Bestand:Die Anzahl an Artikeln, die sofort gekauft werden können.
- Reservierter Bestand:Artikel, die während des Zahlungsvorgangs im Warenkorb eines Kunden reserviert sind.
- Nachbestellpunkt: Eine Schwelle, die Warnungen für die Nachbestellung auslöst.
Concurrentität ist hier eine große Herausforderung. Wenn zwei Benutzer gleichzeitig versuchen, das letzte Produkt zu kaufen, muss das System sicherstellen, dass beide nicht erfolgreich sind. Dies erfordert in der Regel Datenbanktransaktionen, die während des Aktualisierungsprozesses die spezifische Bestandszeile sperren.
Transaktionsarchitektur und Bestellverarbeitung 🛒
Der Bestelllebenszyklus ist das Herzstück der Plattform. Er stellt die Wertbewegung vom Kunden zum Händler dar. Das Datenbankdesign muss die Zustandsänderungen von der Warenkorbphase bis zur Lieferung unterstützen.
Bestellentitätsstruktur
Eine Bestellaufzeichnung ist ein Schnappschuss der Transaktion zu einem bestimmten Zeitpunkt. Sie sollte nicht einfach auf den aktuellen Produktpreis verweisen. Wenn sich der Preis nach der Bestellung ändert, muss die historische Aufzeichnung genau bleiben.
- Bestellkopf: Enthält die Bestellnummer, Benutzer-ID, Gesamtbetrag, Steuer, Versandkosten und Bestellstatus.
- Bestellpositionen: Eine Verbindungstabelle, die Bestellungen mit Produkten verknüpft. Diese Tabelle erfasst die spezifische Variante, Menge und den Preis zum Zeitpunkt des Kaufs.
- Versandadresse: Die Speicherung der Adresse zum Zeitpunkt der Bestellung ist sicherer als die Verknüpfung mit dem aktuellen Adressprofil des Benutzers.
Statusverwaltung
Bestellungen durchlaufen verschiedene Zustände. Ein gut gestalteter Statusfeld ermöglicht es dem System, den Fortschritt zu verfolgen, ohne komplexe Verknüpfungen zu benötigen. Häufige Status sind:
- Ausstehend: Bestellung erstellt, aber noch nicht bezahlt.
- Bezahlt: Zahlung bestätigt.
- In Bearbeitung: Bestand zugeordnet und wird vorbereitet.
- Versandt: Artikel versandt mit Sendungsverfolgung.
- Zugestellt: Kunde hat den Artikel erhalten.
- Rückerstattet: Geld wurde dem Kunden zurückerstattet.
Die Verwendung eines aufgezählten Typs für den Status gewährleistet Datenkonsistenz. Er verhindert Tippfehler, die Automatisierungsskripte stören könnten, die auf bestimmte Statuswerte angewiesen sind.
Zahlungs- und Finanzdaten 💳
Finanzdaten erfordern die höchste Genauigkeit. Man kann sich bei Geldtransaktionen nicht allein auf die Standardanwendungslogik verlassen. Die Datenbank muss die Finanztransaktion als eigenständiges Ereignis erfassen.
- Zahlungstransaktionen: Jeder Zahlungsversuch sollte eine Aufzeichnung erzeugen. Dazu gehören die Gateway-Antwort, die verwendete Methode und das Endergebnis.
- Rückerstattungen: Eine Rückerstattung ist eine separate Transaktion, die mit der ursprünglichen Zahlung verknüpft ist. Sie sollte die ursprüngliche Aufzeichnung nicht einfach auf null setzen.
- Steuerkalkulationen: Steuersätze variieren je nach Standort. Die Speicherung des angewendeten Steuerbetrags pro Bestellposition gewährleistet die Nachvollziehbarkeit.
Auditsicherung ist hier unerlässlich. Jede Änderung an einer Finanzaufzeichnung sollte mit einem Zeitstempel und der Benutzer-ID, die die Aktion durchführt, protokolliert werden. Dies bietet eine Spur für Streitbeilegung und interne Prüfungen.
Skalierungsstrategien für hohe Volumina 📈
Mit wachsender Traffic-Last wird die Datenbank zu einer Engstelle. Die Standard-Skalierung beinhaltet vertikale Skalierung (Hinzufügen von Leistung zu einem einzelnen Server), hat aber Grenzen. Horizontale Skalierung (Hinzufügen weiterer Server) erfordert eine sorgfältige Planung der Datenverteilung.
1. Normalisierung vs. Denormalisierung
Die Normalisierung reduziert Daten-Duplikate. Sie ist der Standard für die Transaktionsintegrität. Allerdings können komplexe Abfragen, die viele Tabellen verknüpfen, mit steigendem Datenvolumen langsamer werden.
| Strategie | Vorteil | Nachteil |
|---|---|---|
| Normalisierung | Datensicherheit, geringerer Speicherbedarf | Komplexe Abfragen, langsamere Lesevorgänge |
| Denormalisierung | Schnellere Lesevorgänge, einfachere Abfragen | Datenduplikate, komplexere Aktualisierungen |
Im E-Commerce ist oft ein hybrider Ansatz am besten. Halten Sie die zentralen transaktionalen Tabellen normalisiert, um die Integrität zu gewährleisten. Erstellen Sie denormalisierte Ansichten oder separate Tabellen für Berichterstattung und Suche. Dadurch ist eine schnelle Produktansicht möglich, ohne die Genauigkeit der Auftragsverarbeitung zu beeinträchtigen.
2. Indizierungsstrategien
Indizes sind entscheidend für die Leistung. Sie ermöglichen es der Datenbank, Zeilen zu finden, ohne die gesamte Tabelle zu durchsuchen. Allerdings verlangsamen zu viele Indizes Schreibvorgänge.
- Primärschlüssel: Immer indiziert. Wird für direkte Abfragen anhand der ID verwendet.
- Fremdschlüssel: Häufig indiziert, um Joins zwischen verwandten Tabellen zu beschleunigen.
- Komposite Indizes: Nützlich für Abfragen, die nach mehreren Spalten filtern, wie z. B. Status und Datum.
- Volltextindizes: Unverzichtbar für die Produktsuchfunktion.
Überprüfen Sie regelmäßig die Abfrageausführungspläne. Wenn eine Abfrage keinen Index verwendet, könnte die Datenbank eine vollständige Tabellenabfrage durchführen, was die Leistung beeinträchtigt, je größer die Datensammlung wird.
3. Partitionierung und Sharding
Wenn eine einzelne Tabelle zu groß wird, teilt die Partitionierung sie in kleinere, handhabbare Teile auf. Dies erfolgt oft nach Datum oder ID-Bereich.
- Bereichs-Partitionierung: Aufteilung der Aufträge nach Jahr oder Monat. Dadurch bleibt aktuelle Daten auf schnellerem Speicher, während alte Daten archiviert werden.
- Hash-Partitionierung: Verteilung der Daten über mehrere Server basierend auf einem Hash des ID-Werts. Dadurch wird die Last gleichmäßig verteilt.
Sharding geht noch einen Schritt weiter, indem die Daten über mehrere physische Server verteilt werden. Dazu muss die Anwendung wissen, welcher Shard die Daten enthält. Es handelt sich um eine komplexe architektonische Entscheidung, die am besten nach Erschöpfung der vertikalen Skalierung umgesetzt wird.
Datenintegrität und Einschränkungen 🔒
Relationale Datenbanken bieten leistungsstarke Einschränkungen zur Aufrechterhaltung der Datenqualität. Die Abhängigkeit von Anwendungscode zur Durchsetzung von Regeln ist riskant, da Code Fehler enthalten kann. Datenbank-Einschränkungen bieten eine Sicherheitsnetz.
1. Referenzielle Integrität
Fremdschlüssel-Einschränkungen stellen sicher, dass ein Auftrag immer auf einen gültigen Benutzer und ein Produkt verweist. Wenn ein Produkt gelöscht wird, kann die Datenbank so konfiguriert werden, dass die Löschung verhindert oder die Aktion auf abhängige Datensätze weitergeleitet wird. Im E-Commerce ist es in der Regel sicherer, die Löschung von Produkten mit bestehenden Aufträgen zu verhindern.
2. Transaktionale Atomsicherheit
Eine Transaktion gruppiert mehrere Operationen in eine einzelne Einheit. Entweder gelingen alle Operationen, oder keine. Dies ist entscheidend für Inventaraktualisierungen. Wenn ein Auftrag platziert wird, muss das Inventar abnehmen. Wenn die Inventaraktualisierung fehlschlägt, sollte der Auftrag nicht erstellt werden.
- Transaktion beginnen: Sperrt die betreffenden Ressourcen.
- Aktualisierungen ausführen: Führt die erforderlichen Schreibvorgänge aus.
- Commit: Macht die Änderungen dauerhaft.
- Rollback: Stellt die Änderungen zurück, falls ein Fehler auftritt.
3. Eindeutige Einschränkungen
Eindeutige Einschränkungen verhindern doppelte Einträge. Dies ist nützlich für E-Mail-Adressen in der Benutzertabelle oder Artikelnummern in der Produkttabelle. Es verhindert, dass das System versehentlich doppelte Konten oder konflikthafte Inventarpositionen erstellt.
Umgang mit hoher Konkurrenz ⚡
Flash-Sales und Hochverkehrssituationen erzeugen Rennbedingungen. Mehrere Benutzer könnten gleichzeitig versuchen, dasselbe Produkt zu kaufen.
Optimistisches Locking
Optimistisches Locking geht davon aus, dass Konflikte selten sind. Es beinhaltet das Hinzufügen einer Versionsnummer zur Zeile. Beim Aktualisieren prüft die Datenbank, ob die Versionsnummer übereinstimmt. Wenn sie sich geändert hat, wird die Aktualisierung abgelehnt, und die Anwendung muss versuchen, erneut zu aktualisieren.
Pessimistisches Locking
Pessimistisches Locking sperrt die Zeile sofort beim Lesen. Andere Transaktionen müssen warten, bis die Sperrung aufgehoben ist. Dies garantiert die Datenkonsistenz, kann aber die Durchsatzrate bei hoher Konkurrenz reduzieren.
Bestandsreservierung
Um Überverkauf zu verhindern, reservieren Sie den Bestand, wenn der Benutzer einen Artikel in den Warenkorb legt. Legen Sie einen Zeitlimit für diese Reservierung fest. Wenn der Benutzer die Bezahlung innerhalb der Zeitbegrenzung nicht abschließt, wird der Bestand an den verfügbaren Pool zurückgegeben.
Überlegungen zu Suche und Analytik 📊
Transaktionsdatenbanken sind nicht für komplexe analytische Abfragen oder Volltextsuche ausgelegt. Das Ausführen von umfangreichen Suchabfragen auf den Haupttabellen für Bestellungen oder Produkte kann die Leistung für normale Benutzer beeinträchtigen.
- Suchmaschinen:Verwenden Sie eine spezialisierte Suchmaschine für die Produktsuche. Synchronisieren Sie Produktinformationen asynchron aus der Hauptdatenbank in die Suchmaschine.
- Analyse-Warehouses:Verschieben Sie historische Daten in einen separaten analytischen Speicher für Berichterstattung. Dadurch bleibt die Transaktionsdatenbank leichtgewichtig.
- Lesereplikate:Leiten Sie schreibgeschützten Datenverkehr an Replikat-Server weiter. Dadurch wird die Last vom primären Schreibserver getrennt.
Durch die Trennung von schreibintensiven von lesintensiven Operationen stellen Sie sicher, dass der Zahlungsprozess auch dann schnell bleibt, wenn Benutzer browsen oder Berichte erstellen.
Wartung und langfristiges Wachstum 🔄
Ein Datenbankdesign ist nicht statisch. Es muss sich mit dem Unternehmen entwickeln. Wenn neue Funktionen hinzugefügt werden, können Änderungen am Schema notwendig werden.
- Versionsverwaltung:Verfolgen Sie die Schema-Versionen. Dadurch ist ein sicheres Zurücksetzen möglich, falls eine Migration fehlschlägt.
- Archivierung:Verschieben Sie alte Bestellungen in eine kalte Speicherung. Dadurch bleibt die Größe der aktiven Tabellen überschaubar.
- Überwachung:Richten Sie Warnungen für langsame Abfragen, Warteschlangen bei Sperren und Festplattennutzung ein. Proaktive Überwachung verhindert Ausfälle.
Überprüfen Sie regelmäßig das ERD anhand der tatsächlichen Nutzungsmuster. Einige Beziehungen, die auf Papier gut aussahen, erweisen sich in der Produktion als ineffizient. Seien Sie bereit, bei signifikanten Änderungen der Datenmuster umzustrukturieren.
Zusammenfassung der Best Practices ✅
Die Gestaltung einer skalierbaren E-Commerce-Datenbank erfordert ein Gleichgewicht aus Struktur und Flexibilität. Die folgenden Punkte fassen die wichtigsten Erkenntnisse für den Aufbau eines robusten Systems zusammen.
- Trennung der Verantwortlichkeiten:Halten Sie Authentifizierungs-, Katalog- und Transaktionsdaten getrennt.
- Schnappschuss-Daten:Speichern Sie Bestelldetails zum Zeitpunkt des Kaufs, nicht nur Referenzen.
- Konsistenzkontrolle:Verwenden Sie Transaktionen und Sperren, um Überverkauf zu verhindern.
- Indizierung:Optimieren Sie für die häufigsten Lese- und Schreibmuster.
- Skalierbarkeit: Planen Sie frühzeitig die Partitionierung und Sharding in der Architektur.
- Sicherheit: Verschlüsseln Sie sensible Daten und setzen Sie strenge Zugriffssteuerungen durch.
Durch Einhaltung dieser Muster schaffen Sie eine Grundlage, die Wachstum unterstützt. Die Datenbank wird zu einer stabilen Maschine, die das Geschäft betreibt, ohne ständige Notfallreparaturen zu erfordern. Konzentrieren Sie sich zunächst auf die Datenintegrität, danach auf die Geschwindigkeitsoptimierung. Ein langsames System ist besser als ein falsches.