











En la arquitectura compleja del diseño de bases de datos, pocas concepciones desafían a los ingenieros tanto como la entidad de referencia propia. También conocida como relación recursiva, este patrón permite que una tabla se enlace a sí misma, lo que permite modelar jerarquías y estructuras complejas dentro de un esquema plano. Comprender cómo implementar esto correctamente es crucial para mantener la integridad de los datos y el rendimiento de las consultas.
Al diseñar un Diagrama de Relación de Entidades (ERD), la mayoría de las relaciones conectan dos entidades distintas. Sin embargo, los datos del mundo real a menudo exigen que una sola entidad se relacione consigo misma. Un gerente gestiona empleados, una categoría contiene subcategorías y un producto puede formar parte de un kit. Estos escenarios requieren una relación recursiva.
Esta guía explora la mecánica, los patrones de diseño y las mejores prácticas para manejar entidades de referencia propia. Examinaremos cómo estructurar estas relaciones sin depender de herramientas de software específicas, centrándonos en principios universales de bases de datos.
🧐 ¿Qué es una entidad de referencia propia?
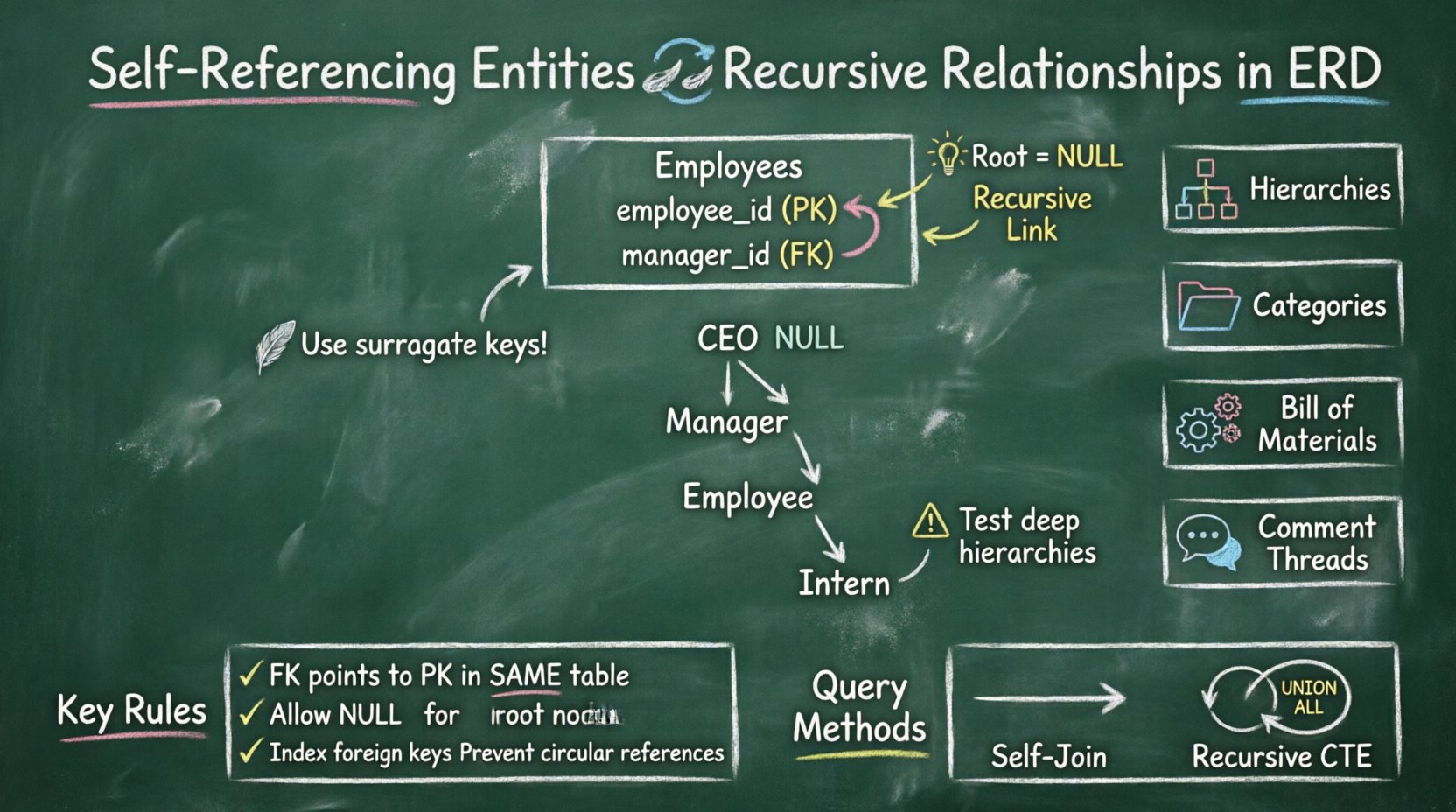
Una entidad de referencia propia ocurre cuando una clave foránea en una tabla apunta a la clave primaria de la misma tabla. Esto crea un bucle en el que las filas de datos dentro de una sola tabla pueden referirse a otras filas dentro de la misma tabla. Es una técnica fundamental para modelar estructuras de datos jerárquicas.
Características clave:
- Tabla única: La relación existe completamente dentro de una estructura de tabla.
- Enlace padre-hijo: Una fila actúa como padre, mientras que otra actúa como hijo.
- Manejo de valores nulos: La raíz de la jerarquía normalmente tiene un valor nulo en la columna de clave foránea.
- Lógica circular: Se debe tener cuidado para evitar bucles infinitos durante la recuperación de datos.
🏗️ Componentes principales de las relaciones recursivas
Para implementar esta relación de forma eficaz, deben alinearse componentes específicos de la base de datos. El diseño de esquema depende en gran medida de la interacción entre claves primarias y claves foráneas.
🔑 La clave primaria
Cada fila en la tabla debe tener un identificador único. Este es el punto de anclaje. Cuando una fila hace referencia a otra fila, lo hace almacenando el identificador único de la fila padre.
- Debe ser estable. Cambiar una clave primaria es una operación compleja.
- Debe estar indexada para un rendimiento rápido de búsqueda.
- Comúnmente, esto es un entero autoincremental o un UUID.
🔗 La clave foránea
La columna de clave foránea reside en la misma tabla que la clave primaria. Almacena el valor de la clave primaria de la fila padre. Esta columna define la dirección de la relación.
- Nullable:En una jerarquía, el elemento de nivel superior (la raíz) no tiene padre. Por lo tanto, esta columna debe permitir valores nulos.
- Restricción: Una restricción de clave foránea garantiza que el valor almacenado coincida con una clave primaria existente en la misma tabla.
- Indexación: Aunque no siempre es obligatorio, indexar la columna de clave foránea acelera significativamente las consultas que recorren la jerarquía.
📐 Visualización en un Diagrama de Relación de Entidades
Cuando se dibuja un DER para representar una entidad que se referencia a sí misma, la notación puede resultar confusa a primera vista. Las herramientas estándar de DER utilizan líneas específicas para indicar la conexión.
Reglas de notación visual:
- La caja de la entidad se dibuja una sola vez.
- Una línea de relación conecta la clave primaria con la clave foránea dentro de la misma caja.
- La línea a menudo vuelve a la entidad, creando un círculo visual.
- Los marcadores de cardinalidad (1:1, 1:M) se colocan en la línea para indicar cuántos hijos puede tener un padre.
Ejemplo: Estructura organizacional
| Concepto | Descripción | Notación DER |
|---|---|---|
| Empleado | La entidad que se está modelando | Caja etiquetada como “Empleado” |
| Gerente | El rol que hace referencia a la misma tabla | Línea desde ID de Gerente hasta ID de Empleado |
| Línea de informe | La relación recursiva | Flecha que vuelve sobre sí misma |
| Nodo raíz | CEO o jefe de nivel superior | Valor nulo en ID de Gerente |
🌳 Casos de uso comunes para datos recursivos
Las relaciones recursivas no son teóricas; resuelven problemas concretos en el modelado de datos. Aquí tienes los escenarios más frecuentes donde se aplica este patrón.
1️⃣ Jerarquías organizacionales
Toda empresa tiene una estructura. Los empleados informan a gerentes, quienes informan a directores, quienes informan a vicepresidentes. Esta cadena es una estructura de árbol clásica.
- Modelo de datos: Una tabla llamada “Empleados”.
- Columnas:
id_empleado,nombre,id_jefe. - Lógica: El
id_jefela columna hace referencia aid_empleado. - Beneficio: Agregar un nuevo empleado solo requiere insertar una fila. No es necesario crear una tabla nueva para cada departamento.
2️⃣ Árboles de categorías
Las plataformas de comercio electrónico organizan con frecuencia los productos en categorías anidadas. Electrónica > Computadoras > Laptops.
- Modelo de datos: Una tabla llamada “Categorías”.
- Columnas:
id_categoria,nombre,id_padre. - Lógica: Una categoría puede tener un padre, o puede ser una categoría raíz (id_padre es nulo).
- Beneficio: Flexibilidad para agregar tantas subcategorías como se necesiten sin modificar el esquema.
3️⃣ Lista de materiales (BOM)
La fabricación a menudo requiere listas de piezas complejas. Un automóvil está compuesto por motores, que a su vez están compuestos por pistones. A veces, un pistón forma parte de un tipo de motor diferente.
- Modelo de datos: Una tabla llamada “Piezas”.
- Columnas:
id_pieza,descripción,id_ensamblaje. - Lógica: Una pieza puede ser un ensamblaje en sí mismo, que contiene otras piezas.
- Beneficio: Permite estructuras de fabricación de múltiples niveles.
4️⃣ Hilos de comentarios
Los foros y blogs permiten a los usuarios responder a comentarios. Un comentario puede tener un comentario padre al que responde, o puede ser un comentario independiente.
- Modelo de datos: Una tabla llamada “Comentarios”.
- Columnas:
id_comentario,id_usuario,contenido,id_comentario_padre. - Lógica: Una respuesta se vincula de nuevo al ID del comentario original.
- Beneficio: Soporta anidamiento infinito de discusiones.
⚙️ Consideraciones de implementación
Diseñar el esquema es solo el primer paso. Asegurar que los datos se comporten correctamente bajo diversas condiciones requiere una planificación cuidadosa.
🛑 Evitando referencias circulares
Un riesgo crítico en las relaciones recursivas es crear un ciclo. Por ejemplo, el empleado A gestiona al empleado B, y el empleado B gestiona al empleado A. Esto crea un bucle infinito.
- Lógica de la aplicación: Al insertar o actualizar datos, la aplicación debe verificar la profundidad de la jerarquía para asegurarse de que no se formen ciclos.
- Restricciones de la base de datos: Aunque las restricciones estándar de SQL no pueden prevenir fácilmente los ciclos (ya que verifican el estado actual, no el estado resultante), en algunos sistemas se pueden usar desencadenadores para validar la ruta antes de escribir.
- Identificación de la raíz: Asegúrese de que cada árbol válido tenga exactamente un nodo raíz (donde la clave foránea es nula).
📉 Manejo de valores nulos
La raíz de la jerarquía es el punto de partida. En una relación recursiva estándar, la fila raíz tiene un valor nulo en la columna de clave foránea.
- Consulta: Para encontrar todos los nodos raíz, consulte las filas donde la clave foránea sea NULL.
- Valores por defecto: No establezca un valor por defecto para la clave foránea si implica un padre. Un valor por defecto de 0 o -1 puede ser engañoso y causar problemas de integridad de datos.
- Integridad: Asegúrese de que el motor de base de datos permita valores nulos en la columna de clave foránea. Una restricción NOT NULL romperá el modelo de jerarquía.
📈 Rendimiento e índices
A medida que los datos crecen, las consultas en estructuras recursivas pueden volverse lentas. Una consulta simple para encontrar todos los descendientes de un nodo específico puede requerir muchas uniones o consultas recursivas.
Estrategias de optimización:
- Índice en claves foráneas: Cree un índice en la columna que almacena la referencia al padre. Esto acelera la búsqueda de hijos.
- Rutas materializadas: Algunos sistemas almacenan la ruta completa de la jerarquía en una columna separada (por ejemplo, “/1/5/12/20”). Esto permite una filtración más rápida basada en cadenas, aunque requiere actualizaciones en cada inserción.
- Conjuntos anidados: Un algoritmo alternativo que utiliza números izquierdo y derecho para representar la profundidad. Es más rápido para la recuperación, pero más lento para la inserción.
- Profundidad de la consulta: Límite la profundidad de recursión en sus consultas. Los bucles infinitos pueden hacer que el motor de base de datos se bloquee si no se limitan.
🔍 Consulta de datos recursivos
Recuperar datos jerárquicos es más complejo que recuperar datos planos. Las uniones estándar funcionan para un nivel, pero múltiples niveles requieren lógica especializada.
🔄 Uniones autoenlazadas
El método más común implica unir la tabla consigo misma. Alias la tabla una vez como padre y otra vez como hijo.
- Un nivel:Une la tabla consigo misma una vez para obtener el padre inmediato.
- Varios niveles:Requiere múltiples uniones, lo cual se vuelve difícil de manejar rápidamente.
- Desventaja:El número de uniones requeridas es igual a la profundidad de la jerarquía.
🔁 Expresiones de tabla común recursivas (CTEs)
Los motores de bases de datos modernos admiten CTEs recursivas. Esto permite que una consulta se ejecute con UNION ALL contra sí misma hasta que no se encuentren más filas.
- Miembro ancla:El punto de partida de la recursión (normalmente el nodo raíz).
- Miembro recursivo:La parte de la consulta que une el resultado de nuevo con la tabla para encontrar el siguiente nivel.
- Terminación:La consulta se detiene cuando ya no se encuentran filas coincidentes.
- Beneficio:Maneja cualquier profundidad de jerarquía sin necesidad de conocerla de antemano.
🛡️ Integridad de datos y restricciones
Mantener la integridad de una tabla auto-referenciada es vital. Si se elimina un padre, ¿qué sucede con los hijos?
🗑️ Eliminación en cascada
Cuando se elimina una fila padre, la base de datos debe decidir cómo manejar las filas hijas.
- RESTRICT:Evita la eliminación del padre si existen hijos. Esto preserva los datos, pero podría bloquear una limpieza necesaria.
- CASCADE:Elimina todas las filas hijas cuando se elimina el padre. Esto es peligroso en jerarquías profundas, ya que puede borrar grandes porciones de datos accidentalmente.
- SET NULL:Establece la clave foránea de los hijos en NULL, convirtiéndolos en nuevos nodos raíz. Esta es a menudo la opción más segura para preservar la estructura de datos.
- ESTABLECER VALOR POR DEFECTO: Establece la clave foránea con un valor predeterminado (por ejemplo, una categoría huérfana específica).
🔒 Restricciones de actualización
Cambiar la clave primaria de una fila padre es arriesgado. Si cambias el ID de un gerente, debes actualizar ese ID en todos los registros de empleados que los referencian.
- Capa de aplicación: Maneja la actualización de forma transaccional para garantizar que todas las referencias se actualicen juntas.
- Disparadores de base de datos: Puede automatizar la propagación de cambios de ID, aunque esto añade complejidad.
- Mejor práctica: Evita actualizar claves primarias en estructuras recursivas siempre que sea posible. Usa claves de sustitución (enteros autoincrementales) en lugar de claves naturales (como códigos de empleados).
🚧 Solución de problemas comunes
Aunque se tenga un diseño cuidadoso, pueden surgir problemas durante el desarrollo y la mantenimiento.
❓ ¿Cómo hallo la profundidad de un árbol?
Para determinar el nivel de una fila específica, debes recorrer hacia arriba desde la fila hasta la raíz. Cuenta el número de saltos.
- Enfoque de consulta: Usa una consulta recursiva que cuente las filas mientras avanza hacia arriba.
- Enfoque de aplicación: Almacena la profundidad en una columna durante la inserción. Esto ahorra tiempo de consulta, pero requiere mantenimiento.
❓ ¿Cómo manejo los nodos huérfanos?
Los nodos huérfanos son filas donde la clave foránea apunta a un padre inexistente. Esto suele ocurrir debido a errores de programación o errores de entrada de datos manual.
- Validación: Ejecuta comprobaciones periódicas de integridad para encontrar filas donde la clave foránea no coincida con ninguna clave primaria.
- Recuperación: Decide una política: móvelos a una categoría raíz, elimínalos o señálalos para revisión.
❓ Degradación del rendimiento con el tiempo
A medida que el árbol crece, las consultas que escanean todo el árbol se vuelven más lentas.
- Caché: Almacena en caché las estructuras jerárquicas frecuentemente accedidas en la memoria de la aplicación.
- Archivado: Mueve las partes históricas o inactivas de la jerarquía a tablas de archivo.
- Particionado: Si los datos son masivos, particione la tabla por categoría raíz.
📝 Resumen de las mejores prácticas
Para garantizar una implementación sólida de entidades auto-referenciadas, siga estas directrices.
- Use claves de sustitución:Prefiera enteros autoincrementales sobre claves de negocio para la clave primaria.
- Permita valores nulos:Asegúrese de que la columna de clave foránea permita valores nulos para los nodos raíz.
- Indexe las claves foráneas:Siempre indexe la columna que contiene la referencia al padre.
- Valide los ciclos:Implemente comprobaciones para evitar referencias cíclicas (A -> B -> A).
- Límite de recursión:Límite la profundidad de recursión en las consultas para evitar desbordamientos de pila.
- Documente el esquema:Marque claramente qué columnas son auto-referenciadas en su documentación de ERD.
- Planifique la eliminación:Defina reglas claras para eliminaciones en cascada o establecer valores nulos al eliminar el padre.
- Pruebe jerarquías profundas:Pruebe sus consultas con al menos 10 niveles de profundidad para asegurar que el rendimiento se mantenga.
🔮 Consideraciones futuras
La tecnología de bases de datos sigue evolucionando. Mientras que el concepto de una entidad auto-referenciada permanece constante, las herramientas para gestionarla están mejorando.
- Bases de datos de grafos: Algunos sistemas modernos tratan las relaciones como ciudadanos de primera clase. Manejan los caminos recursivos de forma nativa sin la complejidad de SQL.
- Soporte para JSON:Los motores de bases de datos más recientes permiten almacenar datos jerárquicos en columnas JSON, lo que puede simplificar el diseño de esquemas para estructuras profundamente anidadas.
- Mejoras en los ORM:Los mapeadores objeto-relacionales están mejorando en el manejo automático de relaciones recursivas, reduciendo el código repetitivo.
A pesar de estos avances, la lógica fundamental de la relación recursiva permanece igual. Comprender los mecanismos subyacentes de las claves primarias, claves foráneas y relaciones entre tablas es esencial para cualquier profesional técnico que trabaje con estructuras de datos.
Siguiendo estos principios, puede construir sistemas lo suficientemente flexibles para manejar jerarquías complejas, al tiempo que permanecen eficientes y mantenibles. La entidad auto-referenciada es una herramienta poderosa en su arsenal de modelado de datos, siempre que se utilice con precisión y cuidado.