











Construir una tienda en línea robusta requiere más que solo una interfaz de frontend. La columna vertebral de cualquier mercado digital exitoso reside en su arquitectura de datos. Un diagrama entidad-relación (ERD) sirve como plano maestro para cómo se almacena, relaciona y recupera la información. Al diseñar para escalar, la complejidad aumenta significativamente. Debes equilibrar la integridad de los datos con el rendimiento, asegurando que cada transacción se procese sin problemas incluso bajo carga pesada.
Esta guía explora los componentes críticos del diseño de bases de datos para comercio electrónico. Examinaremos las entidades principales, sus relaciones y los patrones necesarios para soportar tráfico de alto volumen. Al seguir estos principios estructurales, podrás construir un sistema que permanezca estable conforme crece tu base de clientes. El enfoque está en el diseño lógico, la normalización y las estrategias que previenen cuellos de botella antes de que ocurran.
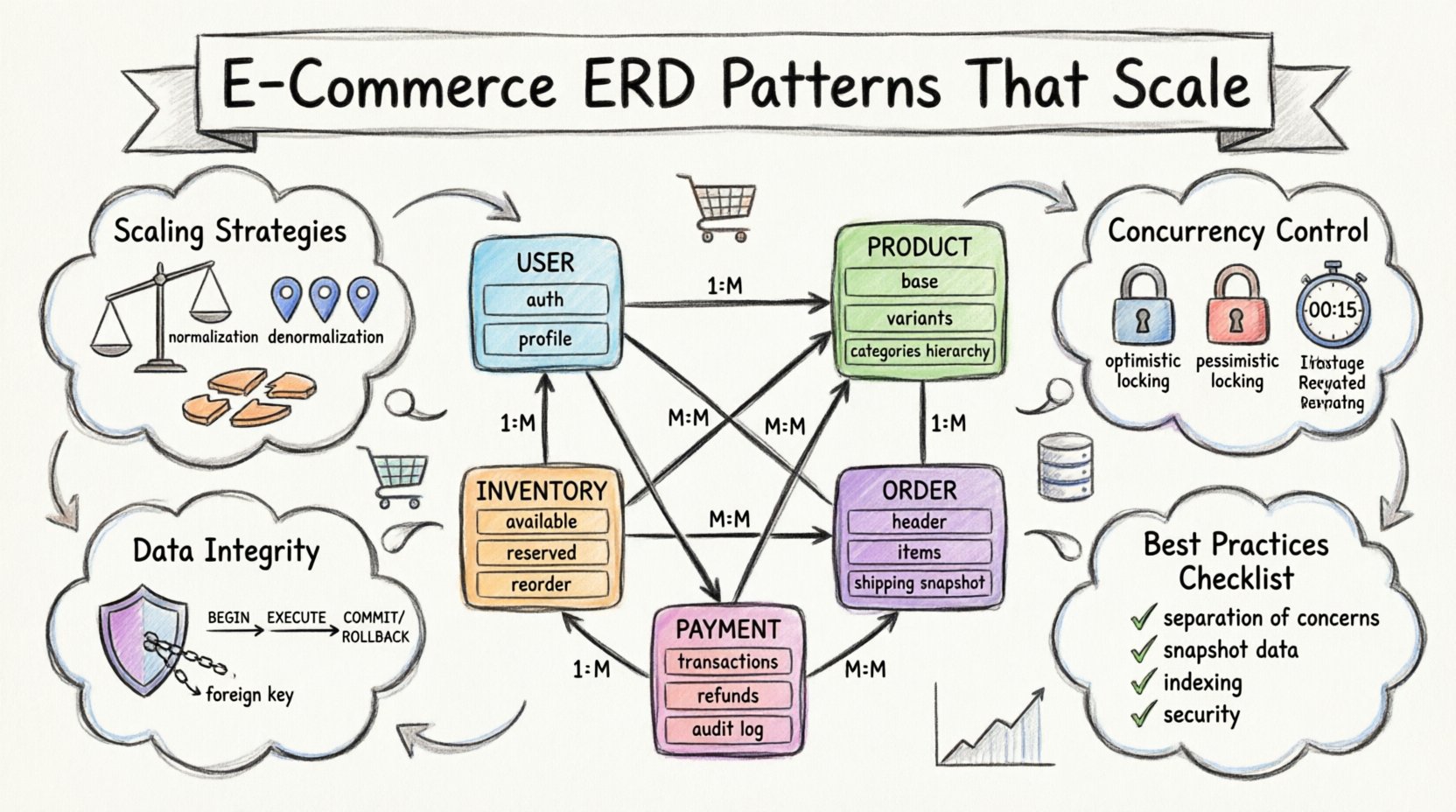
Entidades fundamentales y relaciones principales 🏗️
Cada plataforma de comercio electrónico comienza con los puntos de datos fundamentales que definen el negocio. Estos incluyen quiénes son los clientes, qué compran y cómo se categorizan los artículos. El diseño de estas tablas principales determina la flexibilidad de todo el sistema.
1. La entidad de usuario
La tabla de usuarios es el punto de entrada para la autenticación y la gestión de perfiles. Sin embargo, separar las credenciales de autenticación de los detalles del perfil del usuario es un patrón común. Esta separación permite actualizaciones de seguridad sin interrumpir la estructura general de los datos del usuario.
- Datos de autenticación:Almacena credenciales, tokens de sesión y estado de la cuenta. Estos datos requieren alta seguridad y exposición mínima.
- Datos del perfil:Contiene nombres, información de contacto y preferencias de envío. Estos datos se actualizan con mayor frecuencia.
- Relaciones:Existe una relación uno a muchos entre usuarios y su historial de pedidos. Cada usuario puede tener múltiples pedidos, pero un pedido pertenece a exactamente un usuario.
Es importante considerar las regulaciones de privacidad en esta etapa. Almacenar información personalmente identificable (PII) requiere un manejo específico. El cifrado en reposo y controles de acceso estrictos son prácticas estándar para esta entidad.
2. El catálogo de productos
La gestión de productos suele ser la parte más compleja del esquema de comercio electrónico. Un artículo físico único podría existir en múltiples variaciones, como tamaño o color. Esto requiere una estructura flexible que no necesite cambios constantes en el esquema.
- Tabla base de productos:Almacena información general como título, descripción y precio base.
- Tabla de variantes:Almacena atributos específicos como SKU, color, tamaño y precios individuales.
- Tabla de categorías:Define la jerarquía. Las categorías pueden estar anidadas, lo que requiere una relación auto-referencial o una estrategia de enumeración de rutas.
Aquí a menudo se considera la denormalización. Aunque la normalización reduce la redundancia, leer datos para una página de lista de productos requiere unir múltiples tablas. En escenarios de alto tráfico, cachear los datos unidos o denormalizar campos específicos puede mejorar la velocidad de consulta.
3. Gestión de inventario y stock
Seguimiento de los niveles de stock es crítico para evitar la venta excesiva. La tabla de inventario debe vincularse directamente a las variantes de productos. Debe almacenar la cantidad disponible actual, la cantidad reservada y la capacidad total.
- Stock disponible:La cantidad de artículos listos para ser comprados de inmediato.
- Stock reservado:Artículos mantenidos en el carrito de un cliente durante el proceso de pago.
- Punto de reorden: Un umbral que desencadena alertas para reabastecimiento.
La concurrencia es un gran desafío aquí. Si dos usuarios intentan comprar el último artículo al mismo tiempo, el sistema debe evitar que ambos tengan éxito. Esto generalmente implica transacciones de base de datos que bloquean la fila específica del inventario durante el proceso de actualización.
Arquitectura transaccional y procesamiento de pedidos 🛒
El ciclo de vida del pedido es el latido del plataforma. Representa el movimiento de valor desde el cliente hasta el comerciante. El diseño de la base de datos debe soportar los cambios de estado que ocurren desde el carrito hasta la entrega.
Estructura de la entidad de pedido
Un registro de pedido es una instantánea de la transacción en un momento específico. No debe referirse simplemente al precio actual del producto. Si el precio cambia después de que se haya colocado el pedido, el registro histórico debe mantenerse preciso.
- Encabezado del pedido: Contiene el ID del pedido, el ID del usuario, el monto total, el impuesto, el costo de envío y el estado del pedido.
- Artículos del pedido: Una tabla de unión que vincula pedidos con productos. Esta tabla registra la variante específica, la cantidad y el precio en el momento de la compra.
- Dirección de envío: Almacenar la dirección en el momento del pedido es más seguro que vincularla con el perfil actual de dirección del usuario.
Gestión de estado
Los pedidos pasan por diversos estados. Un campo de estado bien diseñado permite al sistema rastrear el progreso sin requerir uniones complejas. Los estados comunes incluyen:
- Pendiente: Pedido creado pero aún no pagado.
- Pagado: Pago confirmado.
- En proceso: Inventario asignado y en preparación.
- Enviado: Artículo enviado con información de seguimiento.
- Entregado: El cliente recibió el artículo.
- Reembolsado: Dinero devuelto al cliente.
Usar un tipo enumerado para el estado garantiza la consistencia de los datos. Evita errores tipográficos que podrían romper los scripts de automatización que dependen de valores específicos de estado.
Registros de pago y financieros 💳
Los datos financieros requieren el más alto nivel de precisión. No puedes confiar únicamente en la lógica estándar de la aplicación para el dinero. La base de datos debe registrar la transacción financiera como un evento distinto.
- Transacciones de pago:Cada intento de pago debe crear un registro. Esto incluye la respuesta de la pasarela, el método utilizado y el resultado final.
- Reembolsos:Un reembolso es una transacción independiente vinculada al pago original. No debe simplemente anular el registro original.
- Cálculos de impuestos:Las tasas de impuestos varían según la ubicación. Almacenar el monto de impuesto aplicado por artículo del pedido garantiza trazabilidad.
El registro de auditoría es esencial aquí. Cada cambio en un registro financiero debe registrarse con una marca de tiempo y el ID de usuario que realiza la acción. Esto proporciona una huella para la resolución de disputas y auditorías internas.
Estrategias de escalado para alto volumen 📈
A medida que el tráfico crece, la base de datos se convierte en un cuello de botella. La escalabilidad estándar implica escalado vertical (agregar más potencia a un servidor único), pero esto tiene límites. El escalado horizontal (agregar más servidores) requiere una planificación cuidadosa de la distribución de datos.
1. Normalización frente a denormalización
La normalización reduce la duplicación de datos. Es el estándar para la integridad transaccional. Sin embargo, las consultas complejas que unen muchas tablas pueden volverse lentas a medida que aumenta el volumen de datos.
| Estrategia | Beneficio | Inconveniente |
|---|---|---|
| Normalización | Consistencia de datos, menor almacenamiento | Consultas complejas, lecturas más lentas |
| Denormalización | Lecturas más rápidas, consultas más simples | Redundancia de datos, complejidad de actualización |
En comercio electrónico, a menudo es mejor un enfoque híbrido. Mantenga las tablas transaccionales principales normalizadas para garantizar la integridad. Cree vistas denormalizadas o tablas separadas para fines de informes y búsqueda. Esto permite una navegación rápida de productos sin comprometer la precisión del procesamiento de pedidos.
2. Estrategias de indexación
Los índices son cruciales para el rendimiento. Permiten a la base de datos encontrar filas sin escanear toda la tabla. Sin embargo, demasiados índices ralentizan las operaciones de escritura.
- Claves primarias:Siempre indexadas. Se utilizan para búsquedas directas por ID.
- Claves foráneas:A menudo indexadas para acelerar las uniones entre tablas relacionadas.
- Índices compuestos:Útiles para consultas que filtran por múltiples columnas, como estado y fecha.
- Índices de texto completo:Esenciales para la funcionalidad de búsqueda de productos.
Revise los planes de ejecución de consultas con regularidad. Si una consulta no está utilizando un índice, la base de datos podría estar realizando una escaneo completo de la tabla, lo que degrada el rendimiento a medida que crece el conjunto de datos.
3. Particionamiento y fragmentación
Cuando una sola tabla se vuelve demasiado grande, el particionamiento la divide en piezas más pequeñas y manejables. Esto suele hacerse por fecha o por rango de ID.
- Particionamiento por rango:Dividir los pedidos por año o mes. Esto mantiene los datos recientes en almacenamiento más rápido mientras se archivan los datos antiguos.
- Particionamiento por hash:Distribuir los datos entre múltiples servidores basándose en un hash del ID. Esto distribuye la carga de forma equilibrada.
La fragmentación lleva esto más lejos al distribuir los datos entre múltiples servidores físicos. Esto requiere que la aplicación conozca qué fragmento contiene los datos. Es una decisión arquitectónica compleja que se debe implementar mejor después de agotar la escalabilidad vertical.
Integridad de datos y restricciones 🔒
Las bases de datos relacionales ofrecen restricciones potentes para mantener la calidad de los datos. Depender del código de la aplicación para imponer reglas es arriesgado, ya que el código puede tener errores. Las restricciones de la base de datos proporcionan una red de seguridad.
1. Integridad referencial
Las restricciones de clave foránea garantizan que un pedido siempre se enlace con un usuario y un producto válidos. Si se elimina un producto, la base de datos se puede configurar para evitar la eliminación o propagar la acción a los registros dependientes. En comercio electrónico, generalmente es más seguro evitar la eliminación de productos que tienen pedidos existentes.
2. Atomicidad transaccional
Una transacción agrupa múltiples operaciones en una unidad única. O todas las operaciones tienen éxito, o ninguna lo hace. Esto es vital para las actualizaciones de inventario. Cuando se coloca un pedido, el inventario debe disminuir. Si la actualización del inventario falla, el registro del pedido no debería crearse.
- Iniciar transacción:Bloquea los recursos relevantes.
- Ejecutar actualizaciones:Realizar las escrituras necesarias.
- Confirmar:Hace que los cambios sean permanentes.
- Deshacer:Deshace los cambios si ocurre un error.
3. Restricciones únicas
Las restricciones únicas evitan entradas duplicadas. Esto es útil para direcciones de correo electrónico en la tabla de usuarios o códigos SKU en la tabla de productos. Evita que el sistema cree accidentalmente cuentas duplicadas o artículos de inventario conflictivos.
Manejo de alta concurrencia ⚡
Las ventas flash y los eventos de alta tráfico generan condiciones de carrera. Varios usuarios podrían intentar comprar el mismo artículo en el mismo milisegundo exacto.
Bloqueo optimista
El bloqueo optimista asume que los conflictos son raros. Implica agregar un número de versión a la fila. Al actualizar, la base de datos verifica si el número de versión coincide. Si ha cambiado, la actualización se rechaza y la aplicación debe volver a intentarlo.
Bloqueo pesimista
El bloqueo pesimista bloquea la fila inmediatamente al leerla. Otras transacciones deben esperar hasta que se libere el bloqueo. Esto garantiza la consistencia de los datos, pero puede reducir el rendimiento durante altas contiendas.
Reserva de inventario
Para evitar la venta excesiva, reserva el inventario cuando el usuario agrega un artículo al carrito. Establece un tiempo de espera para esta reserva. Si el usuario no completa la compra dentro del límite de tiempo, el inventario se libera de nuevo al grupo disponible.
Consideraciones sobre búsqueda y análisis 📊
Las bases de datos transaccionales no están diseñadas para consultas analíticas complejas ni para búsquedas de texto completo. Ejecutar consultas de búsqueda pesadas en las tablas principales de pedidos o productos puede degradar el rendimiento para los usuarios regulares.
- Motores de búsqueda:Utiliza un motor de búsqueda dedicado para la búsqueda de productos. Sincroniza los datos de productos desde la base de datos principal con el motor de búsqueda de forma asíncrona.
- Almacenes analíticos:Mueve los datos históricos a un almacén analítico independiente para informes. Esto mantiene la base de datos transaccional ligera.
- Replicas de lectura:Dirige el tráfico de solo lectura a servidores réplica. Esto separa la carga del servidor principal de escritura.
Al separar las operaciones intensivas de escritura de las intensivas de lectura, garantizas que el proceso de compra permanezca rápido incluso cuando los usuarios están navegando o generando informes.
Mantenimiento y crecimiento a largo plazo 🔄
Un diseño de base de datos no es estático. Debe evolucionar con el negocio. A medida que se agregan nuevas funciones, es posible que el esquema necesite ajustes.
- Versionado:Lleva un registro de las versiones del esquema. Esto permite realizar reintegros seguros si una migración falla.
- Archivado:Mueve los pedidos antiguos a almacenamiento frío. Esto mantiene el tamaño de las tablas activas manejable.
- Monitoreo:Configura alertas para consultas lentas, esperas de bloqueos y uso del espacio en disco. El monitoreo proactivo previene interrupciones.
Revisa periódicamente el diagrama ER con respecto a los patrones de uso reales. Algunas relaciones que parecían buenas en papel pueden demostrarse ineficientes en producción. Esté preparado para refactorizar cuando los patrones de datos cambien significativamente.
Resumen de las mejores prácticas ✅
Diseñar una base de datos de comercio electrónico escalable requiere un equilibrio entre estructura y flexibilidad. Los siguientes puntos resumen las principales conclusiones para construir un sistema resiliente.
- Separación de responsabilidades:Mantén la autenticación, el catálogo y los datos de transacciones separados.
- Datos de instantánea:Almacena los detalles del pedido en el momento de la compra, no solo referencias.
- Control de concurrencia:Utiliza transacciones y bloqueos para evitar la venta excesiva.
- Indexación:Optimiza para los patrones de lectura y escritura más comunes.
- Escalabilidad:Planifique la partición y el fraccionamiento desde temprano en la arquitectura.
- Seguridad:Cifre los datos sensibles y aplique controles de acceso estrictos.
Al adherirse a estos patrones, crea una base que respalda el crecimiento. La base de datos se convierte en un motor estable que impulsa el negocio sin requerir reparaciones constantes de emergencia. Enfóquese primero en la integridad de los datos, luego optimice para velocidad. Un sistema lento es mejor que uno incorrecto.