Database design is the backbone of any robust software application. When building systems that handle complex data, the difference between a scalable architecture and a fragile mess often comes down to how you structure information. At the heart of this structure lie three fundamental pillars: entities, attributes, and relationships. Understanding these concepts is not optional for a developer; it is essential for creating maintainable, efficient, and logical data models.
An Entity Relationship Diagram (ERD) serves as the blueprint for these structures. It visualizes how data connects, how it is stored, and how it flows through your system. Without a clear grasp of these core components, even the most advanced application logic will struggle to perform. This guide breaks down each element with precision, ensuring you can design data models with confidence and clarity.
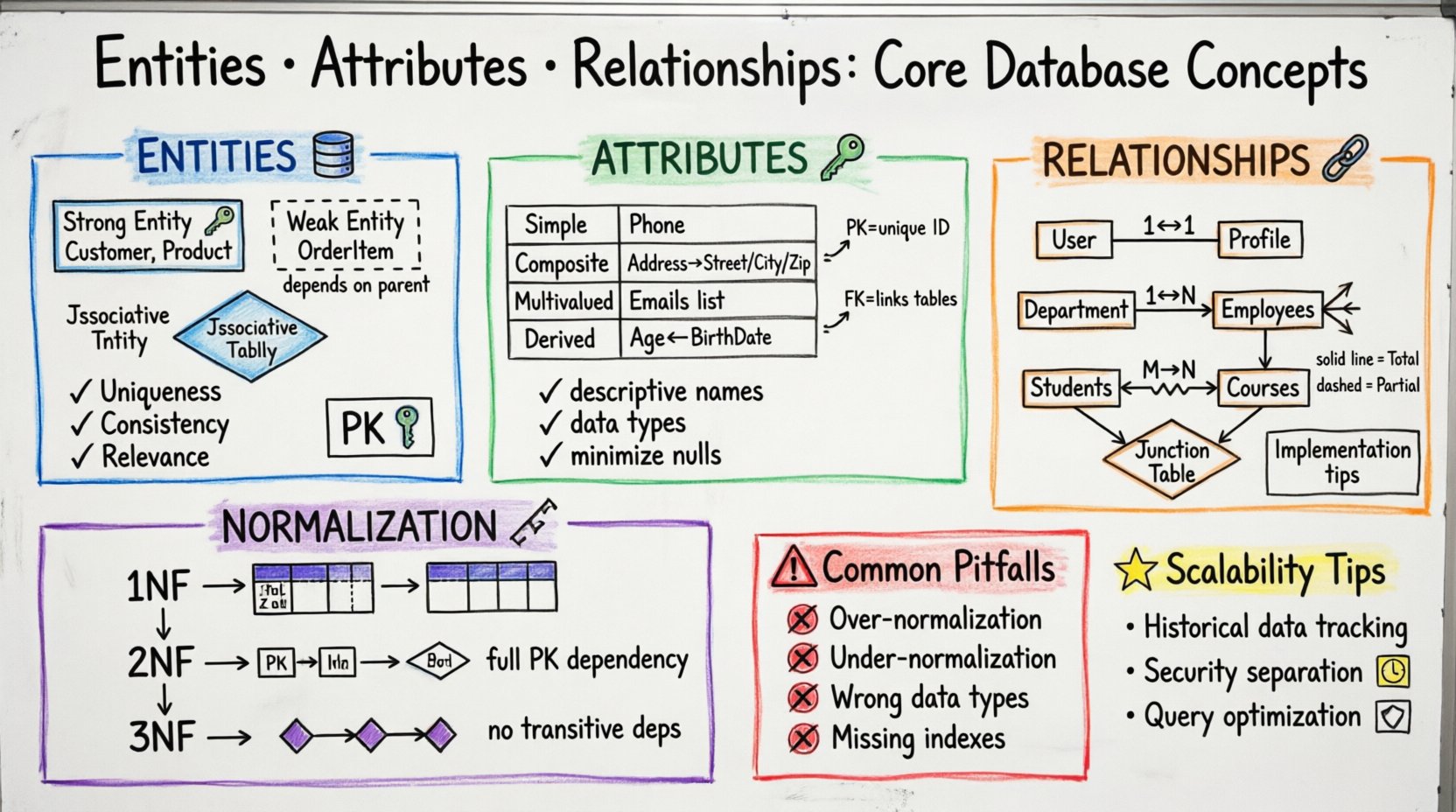
Understanding Entities: The Foundation of Data 🧱
In the context of database design, an entity represents a distinct object or concept about which you need to store information. It is the noun in your data model. Think of it as a category or a class of things that exist in the real world or your business domain. Every entity must be unique and identifiable within the context of the system.
Types of Entities
Entities are not all created equal. Recognizing the type of entity you are dealing with helps in defining the rules for how data is stored and retrieved.
- Strong Entities: These exist independently. They have their own primary key and do not rely on other entities for their existence. For example, a Customer or a Product can exist on their own.
- Weak Entities: These depend on a strong entity for their existence. They cannot be uniquely identified without the parent entity. A classic example is an OrderItem within an Order. Without the order context, the item has no meaning in this specific schema.
- Associative Entities: Also known as junction tables, these resolve many-to-many relationships. They bridge two other entities to allow multiple connections between them.
Identifying Entities
When designing a model, you must ask yourself what real-world objects need to be tracked. Look for nouns in your business requirements. If a business rule dictates that you need to track the status, history, or properties of something, that something is likely an entity.
Consider the following characteristics that define a valid entity:
- Uniqueness: Every instance must be distinguishable from every other instance.
- Consistency: The definition of the entity should remain consistent across the system.
- Relevance: The entity should serve a purpose in the business logic. Avoid creating entities for data that is rarely queried or used.
Attributes: Defining Entity Properties 🔑
Once you have identified the entities, you need to describe them. Attributes are the characteristics, properties, or details that describe an entity. If an entity is a table, an attribute is a column. Together, they form the complete picture of the data you are managing.
Primary Keys and Foreign Keys
Not all attributes are created equal. Some play a critical role in the integrity and linking of data.
- Primary Key (PK): A unique identifier for a record within an entity. It ensures that no two rows are identical. A primary key can be a single column (like an ID number) or a composite key made of multiple columns.
- Foreign Key (FK): An attribute that links to the primary key of another entity. This establishes the relationship between tables. It enforces referential integrity, ensuring that a record in one table cannot reference a non-existent record in another.
Attribute Classifications
Attributes vary in how they are stored and derived. Understanding these distinctions helps in optimizing storage and query performance.
| Type | Description | Example |
|---|---|---|
| Simple | Cannot be divided further. It is atomic. | Phone Number |
| Composite | Can be divided into sub-parts. | Address (Street, City, Zip) |
| Multivalued | Can hold multiple values for a single entity instance. | Email Addresses |
| Derived | Calculated from other attributes. | Age (Derived from Birth Date) |
Best Practices for Attributes
When defining attributes, keep the following guidelines in mind to ensure data quality:
- Use Descriptive Names: Avoid generic names like
col1ordata. Use names that explain the content, such ascustomer_emailororder_date. - Define Data Types: Be precise. Use integers for counts, dates for time-related data, and strings for text. This prevents errors during data entry and retrieval.
- Minimize Null Values: Where possible, enforce constraints so that attributes are not left empty. Null values can complicate queries and lead to unexpected results.
- Normalize Data: Ensure that attributes depend only on the primary key. Avoid storing data that could be derived or moved to another entity.
Relationships: Connecting the Dots 🔗
Entities rarely exist in isolation. Relationships define how entities interact with one another. They dictate how data is linked, how queries are joined, and how integrity is maintained across the database. A well-designed relationship structure prevents data redundancy and ensures that updates propagate correctly.
Cardinality
Cardinality defines the numeric relationship between entities. It answers the question: “How many instances of Entity A relate to how many instances of Entity B?”
- One-to-One (1:1): One instance of Entity A relates to exactly one instance of Entity B. This is rare but occurs in scenarios like a user having one profile.
- One-to-Many (1:N): One instance of Entity A relates to multiple instances of Entity B. For example, one Department has many Employees.
- Many-to-Many (M:N): Multiple instances of Entity A relate to multiple instances of Entity B. For example, a Student can enroll in many Courses, and a Course can have many Students.
Participation Constraints
Cardinality tells you the quantity, but participation constraints tell you if the relationship is mandatory.
- Total Participation: Every instance of an entity must participate in the relationship. For example, every Order must have a Customer.
- Partial Participation: An instance may or may not participate in the relationship. For example, a Customer may or may not have an Order at a given time.
Implementation Strategies
Different cardinalities require different implementation strategies within the data model.
| Relationship Type | Implementation Method | Example Scenario |
|---|---|---|
| 1:1 | Merge tables or add FK to one side. | User Profile linked to User Account. |
| 1:N | Add FK to the “many” side table. | Employee table has a Dept_ID. |
| M:N | Create a junction table with two FKs. | Enrollment table linking Students and Courses. |
Normalization: Structuring for Stability 📐
While entities, attributes, and relationships form the structure, normalization organizes that structure to reduce redundancy and improve integrity. Normalization is a series of steps designed to ensure that data dependencies make sense.
First Normal Form (1NF)
In 1NF, every column must contain atomic values. You cannot store a list of values in a single cell. Every row must be unique, typically enforced by a primary key. This eliminates repeating groups.
Second Normal Form (2NF)
Once 1NF is achieved, 2NF ensures that all non-key attributes are fully dependent on the primary key. If you have a composite key, every attribute must depend on the whole key, not just part of it.
Third Normal Form (3NF)
3NF removes transitive dependencies. Non-key attributes should not depend on other non-key attributes. For example, if City depends on Zip Code, and Zip Code depends on Customer ID, then City depends on Customer ID transitively. To fix this, move City to a separate entity or ensure it is directly linked to the key.
Common Pitfalls in Design ⚠️
Even experienced developers make mistakes when designing data models. Being aware of common pitfalls can save significant time during the development phase.
- Over-normalization: Splitting data into too many small entities can make queries complex and slow. Sometimes, denormalization is acceptable for read-heavy workloads.
- Under-normalization: Storing the same data in multiple places leads to inconsistency. If a customer address changes, you must update it in every record. This increases the risk of errors.
- Ignoring Data Types: Using strings for numbers or dates leads to sorting issues and validation errors. Always match the attribute type to the actual data.
- Hardcoded Values: Avoid storing status codes as strings if they have specific meanings. Use reference tables for values like “Status” or “Country” to maintain consistency.
- Missing Indexes: Foreign keys and frequently queried attributes should be indexed to improve lookup speeds. Without indexes, join operations can become bottlenecks.
Advanced Considerations for Scalability 🚀
As applications grow, the data model must evolve. Early design decisions impact how easily the system can scale. Here are considerations for long-term stability.
Handling Historical Data
Business rules change over time. Attributes that were once mandatory might become optional. Relationships might shift. Instead of constantly altering the schema, consider adding columns for history or using temporal tables to track changes over time. This allows you to audit changes without breaking current functionality.
Security and Access Control
Entities often contain sensitive information. Design your relationships to support access control. For instance, separating User data from Logs data can help in managing permissions. Ensure that foreign keys do not expose sensitive data to unauthorized users.
Query Performance
The way you structure relationships directly affects query performance. Deeply nested relationships require multiple joins, which can slow down data retrieval. Analyze your most frequent queries and structure your entities to minimize the number of joins required. Sometimes, denormalizing specific attributes into a read-optimized store is the right choice.
Conclusion 🏁
Mastering the core concepts of entities, attributes, and relationships is a journey that continues throughout your career. These elements are not just theoretical constructs; they are the practical tools you use to build systems that endure. By focusing on clarity, integrity, and efficiency, you create data models that support your applications for years to come.
Start with the basics. Define your entities clearly. Assign attributes that describe them accurately. Map relationships that reflect real-world interactions. As you refine these designs, you will find that the logic of your application becomes cleaner and more robust. Remember that a good design is one that is easy to understand and easy to change. Keep these principles in mind as you move forward with your development work.
Investing time in proper ERD design pays dividends in reduced bugs, faster development cycles, and a more maintainable codebase. Whether you are building a small utility or a large-scale enterprise system, the rules of entities, attributes, and relationships remain the same. Stick to the fundamentals, and your data architecture will stand the test of time.