










Die Gestaltung robuster Datenbankschemata erfordert mehr als nur die Auflistung von Tabellen und Spalten. Es erfordert ein tiefes Verständnis dafür, wie Entitäten miteinander verwandt sind. Unter den mächtigsten, aber auch komplexesten Konzepten in Entity-Relationship-Diagrammen (ERD) ist die Vererbung. Diese Mechanik ermöglicht es uns, realweltliche Hierarchien zu modellieren, bei denen Objekte gemeinsame Merkmale teilen, aber auch einzigartige Attribute besitzen. Im Kontext der Datenbankgestaltung bedeutet dies Ober- und Untertypen. 🧩
Wenn wir Vererbung modellieren, erfassen wir im Wesentlichen die „ist-ein“-Beziehung. Zum Beispiel ist ein Fahrzeug ist eine Art von Produkt, und ein Auto ist eine Art von Fahrzeug. Diese Hierarchie ermöglicht es uns, Attribute auf höheren Ebenen zu wiederholen, während wir spezifische Verhaltensweisen oder Daten auf niedrigeren Ebenen definieren. Das Verständnis, wie dies in einer relationalen Datenbank implementiert wird, ist entscheidend für die Datenintegrität und die Abfrageleistung. 🗄️
🔑 Kernkonzepte: Ober- und Untertypen
Bevor wir in die Implementierung einsteigen, müssen wir die Begrifflichkeiten klar definieren. Die Vererbung in der Datenbankmodellierung geht nicht nur um Code; es geht um die strukturelle Darstellung von Daten.
- OberTyp: Dies ist die übergeordnete Entität. Sie enthält Attribute, die allen verwandten Entitäten gemeinsam sind. Sie repräsentiert die allgemeine Kategorie. Zum Beispiel könnte Mitarbeiter ein OberTyp sein.
- Untertyp: Dies sind die untergeordneten Entitäten. Sie erben Attribute vom OberTyp, können aber auch eigene einzigartige Attribute besitzen. Beispiele sind Manager oder Entwickler.
- Entitätskategorie: Der OberTyp wird manchmal als Entitätskategorie bezeichnet, wodurch die Untertypen zusammengefasst werden.
- Unterscheidungsmerkmal: Ein spezifisches Attribut innerhalb des OberTyps, das identifiziert, zu welchem Untertyp eine Instanz gehört. Dies wird häufig bei physischen Implementierungen verwendet.
Die Beziehung zwischen einem OberTyp und einem Untertyp ist streng. Jede Instanz eines Untertyps muss auch eine Instanz des OberTyps sein. Jedoch muss nicht jede Instanz des OberTyps eine Instanz eines bestimmten Untertyps sein. Diese Unterscheidung ist entscheidend für die Genauigkeit der Datenmodellierung. ✅
📊 Implementierungsstrategien
Die Umsetzung des logischen ERD-Modells in ein physisches Datenbankschema erfordert spezifische Abbildungsstrategien. Es gibt drei Hauptansätze, um Vererbung in relationalen Systemen darzustellen. Jeder hat Kompromisse hinsichtlich Speicherplatz, Abrufgeschwindigkeit und Datenintegrität. 🛠️
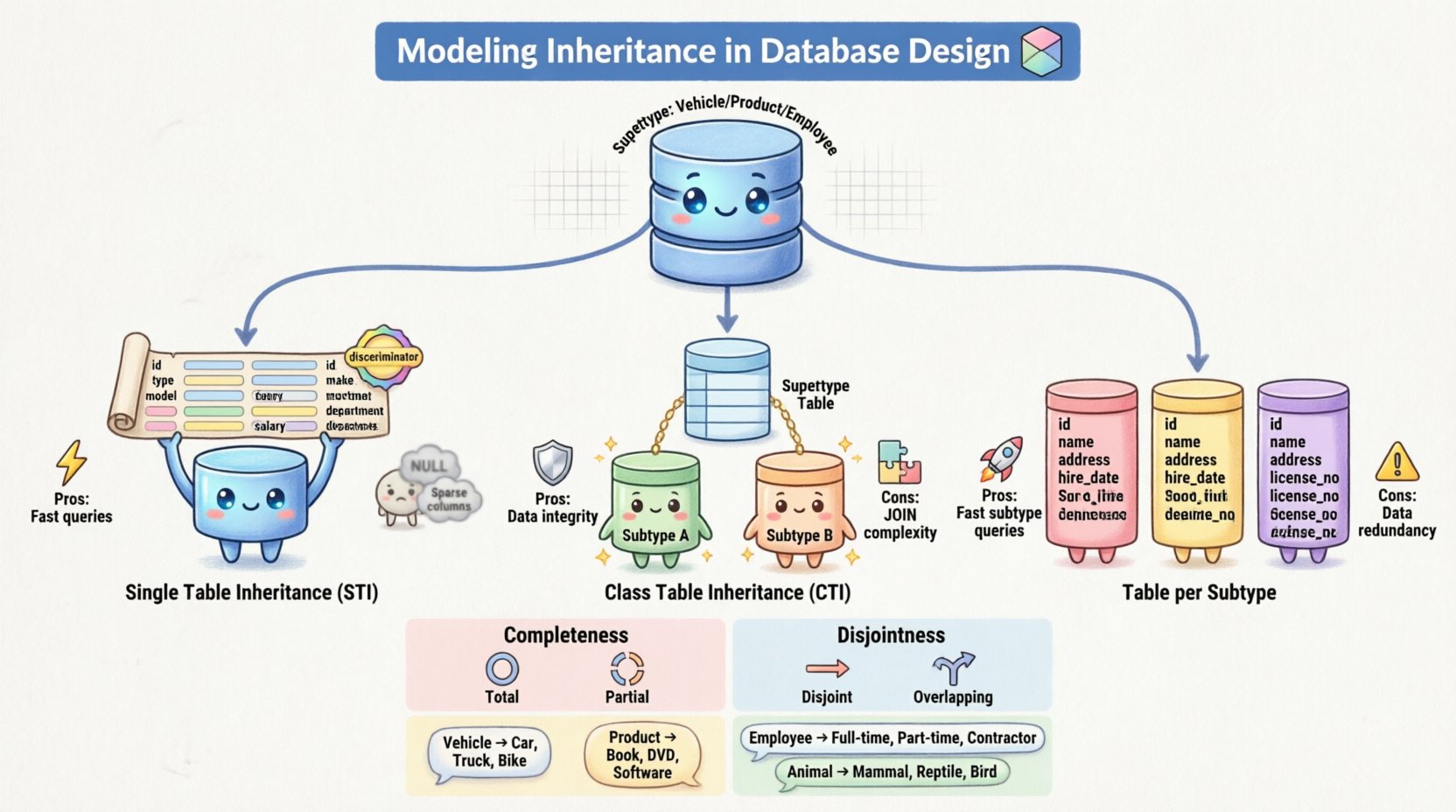
1. Einzeltabellenvererbung (STI)
Bei diesem Ansatz werden alle Attribute des Obertyps und aller Untertypen in einer einzigen Tabelle kombiniert. Die Tabelle enthält Spalten für jedes Attribut, das in der gesamten Hierarchie definiert ist. Um Zeilen unterschiedlicher Untypen voneinander zu unterscheiden, wird eine Diskriminatorspalte hinzugefügt.
- Vorteile: Sehr effizient beim Lesen von Daten. Ein einfacher
SELECTruft alle Informationen ab, ohne komplexe Verknüpfungen zu benötigen. - Nachteile: Die Tabelle kann sehr breit werden mit vielen
NULLWerten für Attribute, die für bestimmte Untypen nicht gelten. Es kann auch Updates erschweren, wenn sich die für Untypen spezifischen Einschränkungen ändern.
2. Klassentabellenvererbung (CTI)
Hier werden der Obertyp und jeder Untyp jeweils einer eigenen Tabelle zugeordnet. Die Obertypentabelle enthält die gemeinsamen Attribute und einen Primärschlüssel. Jede Untypentabelle enthält die eindeutigen Attribute sowie einen Fremdschlüssel, der zurück zum Primärschlüssel des Obertyps verweist.
- Vorteile: Hoch normalisiert. Keine
NULLWerte für nicht anwendbare Attribute. Stellt die Referenzintegrität strikt sicher. - Nachteile: Das Abrufen von Daten erfordert mehrere
JOINOperationen, die sich negativ auf die Leistung bei großen Datensätzen auswirken können. Es erschwert auch dieINSERTOperationen, da die Daten in mehreren Tabellen geschrieben werden müssen.
3. Eine Tabelle pro Untyp (konkrete Tabellenvererbung)
Bei dieser Strategie wird für jeden Untyp, einschließlich des Obertyps, eine eigene Tabelle erstellt. Jede Untypentabelle enthält jedoch eine Kopie der Attribute des Obertyps. Es gibt keinen direkten Link zurück zu einer zentralen Obertypentabelle.
- Vorteile: Das Abfragen eines bestimmten Untyps ist sehr schnell, da alle Daten an einem Ort gespeichert sind. Es vermeidet das
NULLProblem der STI. - Nachteile: Datenspeicherung mit Redundanz. Wenn ein gemeinsames Attribut im Obertyp geändert wird, muss es in jeder Untypentabelle aktualisiert werden. Dies erhöht das Risiko von Dateninkonsistenzen.
⚖️ Einschränkungen der Vererbung
Nicht alle Vererbungsbeziehungen sind gleich. Wir müssen Einschränkungen definieren, die steuern, wie Instanzen zu ihren Typen in Beziehung stehen. Diese Einschränkungen stellen sicher, dass die Daten logisch und konsistent bleiben. 📝
Vollständigkeits-Einschränkung
Diese Einschränkung bestimmt, ob jede Instanz eines OberTyps einer Untertypen angehören muss.
- Vollständig: Jede Instanz des OberTyps muss Mitglied mindestens eines Untertyps sein. Es gibt keine „generischen“ Instanzen. Zum Beispiel muss jedes Tier entweder ein Säugetier oder ein Vogel.
- Partiell: Eine Instanz des OberTyps muss nicht unbedingt einem Untertyp angehören. Sie kann als allgemeine Entität existieren. Dies ist häufig, wenn die Hierarchie zur Kategorisierung statt zur strengen Klassifizierung verwendet wird.
Disjunktheits-Einschränkung
Diese Einschränkung bestimmt, ob eine Instanz gleichzeitig mehreren Untertypen angehören kann.
- Disjunkt: Eine Instanz kann nur einem Untertyp angehören. Sie kann innerhalb dieses Modells nicht gleichzeitig ein Manager und ein Entwickler sein.
- Überlappung: Eine Instanz kann mehreren Untertypen angehören. Dies ermöglicht komplexe Rollen, bei denen ein Mitarbeiter mehrere Positionen oder Klassifizierungen innehaben kann.
Die Kombination dieser Einschränkungen ergibt vier unterschiedliche Modellierungsszenarien. Es ist entscheidend, zu verstehen, welches Szenario Ihrer Geschäftslogik entspricht, bevor das Schema erstellt wird. 🧠
| Einschränkungstyp | Definition | Beispiel-Szenario |
|---|---|---|
| Disjunkt + Vollständig | Nur ein Untertyp, keine generischen Instanzen | Bestellstatus: Ausstehend, Versandt, Geliefert |
| Disjunkt + Teilweise | Nur ein Untertyp, optionaler Untertyp | Kunde: VIP oder Normal (manche sind beides nicht) |
| Überlappung + Vollständig | Mehrere Untertypen erlaubt, muss zu einem gehören | Benutzerrolle: Admin und Editor (muss mindestens eine haben) |
| Überlappung + Teilweise | Mehrere Untertypen erlaubt, optional | Produkt: Verkaufsfähig, Werbeartikel (kann beides oder nichts sein) |
🔍 Abfragen und Datenabruf
Die Wahl der Abbildungsstrategie beeinflusst maßgeblich, wie Sie Abfragen schreiben. In einer normalisierten Umgebung müssen Sie oft die Hierarchie durchlaufen, um ein vollständiges Bild einer Entität zu erhalten. 🔎
- Abrufen von Untertypdaten: Wenn Sie auf Attribute zugreifen müssen, die spezifisch für einen Untertyp sind, müssen Sie die Untertyptabelle verknüpfen. Dies ist Standard bei der Klassentabellenvererbung.
- Abrufen von Oberklassendaten: Wenn Sie gemeinsame Attribute benötigen, können Sie die Oberklassentabelle direkt abfragen.
- Polymorphe Abfragen: Wenn Sie nach allen Instanzen unabhängig vom Untertyp suchen, ist die Einzeltabellenmethode am schnellsten. Wenn Sie jedoch mehrere Tabellen verwenden, müssen Sie
VEREINIGUNGOperationen oder komplexe Verknüpfungen verwenden.
Berücksichtigen Sie die Leistungsauswirkungen. Eine Abfrage, die fünf Tabellen verknüpft, um eine einzelne Aufzeichnung abzurufen, kann langsamer sein als eine Abfrage auf einer de-normalisierten Einzeltabelle. Allerdings kann die de-normalisierte Tabelle die Normalisierungsregeln verletzen und zu Aktualisierungsanomalien führen. Das Abwägen dieser Faktoren ist ein zentraler Bestandteil der Schema-Design.
🛠️ Wartung und Evolution
Schemata sind nicht statisch. Die Geschäftsanforderungen ändern sich, und daher muss auch die Datenbankstruktur angepasst werden. Die Vererbungsmodellierung bietet Flexibilität, führt aber auch zu Komplexität bei der Wartung. 🔄
Hinzufügen neuer Untertypen
Das Hinzufügen eines neuen Untertyps ist in der Regel einfach. Sie erstellen eine neue Tabelle (bei CTI) oder einen neuen Wert in der Diskriminiererspalte (bei STI). Sie müssen jedoch sicherstellen, dass bestehende Abfragen und Anwendungslogik den neuen Typ berücksichtigen. Ein nicht aktualisierter Code kann zu Laufzeitfehlern führen.
Ändern von Oberklassenattributen
Wenn Sie ein Attribut zur Oberklasse hinzufügen, muss es in jeder Untertyptabelle widergespiegelt werden, wenn Sie CTI oder Tabellen pro Untertyp verwenden. Bei STI fügen Sie es nur einmal in die einzige Tabelle hinzu. Dies macht STI bei allgemeinen Änderungen einfacher zu warten, aber bei spezifischen Änderungen schwieriger.
Datenmigration
Das Refactoring eines Vererbungsmodells ist eine erhebliche Aufgabe. Der Wechsel von einer einzigen Tabelle zu einer normalisierten Struktur erfordert die Migration von Daten über mehrere Tabellen. Dieser Prozess muss sorgfältig verwaltet werden, um Datenverlust oder -korruption zu vermeiden. 🚧
📈 Normalisierung und Vererbung
Das Modellieren von Vererbung steht eng in Verbindung mit der Datenbanknormalisierung. Ziel der Normalisierung ist es, Redundanz zu reduzieren und die Datenintegrität zu verbessern. Die Vererbung kann manchmal mit diesen Zielen kollidieren, wenn sie nicht korrekt behandelt wird.
- Erste Normalform (1NF): Vererbungsmodelle erfüllen im Allgemeinen die 1NF, da Attribute atomar sind.
- Zweite Normalform (2NF): Bei STI könnte eine Tabelle Attribute enthalten, die nicht vollständig vom Primärschlüssel abhängen, wenn der Diskriminator nicht Teil des Schlüssels ist. Dies erfordert eine sorgfältige Schlüsselgestaltung.
- Dritte Normalform (3NF): Bei CTI hilft die Aufteilung von Attributen in Untertabellen oft, die 3NF zu erreichen, indem transitive Abhängigkeiten entfernt werden.
Beim Entwerfen von Oberklassen stellen Sie sicher, dass die gemeinsamen Attribute wirklich gemeinsam genutzt werden. Wenn ein Attribut nur von einer Unterklasse verwendet wird, sollte es wahrscheinlich nicht in der Oberklasse enthalten sein. Dadurch wird verhindert, dass die Oberklasse zu einer „Gott-Tabelle“ wird, die schwer abfragbar ist. 👁️
🎯 Best Practices für die Schema-Design
Um sicherzustellen, dass Ihr Vererbungsmodell wartbar und leistungsfähig bleibt, befolgen Sie diese Richtlinien.
- Grenzen Sie die Tiefe:Vermeiden Sie tiefe Hierarchien. Drei Ebenen der Vererbung sind in der Regel das maximal empfohlene Maximum. Darüber hinaus überwiegt die Komplexität von Abfragen und Wartung die Vorteile.
- Verwenden Sie klare Benennungen: Die Namen sollten die Hierarchie widerspiegeln. Fahrzeug, Auto, LKW ist klar. Entität1, Entität2 ist nicht.
- Planen Sie für Wachstum:Planen Sie zukünftige Untertypen. Wenn Sie viele neue Untertypen erwarten, könnte eine einzelne Tabelle unübersichtlich werden. Wenn Sie nur wenige erwarten, könnte CTI besser geeignet sein.
- Dokumentieren Sie Einschränkungen: Dokumentieren Sie die Disjunktheits- und Vollständigkeitsbedingungen klar. Zukünftige Entwickler müssen wissen, ob eine Instanz zu mehreren Untertypen gehören kann.
- Indizierungsstrategie: Wenn CTI verwendet wird, indizieren Sie die Fremdschlüsselspalten in den Untertabellen, um Joins zu beschleunigen. Wenn STI verwendet wird, indizieren Sie die Diskriminatorspalte zur Filterung.
🧪 Szenarien aus der Praxis
Schauen wir uns an, wie dies auf tatsächliche Datenmodellierungsprobleme anwendbar ist.
Szenario 1: Personalwesen
In einem HR-System haben Sie Person als Oberklasse. Unterklassen sind Mitarbeiter, Freiberufler, und Praktikant. Jede Unterklasse hat eindeutige Daten: Mitarbeiter hat eine Gehalts-ID, Freiberufler hat eine Abrechnungsrate. Eine PersonTabelle enthält Namen und Adresse. Dies passt gut zum Klassen-Tabelle-Vererbungsmodell.
Szenario 2: Bestandsverwaltung
Betrachten Sie einen Produktkatalog. Produkt ist die Oberklasse. Unterklassen sind Elektronik, Möbel, und Bekleidung. Elektronik hat Gewährleistungszeitraum. Bekleidung hat Größe und Farbe. Wenn Sie alle Produkte mit Garantie abfragen, müssen Sie die Tabelle Elektronik verknüpfen. Dies verdeutlicht die Abwägung bei der Abfrageleistung. 🔍
Szenario 3: Finanztransaktionen
In einem Bankensystem ist Konto der Oberbegriff. Untertypen sind Sparen, Giro, und Darlehen. Ein SparenKonto hat einen Zinssatz. Ein DarlehenKonto hat ein Fälligkeitsdatum. Dieses Szenario profitiert oft von einem Single-Table-Ansatz, um die Berechnung der Kontostände über alle Kontotypen hinweg zu vereinfachen.
🚀 Leistungsüberlegungen
Die Leistung ist oft der entscheidende Faktor bei der Wahl einer Abbildungsstrategie. Große Datensätze verstärken die Unterschiede zwischen den Ansätzen.
- Schreibleistung: STI ist am schnellsten bei Einfügungen, da es eine einzelne
INSERTAnweisung ist. CTI erfordert mehrereEINFÜGENAnweisungen, was die Transaktionskosten erhöht. - Lesepreformance: Wenn Sie häufig nach bestimmten Untertypen abfragen, ist CTI schneller als STI, da Sie nur die relevanten Spalten lesen. Wenn Sie nach allen Instanzen abfragen, ist STI schneller.
- Speicher: STI verwendet mehr Speicher aufgrund von
NULLPlatzhalter. CTI verwendet mehr Speicher aufgrund doppelter Primärschlüssel und Fremdschlüssel, aber weniger aufgrund des Fehlens vonNULLPlatzhalter.
Es ist entscheidend, Ihre Anwendung zu profilieren. Theoretische Leistung stimmt nicht immer mit realen Nutzungsmustern überein. Der einzige Weg, Ihre Entscheidung zu bestätigen, ist die Prüfung mit realistischen Datenmengen. 📊
🛡️ Datenintegrität und Validierung
Die Aufrechterhaltung der Datenintegrität in einem Vererbungsmodell erfordert strenge Validierungsregeln. Sie müssen sicherstellen, dass die Daten, die in eine Untertyptabelle eingegeben werden, den Einschränkungen des OberTyps entsprechen.
- Fremdschlüsselbeschränkungen: Stellen Sie sicher, dass Untertypzeilen immer gültigen OberTypzeilen verknüpfen. Dadurch werden verwaiste Daten verhindert.
- Prüfbeschränkungen: Verwenden Sie Prüfbeschränkungen, um Geschäftsregeln durchzusetzen. Zum Beispiel stellen Sie sicher, dass die Zinssatz in einem SparUntertyp niemals negativ ist.
- Trigger: In einigen komplexen Szenarien können Datenbanktrigger notwendig sein, um die Konsistenz über mehrere Tabellen während Aktualisierungen aufrechtzuerhalten.
Automatisiertes Testen sollte Vererbungsszenarien abdecken. Stellen Sie sicher, dass die Erstellung einer neuen Untertypinstanz den OberTyp korrekt aktualisiert. Stellen Sie sicher, dass das Löschen einer OberTypinstanz korrekt auf die Untertypen durchgeleitet wird, falls dies beabsichtigt ist. 🧪
📝 Abschließende Überlegungen
Die Modellierung von Vererbung ist ein Ausgleich zwischen Flexibilität und Komplexität. Es gibt keine einzige „richtige“ Art, dies zu tun. Die beste Wahl hängt von Ihren spezifischen Datenzugriffsmustern, Geschäftsregeln und Leistungsanforderungen ab.
- Beginnen Sie mit einem klaren Verständnis des Bereichs. Zeichnen Sie die Entitäten auf, bevor Sie sich um die Tabellen kümmern.
- Wählen Sie eine Abbildungsstrategie, die Ihren häufigsten Abfragen entspricht.
- Dokumentieren Sie Ihre Entscheidungen. Die zukünftige Wartung wird auf dieser Dokumentation beruhen.
- Überprüfen Sie das Schema regelmäßig. Da sich das Geschäft weiterentwickelt, könnte das Modell geändert werden müssen.
Durch sorgfältige Gestaltung von Supertypen und Subtypen erstellen Sie eine Datenbank, die robust, skalierbar und leicht verständlich ist. Diese Grundlage unterstützt die darauf basierenden Anwendungen und gewährleistet langfristige Stabilität und Effizienz. 🏗️