










Die Datenbankgestaltung ist die Grundlage jeder robusten Softwareanwendung. Beim Aufbau von Systemen, die komplexe Daten verarbeiten, liegt der Unterschied zwischen einer skalierbaren Architektur und einem zerbrechlichen Durcheinander oft darin, wie Sie die Informationen strukturieren. Im Zentrum dieser Struktur stehen drei grundlegende Säulen: Entitäten, Attribute und Beziehungen. Das Verständnis dieser Konzepte ist für einen Entwickler keine Wahl; es ist unverzichtbar, um wartbare, effiziente und logische Datenmodelle zu erstellen.
Ein Entity-Relationship-Diagramm (ERD) dient als Bauplan für diese Strukturen. Es visualisiert, wie Daten miteinander verbunden sind, wie sie gespeichert werden und wie sie durch Ihr System fließen. Ohne ein klares Verständnis dieser zentralen Komponenten wird selbst die fortschrittlichste Anwendungslogik Schwierigkeiten haben, ordnungsgemäß zu funktionieren. Dieser Leitfaden erläutert jedes Element präzise, sodass Sie Datenmodelle mit Vertrauen und Klarheit gestalten können.
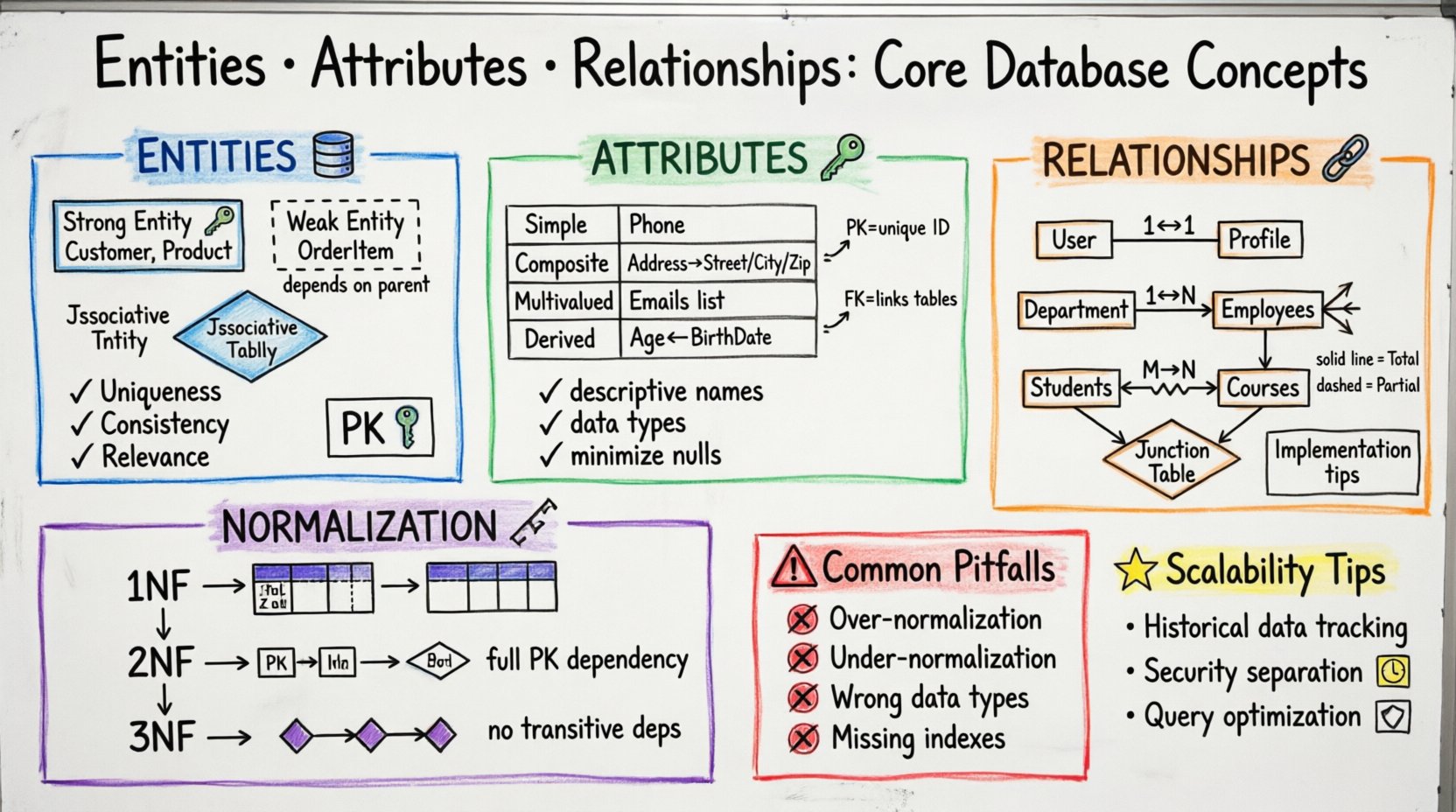
Verständnis von Entitäten: Die Grundlage der Daten 🧱
Im Kontext der Datenbankgestaltung steht eine Entität für ein eindeutiges Objekt oder Konzept, über das Sie Informationen speichern müssen. Sie ist das Substantiv in Ihrem Datenmodell. Stellen Sie sich vor, es handelt sich um eine Kategorie oder eine Klasse von Dingen, die in der realen Welt oder in Ihrem Geschäftsbereich existieren. Jede Entität muss innerhalb des Systems eindeutig und identifizierbar sein.
Arten von Entitäten
Entitäten sind nicht alle gleich. Die Erkennung der Art der Entität, mit der Sie es zu tun haben, hilft dabei, die Regeln für die Speicherung und Abrufung von Daten festzulegen.
- Starke Entitäten: Sie existieren unabhängig. Sie verfügen über einen eigenen Primärschlüssel und sind nicht von anderen Entitäten abhängig, um zu existieren. Zum Beispiel eine Kunde oder eine Produktkann eigenständig existieren.
- Schwache Entitäten: Sie hängen von einer starken Entität ab, um zu existieren. Sie können ohne die übergeordnete Entität nicht eindeutig identifiziert werden. Ein klassisches Beispiel ist eine Bestellposition innerhalb einer Bestellung. Ohne den Bestellkontext hat das Element in diesem spezifischen Schema keine Bedeutung.
- Assoziative Entitäten: Auch als Verknüpfungstabellen bekannt, lösen diese viele-zu-viele-Beziehungen auf. Sie verbinden zwei andere Entitäten, um mehrere Verbindungen zwischen ihnen zu ermöglichen.
Erkennen von Entitäten
Beim Gestalten eines Modells müssen Sie sich fragen, welche Gegenstände der realen Welt verfolgt werden müssen. Suchen Sie nach Substantiven in Ihren Geschäftsanforderungen. Wenn eine Geschäftsregel vorschreibt, dass Sie den Status, die Historie oder die Eigenschaften eines Dings verfolgen müssen, ist dieses Ding wahrscheinlich eine Entität.
Berücksichtigen Sie die folgenden Merkmale, die eine gültige Entität definieren:
- Einzigartigkeit: Jede Instanz muss von jeder anderen Instanz unterscheidbar sein.
- Konsistenz: Die Definition der Entität sollte im gesamten System konsistent bleiben.
- Relevanz: Die Entität sollte einem Zweck im Geschäftslogik beitragen. Vermeiden Sie die Erstellung von Entitäten für Daten, die selten abgefragt oder verwendet werden.
Attribute: Definieren von Entitätseigenschaften 🔑
Sobald Sie die Entitäten identifiziert haben, müssen Sie sie beschreiben. Attribute sind die Merkmale, Eigenschaften oder Details, die eine Entität beschreiben. Wenn eine Entität eine Tabelle ist, ist ein Attribut eine Spalte. Zusammen bilden sie das vollständige Bild der Daten, die Sie verwalten.
Primärschlüssel und Fremdschlüssel
Nicht alle Attribute sind gleich. Einige spielen eine entscheidende Rolle für die Integrität und Verknüpfung von Daten.
- Primärschlüssel (PK): Ein eindeutiger Bezeichner für einen Datensatz innerhalb einer Entität. Er stellt sicher, dass keine zwei Zeilen identisch sind. Ein Primärschlüssel kann eine einzelne Spalte (wie eine ID-Nummer) oder ein zusammengesetzter Schlüssel aus mehreren Spalten sein.
- Fremdschlüssel (FK): Ein Attribut, das auf den Primärschlüssel einer anderen Entität verweist. Dadurch wird die Beziehung zwischen Tabellen hergestellt. Er gewährleistet die Referenzintegrität und stellt sicher, dass ein Datensatz in einer Tabelle keinen Verweis auf einen nicht existierenden Datensatz in einer anderen Tabelle enthält.
Attributklassifizierungen
Attribute unterscheiden sich darin, wie sie gespeichert und abgeleitet werden. Das Verständnis dieser Unterschiede hilft bei der Optimierung von Speicherplatz und Abfrageleistung.
| Typ | Beschreibung | Beispiel |
|---|---|---|
| Einfach | Kann nicht weiter unterteilt werden. Es ist atomar. | Telefonnummer |
| Zusammengesetzt | Kann in Unterteile aufgeteilt werden. | Adresse (Straße, Stadt, PLZ) |
| Mehrwertig | Kann mehrere Werte für eine einzelne Entitätsinstanz enthalten. | E-Mail-Adressen |
| Abgeleitet | Wird aus anderen Attributen berechnet. | Alter (abgeleitet aus Geburtsdatum) |
Best Practices für Attribute
Beim Definieren von Attributen sollten Sie die folgenden Richtlinien beachten, um die Datenqualität zu gewährleisten:
- Verwenden Sie beschreibende Namen: Vermeiden Sie generische Namen wie
"col1"oderDaten. Verwenden Sie Namen, die den Inhalt erklären, wie zum Beispielkunden_emailoderbestelldatum. - Definieren Sie Datentypen: Seien Sie präzise. Verwenden Sie Ganzzahlen für Zählungen, Datumsangaben für zeitbezogene Daten und Zeichenketten für Text. Dies verhindert Fehler bei der Dateneingabe und -abfrage.
- Minimieren Sie NULL-Werte: Wo immer möglich, setzen Sie Einschränkungen durch, damit Attribute nicht leer bleiben. NULL-Werte können Abfragen komplizieren und zu unerwarteten Ergebnissen führen.
- Normalisieren Sie die Daten: Stellen Sie sicher, dass Attribute sich nur auf den Primärschlüssel beziehen. Vermeiden Sie das Speichern von Daten, die abgeleitet werden könnten oder in eine andere Entität verschoben werden könnten.
Beziehungen: Die Punkte verbinden 🔗
Entitäten existieren selten isoliert. Beziehungen definieren, wie Entitäten miteinander interagieren. Sie bestimmen, wie Daten verknüpft werden, wie Abfragen verbunden werden und wie die Integrität über die gesamte Datenbank gewährleistet wird. Eine gut gestaltete Beziehungsstruktur verhindert Datenredundanz und stellt sicher, dass Aktualisierungen korrekt weitergegeben werden.
Kardinalität
Die Kardinalität definiert die numerische Beziehung zwischen Entitäten. Sie beantwortet die Frage: „Wie viele Instanzen von Entität A stehen mit wie vielen Instanzen von Entität B in Beziehung?“
- Ein-zu-Eins (1:1): Eine Instanz von Entität A steht genau mit einer Instanz von Entität B in Beziehung. Dies ist selten, tritt aber beispielsweise auf, wenn ein Benutzer ein Profil hat.
- Ein-zu-Viele (1:N): Eine Instanz von Entität A steht mit mehreren Instanzen von Entität B in Beziehung. Zum Beispiel hat eine Abteilung viele Mitarbeiter.
- Viele-zu-Viele (M:N): Mehrere Instanzen von Entität A stehen mit mehreren Instanzen von Entität B in Beziehung. Zum Beispiel kann ein Student kann an vielen Kursen, und eine Kurs kann viele Studenten.
Teilnahmeverpflichtungen
Die Kardinalität gibt Ihnen die Menge an, aber Teilnahmeverpflichtungen sagen Ihnen, ob die Beziehung obligatorisch ist.
- Totale Teilnahme: Jede Instanz einer Entität muss an der Beziehung teilnehmen. Zum Beispiel muss jede Bestellung muss eine Kunde.
- Partielle Teilnahme: Eine Instanz kann an der Beziehung teilnehmen oder auch nicht. Zum Beispiel kann ein Kunde kann eine Bestellung zu einem bestimmten Zeitpunkt haben.
Implementierungsstrategien
Verschiedene Kardinalitäten erfordern unterschiedliche Implementierungsstrategien innerhalb des Datenmodells.
| Beziehungstyp | Implementierungsmethode | Beispielszenario |
|---|---|---|
| 1:1 | Tabellen zusammenführen oder Fremdschlüssel auf einer Seite hinzufügen. | Benutzerprofil verknüpft mit Benutzerkonto. |
| 1:N | Fremdschlüssel zur Tabelle der „vielen“ Seite hinzufügen. | Die Mitarbeiter-Tabelle hat eine Abt_ID. |
| M:N | Erstellen Sie eine Verbindungstabelle mit zwei Fremdschlüsseln. | Belegungstabelle, die Studierende und Kurse verknüpft. |
Normalisierung: Strukturierung für Stabilität 📐
Während Entitäten, Attribute und Beziehungen die Struktur bilden, organisiert die Normalisierung diese Struktur, um Redundanz zu reduzieren und die Integrität zu verbessern. Die Normalisierung ist eine Reihe von Schritten, die darauf abzielen, sicherzustellen, dass Datenabhängigkeiten sinnvoll sind.
Erste Normalform (1NF)
In der 1NF muss jeder Spalte atomare Werte enthalten. Sie können keine Liste von Werten in einer einzigen Zelle speichern. Jede Zeile muss eindeutig sein, typischerweise durch einen Primärschlüssel garantiert. Dadurch werden sich wiederholende Gruppen eliminiert.
Zweite Normalform (2NF)
Sobald die 1NF erreicht ist, stellt die 2NF sicher, dass alle nichtschlüsselbasierten Attribute vollständig vom Primärschlüssel abhängen. Wenn Sie einen zusammengesetzten Schlüssel haben, muss jedes Attribut vom gesamten Schlüssel abhängen, nicht nur von einem Teil davon.
Dritte Normalform (3NF)
Die 3NF entfernt transitive Abhängigkeiten. Nichtschlüsselattribute sollten nicht von anderen nichtschlüsselbasierten Attributen abhängen. Zum Beispiel, wenn Stadt abhängig von Postleitzahl, und Postleitzahl abhängig von Kunden-ID, dann hängt Stadt abhängig von Kunden-ID transitiv ab. Um dies zu beheben, verschieben Sie Stadt in eine separate Entität oder stellen Sie sicher, dass sie direkt mit dem Schlüssel verknüpft ist.
Häufige Fehler bei der Gestaltung ⚠️
Selbst erfahrene Entwickler machen Fehler bei der Gestaltung von Datenmodellen. Die Kenntnis häufiger Fehler kann erhebliche Zeit während der Entwicklungsphase sparen.
- Übernormalisierung:Die Aufteilung von Daten in zu viele kleine Entitäten kann Abfragen komplex und langsam machen. Manchmal ist eine De-Normalisierung für arbeitslastige Leseoperationen akzeptabel.
- Unternormalisierung: Die Speicherung derselben Daten an mehreren Stellen führt zu Inkonsistenzen. Wenn sich die Adresse eines Kunden ändert, müssen Sie diese in jedem Datensatz aktualisieren. Dies erhöht das Risiko von Fehlern.
- Ignorieren von Datentypen: Die Verwendung von Zeichenketten für Zahlen oder Datumsangaben führt zu Sortierproblemen und Validierungsfehlern. Passen Sie den Attributtyp immer genau dem tatsächlichen Dateninhalt an.
- Hartkodierte Werte: Vermeiden Sie die Speicherung von Statuscodes als Zeichenketten, wenn sie eine spezifische Bedeutung haben. Verwenden Sie Referenztabellen für Werte wie „Status“ oder „Land“, um Konsistenz zu gewährleisten.
- Fehlende Indizes: Fremdschlüssel und häufig abgefragte Attribute sollten indiziert werden, um die Suchgeschwindigkeit zu verbessern. Ohne Indizes können Join-Operationen zu Engpässen werden.
Erweiterte Überlegungen zur Skalierbarkeit 🚀
Wenn Anwendungen wachsen, muss das Datenmodell sich weiterentwickeln. Frühe Gestaltungsentscheidungen beeinflussen, wie leicht das System skaliert werden kann. Hier sind Überlegungen für langfristige Stabilität.
Umgang mit historischen Daten
Geschäftsregeln ändern sich im Laufe der Zeit. Attribute, die einst verpflichtend waren, können optional werden. Beziehungen können sich verschieben. Anstatt ständig das Schema zu ändern, überlegen Sie, Spalten für die Historie hinzuzufügen oder zeitbasierte Tabellen zu verwenden, um Änderungen im Laufe der Zeit zu verfolgen. Dadurch können Sie Änderungen auditieren, ohne die aktuelle Funktionalität zu stören.
Sicherheit und Zugriffssteuerung
Entitäten enthalten oft sensible Informationen. Gestalten Sie Ihre Beziehungen so, dass sie die Zugriffssteuerung unterstützen. Zum Beispiel die Trennung vonBenutzerDaten vonProtokollenDaten kann helfen, Berechtigungen zu verwalten. Stellen Sie sicher, dass Fremdschlüssel sensible Daten nicht unautorisierten Benutzern offenlegen.
Abfrageleistung
Die Art und Weise, wie Sie Beziehungen strukturieren, wirkt sich direkt auf die Abfrageleistung aus. Tief verschachtelte Beziehungen erfordern mehrere Joins, was die Datenabrufgeschwindigkeit verlangsamen kann. Analysieren Sie Ihre häufigsten Abfragen und strukturieren Sie Ihre Entitäten so, dass die Anzahl der erforderlichen Joins minimiert wird. Manchmal ist es die richtige Entscheidung, bestimmte Attribute in einen lesbar optimierten Speicher zu de-normalisieren.
Fazit 🏁
Die Beherrschung der Grundkonzepte von Entitäten, Attributen und Beziehungen ist eine Reise, die sich während Ihrer gesamten Karriere fortsetzt. Diese Elemente sind nicht nur theoretische Konstrukte; sie sind die praktischen Werkzeuge, die Sie benötigen, um Systeme zu bauen, die über Jahre hinweg Bestand haben. Indem Sie sich auf Klarheit, Integrität und Effizienz konzentrieren, erstellen Sie Datenmodelle, die Ihre Anwendungen jahrelang unterstützen.
Beginnen Sie mit den Grundlagen. Definieren Sie Ihre Entitäten klar. Weisen Sie Attribute zu, die sie genau beschreiben. Zeichnen Sie Beziehungen, die echte Interaktionen der realen Welt widerspiegeln. Wenn Sie diese Entwürfe verfeinern, werden Sie feststellen, dass die Logik Ihrer Anwendung sauberer und robuster wird. Denken Sie daran, dass ein gutes Design leicht verständlich und leicht veränderbar ist. Behalten Sie diese Prinzipien im Hinterkopf, während Sie Ihre Entwicklungsaufgaben voranbringen.
Die Investition von Zeit in eine korrekte ERD-Design führt zu Vorteilen in Form von weniger Fehlern, schnelleren Entwicklungszyklen und einem wartbareren Code. Egal, ob Sie eine kleine Hilfsfunktion oder ein großes Enterprise-System entwickeln, die Regeln für Entitäten, Attribute und Beziehungen bleiben gleich. Bleiben Sie bei den Grundlagen, und Ihre Datenarchitektur wird den Anforderungen der Zeit standhalten.