











Die Gestaltung einer Datenbank geht nicht nur darum, Daten zu speichern; es geht darum, Informationen so zu strukturieren, dass Integrität gewährleistet ist, Redundanz minimiert wird und die Leistung optimiert wird. Wenn wir über effiziente Datenbankstrukturen sprechen, erheben sich zwei Säulen: Entitäts-Beziehungs-Diagramme (ERD) und Normalisierung. Diese Konzepte sind keine isolierten Techniken, sondern ergänzende Werkzeuge, die gemeinsam eine stabile Datenbasis schaffen.
Diese Anleitung untersucht, wie die visuelle Klarheit von ERDs mit der strukturellen Strenge der Normalisierung kombiniert werden kann. Wir werden den Prozess der Umwandlung eines konzeptionellen Modells in ein praktisches Schema durchgehen, das der Zeit standhält.
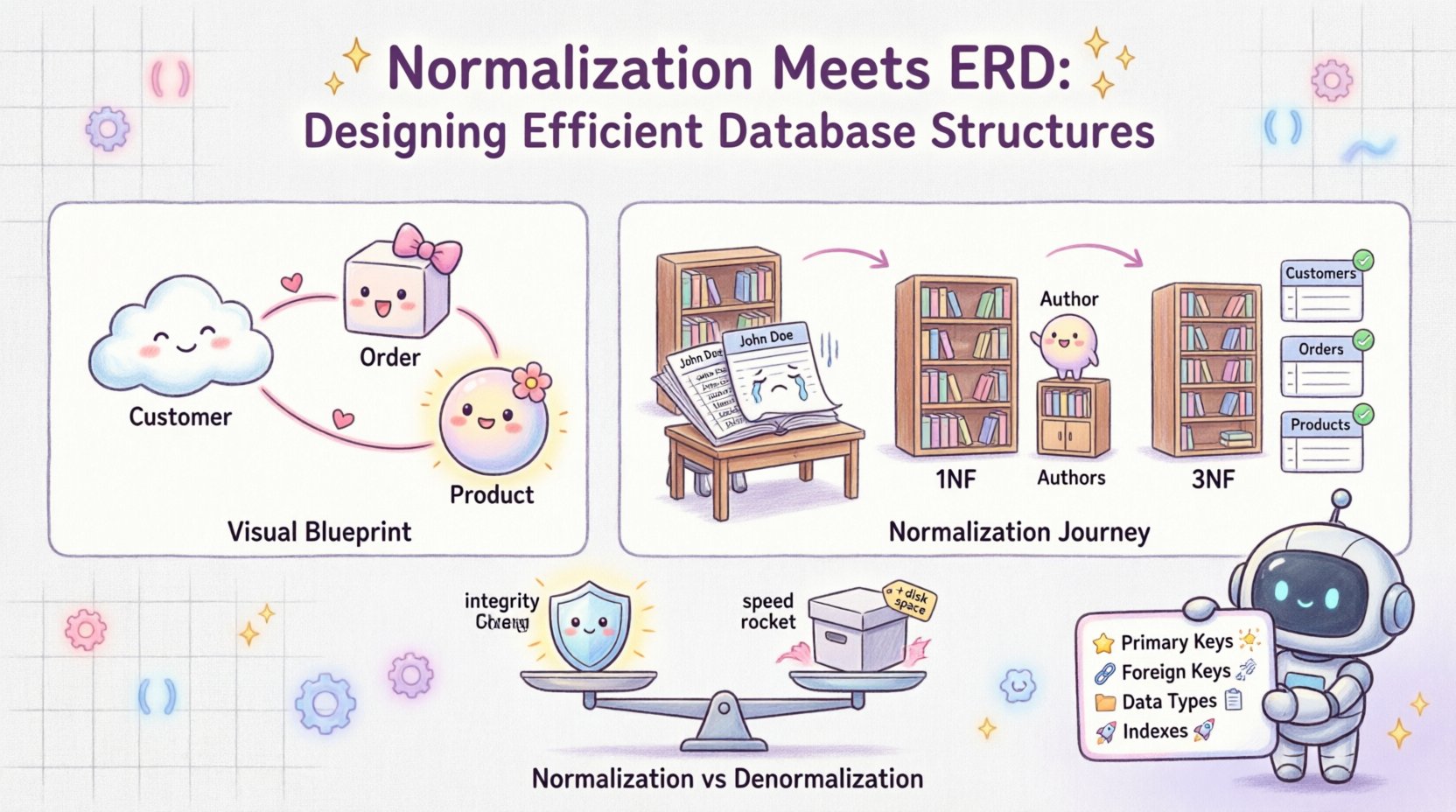
📐 Verständnis der Grundlage: ERDs und Normalisierung
Bevor wir in den Gestaltungsprozess einsteigen, ist es unerlässlich, die unterschiedlichen Aufgaben dieser beiden Methodologien zu verstehen.
📊 Was ist ein Entitäts-Beziehungs-Diagramm?
Ein Entitäts-Beziehungs-Diagramm dient als visuelles Bauplan einer Datenbank. Es zeigt die Entitäten (Tabellen), Attribute (Spalten) und Beziehungen (Verbindungen) zwischen ihnen auf. Stellen Sie sich vor, es sei der Architekturplan für ein Gebäude. Es beantwortet Fragen wie:
- Was sind die zentralen Objekte in unserem System? (z. B. Kunde, Bestellung)
- Wie interagieren diese Objekte miteinander? (z. B. Ein Kunde stellt viele Bestellungen)
- Welche Daten müssen wir für jedes Objekt speichern? (z. B. Kunde benötigt eine Name und E-Mail)
Ohne ein ERD wird die Datenbankgestaltung zu einem Ratespiel. Es bietet einen Überblick auf hoher Ebene, den Stakeholder verstehen können, und stellt sicher, dass alle sich vor der ersten Codezeile auf die Datenanforderungen einigen.
🧼 Was ist Normalisierung?
Normalisierung ist der Prozess der Organisation von Daten in einer Datenbank, um Redundanz zu reduzieren und die Datenintegrität zu verbessern. Dabei werden große Tabellen in kleinere, logische Strukturen aufgeteilt und Beziehungen zwischen ihnen definiert. Ziel ist es sicherzustellen, dass jeder Datenbestand an genau einer Stelle gespeichert wird.
Warum ist das wichtig?
- Datenintegrität: Wenn sich die Adresse eines Kunden ändert, aktualisieren Sie sie an einer Stelle, nicht an zehn.
- Speichereffizienz: Weniger doppelte Daten bedeuten geringeren Speicherplatzverbrauch.
- Wartung: Einfacher, das Schema im Laufe der Zeit zu pflegen und zu aktualisieren.
⚙️ Der Schnittpunkt: Kombination von ERD mit Normalisierung
Bei der Gestaltung einer Datenbank beginnt man oft mit einem ERD, aber ein roher ERD ist selten produktionsbereit. Er enthält oft Redundanzen, die die Normalisierung behebt. Der Arbeitsablauf umfasst die Erstellung eines konzeptionellen ERDs, die Analyse auf Anomalien und die Anwendung von Normalisierungsregeln zur Verfeinerung des Schemas.
Hier ist der typische Arbeitsablauf:
- Konzeptionelle Gestaltung: Zeichnen Sie den ursprünglichen ERD basierend auf den Anforderungen.
- Logische Gestaltung: Verfeinern Sie den ERD zu Tabellen und Spalten.
- Normalisierung: Wenden Sie Normalisierungsformen (1NF, 2NF, 3NF) an, um Anomalien zu beseitigen.
- Physische Gestaltung: Optimieren Sie für die spezifische Datenbank-Engine und Leistungsanforderungen.
🔍 Schritt für Schritt: Vom ERD zum normalisierten Schema
Lassen Sie uns ein praktisches Szenario durchgehen, um zu sehen, wie dies in der Praxis funktioniert. Stellen Sie sich vor, wir bauen ein System zur Verwaltung einer Bibliothek.
1. Der unnormalisierte Zustand
Zunächst könnten Sie eine einzelne Tabelle entwerfen, um alle Informationen zu Büchern und Autoren zu speichern. Dies wird als unnormalisierte Tabelle bezeichnet.
| BuchID | Titel | Autorenname | Autorennummer | Genre |
|---|---|---|---|---|
| 101 | Das große Werk | John Doe | 555-0101 | Fiktion |
| 102 | Das Geheimnis-Buch | John Doe | 555-0101 | Mysterium |
| 103 | Ein anderes Buch | Jane Smith | 555-0102 | Fiktion |
Achten Sie auf die Probleme hier? John Does Telefonnummer wird wiederholt. Wenn er seine Nummer ändert, müssen Sie mehrere Zeilen aktualisieren. Dies ist eine Aktualisierungsanomalie.
2. Erste Normalform (1NF)
Die erste Regel der Normalisierung besteht darin, die Atomsierung zu gewährleisten. Jede Spalte muss nur einen einzigen Wert enthalten, und es sollten keine sich wiederholenden Gruppen geben.
- Regel:Beseitigen Sie sich wiederholende Gruppen und stellen Sie atomare Werte sicher.
- Anwendung: In unserem Bibliotheksbeispiel könnte die ursprüngliche Tabelle bereits atomar sein, aber wir müssen sicherstellen, dass wir einen Primärschlüssel haben. Angenommen, BuchID ist eindeutig.
- Ergebnis: Wir haben nun eine Tabelle, in der jede Zelle einen Datenbestand enthält.
3. Zweite Normalform (2NF)
Sobald eine Tabelle in 1NF ist, prüfen wir auf partielle Abhängigkeiten. Eine Tabelle befindet sich in 2NF, wenn sie in 1NF ist und jedes nicht-schlüsselbasierte Attribut vollständig vom Primärschlüssel abhängt.
- Szenario: Wenn wir einen zusammengesetzten Schlüssel hätten (z. B. BuchID + AutorID), würden wir prüfen, ob AutorTelefon von dem gesamten Schlüssel oder nur vom Autorteil abhängt.
- Aktion: In unserem Beispiel hängt AutorTelefon hängt ab von Autornamen, nicht von der BuchID. Dies deutet darauf hin, dass wir Autordaten von Buchdaten trennen sollten.
4. Dritte Normalform (3NF)
Hier geschieht die echte Magie. 3NF beseitigt transitive Abhängigkeiten. Nicht-Schlüsselattribute sollten nicht von anderen Nicht-Schlüsselattributen abhängen.
- Regel: Kein Attribut sollte von einem anderen Nicht-Schlüsselattribut abhängen.
- Anwendung: AutorTelefon hängt ab von Autornamen. Da Autornamen kein Primärschlüssel der Buchtabelle ist, verschieben wir die Autordaten in eine separate AutorenTabelle.
- Ergebnis: Jetzt erfordert das Aktualisieren einer Autoren-Telefonnummer das Ändern nur eines Datensatzes in der Autoren Tabelle, nicht mehrere Datensätze in der Bücher Tabelle.
📋 Normalisierung vs. Denormalisierung: Das Gleichgewicht finden
Während die Normalisierung für die Integrität entscheidend ist, ist sie nicht immer die Lösung für die Leistung. Manchmal werden Daten häufiger gelesen als geschrieben. In solchen Fällen könnte die Denormalisierung vorteilhaft sein.
📉 Wann man denormalisieren sollte
Die Denormalisierung beinhaltet das Hinzufügen redundanter Daten zu einer normalisierten Datenbank, um die Leseleistung zu verbessern. Es ist ein Kompromiss zwischen Speicherplatz und Geschwindigkeit.
- Hoher Lesevolumen: Wenn Ihre Anwendung Daten tausendmal pro Sekunde abfragt, kann das Verknüpfen von Tabellen die Leistung verlangsamen.
- Berichts-Dashboards: Aggregierte Daten könnten vorab berechnet und gespeichert werden, um komplexe Abfragen zu vermeiden.
- Caching-Strategien: Manchmal fungieren denormalisierte Ansichten als Cache für häufig abgerufene Daten.
Allerdings birgt dies Risiken. Sie müssen die Synchronisierung der redundanten Daten manuell oder über Trigger verwalten. Wenn dies nicht sorgfältig gehandhabt wird, leidet die Datenintegrität.
| Faktor | Normalisierung | Denormalisierung |
|---|---|---|
| Datenintegrität | Hoch (einziges Quellensystem) | Niedriger (erfordert Synchronisationslogik) |
| Schreibgeschwindigkeit | Langsam (mehrere Tabellen) | Schneller (weniger Verknüpfungen) |
| Lesegeschwindigkeit | Langsam (mehrere Verknüpfungen) | Schneller (weniger Verknüpfungen) |
| Speicher | Effizient | Redundant |
🛠️ Häufige Fehler bei der Datenbankgestaltung
Selbst erfahrene Designer machen Fehler. Vermeiden Sie diese häufigen Fallen, um sicherzustellen, dass Ihre Datenbankstruktur gesund bleibt.
❌ Ignorieren von Datentypen
Die Auswahl des falschen Datentyps kann zu Speicherplatzverschwendung und Leistungsproblemen führen. Die Verwendung eines Textfeldes für Datumsangaben oder ganzzahliger Werte für Telefonnummern verschwendet Speicherplatz und erschwert die Validierung.
❌ Übermäßige Normalisierung
Die Anstrengung, in jeder Situation 5NF oder BCNF (Boyce-Codd-Normalform) zu erreichen, kann Abfragen unglaublich komplex machen. Manchmal reicht auch 3NF aus. Normalisieren Sie nicht einfach nur, weil es möglich ist.
❌ Schwache Primärschlüssel
Die Verwendung natürlicher Schlüssel (wie E-Mail-Adressen) als Primärschlüssel kann riskant sein, wenn sich die Daten ändern. Fremdschlüssel (auto-inkrementierende Ganzzahlen oder UUIDs) sind oft sicherer für interne Beziehungen.
❌ Fehlende Indizes
Ein gut normalisierter Schema kann trotzdem schlecht performen, wenn keine geeigneten Indizes vorhanden sind. Identifizieren Sie Spalten, die häufig in WHERE, JOIN, oder ORDER BYKlauseln verwendet werden und indizieren Sie sie.
🔄 Der iterative Prozess der Gestaltung
Die Datenbankgestaltung ist selten linear. Es ist ein iterativer Prozess. Sie könnten mit einem ERD beginnen, diesen normalisieren, erkennen, dass die Leistung ein Problem darstellt, leicht de-normalisieren und dann den ERD erneut überprüfen, um sicherzustellen, dass die Beziehungen weiterhin korrekt sind.
🔄 Verbesserungsschritte
- Anforderungen überprüfen:Erfordern neue Funktionen neue Tabellen?
- Abfrageanalyse:Schauen Sie sich die langsamsten Abfragen an und identifizieren Sie Engpässe.
- Einschränkungsprüfung:Stellen Sie sicher, dass Fremdschlüssel korrekt definiert sind, um verwaiste Datensätze zu vermeiden.
- Dokumentation:Halten Sie Ihren ERD aktuell. Ein veraltetes Diagramm ist schlimmer als kein Diagramm.
📈 Leistungsüberlegungen
Die Normalisierung befasst sich hauptsächlich mit der Datenintegrität. Die Leistung ist eine separate Überlegung, die oft eine Anpassung erfordert. Die beiden Aspekte sind jedoch miteinander verknüpft.
🚀 Komplexität von JOINs
Sehr normalisierte Datenbanken erfordern mehr JOINOperationen, um verwandte Daten abzurufen. Moderne Datenbank-Engines sind sehr gut darin, JOINs zu optimieren, aber zu viele JOINs können die Latenz dennoch beeinträchtigen.
📦 Speicher-Engine
Verschiedene Speicher-Engines verarbeiten Daten unterschiedlich. Einige bevorzugen zeilenbasierte Speicherung, während andere spaltenbasierte Speicherung bevorzugen. Ihre Normalisierungsstrategie könnte sich je nach zugrundeliegender Engine anpassen müssen.
🔒 Einschränkungen und Trigger
Die Durchsetzung von Normalisierungsregeln über Einschränkungen (wie Fremdschlüssel) gewährleistet die Datenqualität. Eine übermäßige Verwendung von Triggern zur Validierung kann jedoch die Schreibvorgänge verlangsamen. Verwenden Sie sie weise.
🧩 Praxisbeispiel: E-Commerce-Bestellsystem
Betrachten wir ein etwas komplexeres Szenario: einen Online-Shop.
Ursprüngliches ERD-Konzept
Zunächst könnten Sie eine BestellungTabelle haben, die Produktnamen, Preise und Kundendaten enthält. Dies ist der klassische „Flat-File“-Ansatz.
Normalisierter Ansatz
Um dies zu beheben, teilen wir die Daten auf:
- Kunden-Tabelle: Speichert Kundendaten (Name, Adresse, E-Mail).
- Produkte-Tabelle: Speichert Produktinformationen (Name, Preis, Lagerbestand).
- Bestellungen-Tabelle: Speichert die Transaktion (Kunden-ID, Bestelldatum, Gesamtsumme).
- Bestellpositionen-Tabelle: Verknüpft Bestellungen und Produkte (Bestell-ID, Produkt-ID, Menge, Preis zum Zeitpunkt).
Diese Struktur ermöglicht es uns, dass:
- Einen Produktpreis an einer Stelle aktualisieren (die ProdukteTabelle).
- Verfolgen Sie historische Preise in der Bestellpositionen Tabelle (Snapshotting).
- Stellen Sie sicher, dass ein Kunde nicht gelöscht werden kann, wenn er offene Bestellungen hat (über Fremdschlüssel).
🎯 Best-Practices-Checkliste
Führen Sie diese Checkliste aus, bevor Sie Ihr Schema bereitstellen, um Qualität zu gewährleisten.
- ✅ Primärschlüssel: Jede Tabelle verfügt über einen eindeutigen Bezeichner.
- ✅ Fremdschlüssel: Beziehungen sind explizit definiert.
- ✅ Zulässigkeit von NULL-Werten: Spalten werden als
NICHT NULLwo angemessen. - ✅ Daten-Typen: Verwenden Sie den spezifischsten Daten-Typ, der möglich ist.
- ✅ Benennungskonventionen: Verwenden Sie konsistente, klare Namen für Tabellen und Spalten.
- ✅ Dokumentation: Der ERD stimmt mit dem physischen Schema überein.
- ✅ Sicherungsstrategie: Berücksichtigen Sie, wie das Schema die Sicherungs- und Wiederherstellungszeiten beeinflusst.
🔮 Die Zukunft der Datenbankgestaltung
Mit der Entwicklung der Technologie bleiben die grundlegenden Prinzipien der Normalisierung und ERDs relevant. Obwohl NoSQL-Datenbanken Flexibilität bieten, dominiert das relationale Modell nach wie vor transaktionale Systeme. Das Verständnis der Grundlagen ermöglicht es Ihnen, sich an neue Technologien anzupassen, ohne die Disziplin der Datenmodellierung zu verlieren.
Cloud-Datenbanken führen neue Dimensionen ein, wie Sharding und Partitionierung. Doch die logische Struktur, die Sie mithilfe von ERDs und Normalisierung entwerfen, bleibt die Bauplanung dafür, wie diese Daten verteilt und abgerufen werden.
📝 Zusammenfassung der wichtigsten Erkenntnisse
Die Gestaltung effizienter Datenbankstrukturen ist ein Gleichgewicht zwischen Struktur und Flexibilität. Hier sind die Dinge, die Sie sich merken sollten:
- ERDs sind visuelle Leitfäden: Sie zeigen die Beziehungen auf, bevor Sie bauen.
- Die Normalisierung ist strukturell: Sie ordnet die Daten, um Redundanz zu reduzieren.
- 3NF ist das Ziel:Ziel sollte die Dritte Normalform für die meisten transaktionalen Systeme sein.
- Denormalisieren Sie weise:Fügen Sie nur dann Redundanz hinzu, wenn die Leistung es erfordert.
- Iterieren:Das Design ist niemals abgeschlossen; es entwickelt sich mit der Anwendung weiter.
Durch die Kombination der visuellen Klarheit von Entitäts-Beziehungs-Diagrammen mit den strengen Regeln der Normalisierung schaffen Sie eine Datenbasis, die sowohl zuverlässig als auch skalierbar ist. Dieser Ansatz stellt sicher, dass Ihre Datenbank mit Ihrer Anwendung wachsen kann, ohne die Integrität zu verletzen, auch bei steigender Komplexität.
Beginnen Sie mit einem sauberen ERD. Wenden Sie die Normalisierungsregeln schrittweise an. Testen Sie Ihre Abfragen. Optimieren Sie Ihr Schema. Und priorisieren Sie in den frühen Stadien immer die Datenintegrität gegenüber der Geschwindigkeit.