











Construir un sistema de bases de datos es similar a construir la fundación de un rascacielos. Si el plano está defectuoso, la estructura eventualmente se agrietará bajo presión. Un Diagrama de Entidad-Relación (ERD) es ese plano. Define cómo se conectan, fluyen y persisten los datos dentro de su aplicación. A medida que crece su base de usuarios y la cantidad de datos explota, un diseño estático a menudo se convierte en un cuello de botella. Para garantizar longevidad, debe adoptar desde el principio principios de diseño escalables de ERD. Esta guía explora las estrategias técnicas necesarias para construir sistemas que perduren.
Comprendiendo el núcleo de la modelización de datos 🧱
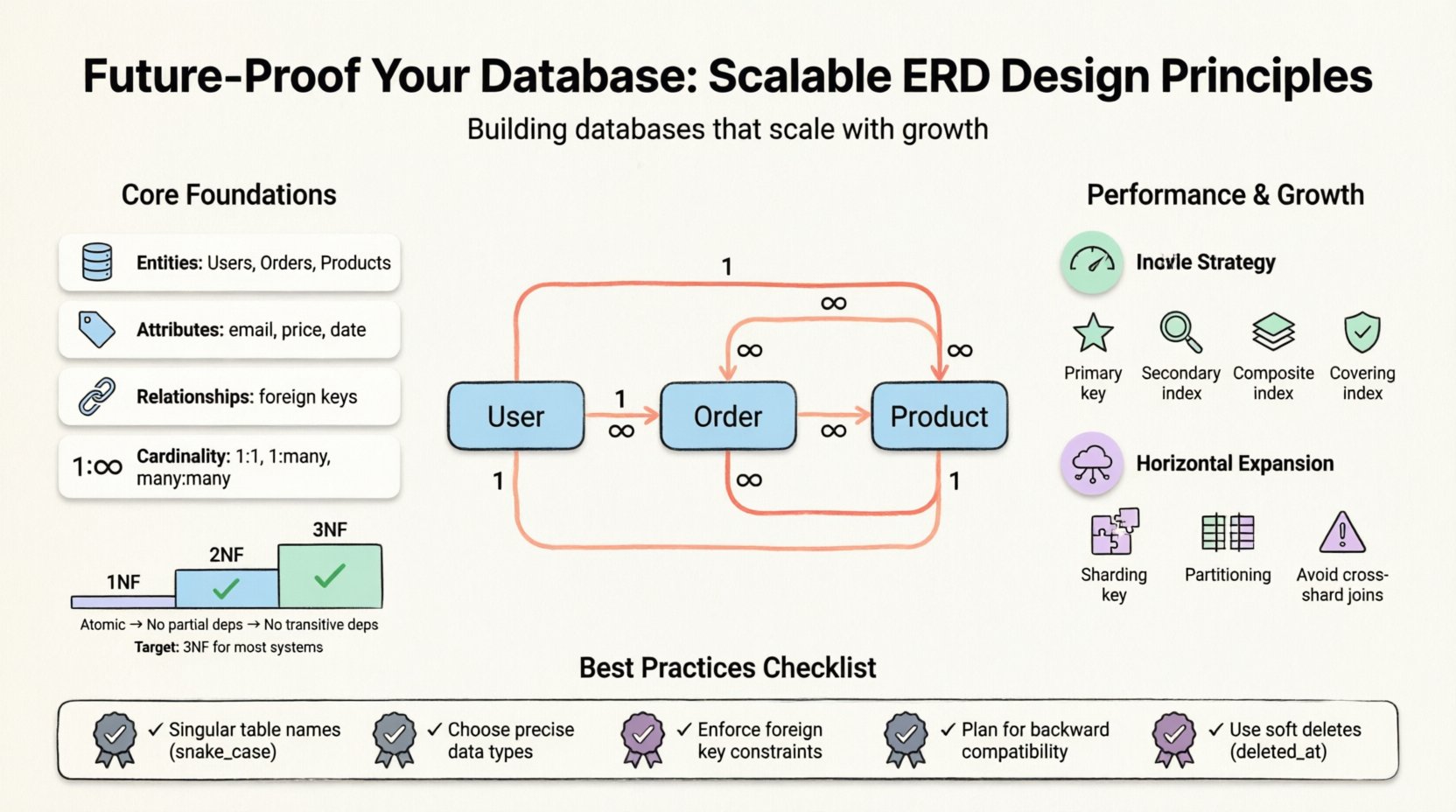
Antes de adentrarnos en tácticas específicas, es esencial comprender qué representa un ERD. Visualiza la estructura lógica de una base de datos. Mapea entidades (tablas), atributos (columnas) y relaciones (claves). Un modelo bien elaborado equilibra la integridad de los datos con el rendimiento. Sin embargo, la ‘mejor práctica’ varía según la carga de trabajo. Una aplicación con carga pesada de lecturas requiere una optimización diferente a un sistema transaccional con carga pesada de escrituras.
Los componentes clave incluyen:
- Entidades: Los objetos principales, como Usuarios, Pedidos o Productos.
- Atributos: Las propiedades que definen una entidad, como direcciones de correo electrónico o precios.
- Relaciones: Cómo interactúan las entidades, a menudo definidas por claves foráneas.
- Cardinalidad: La relación numérica entre entidades (uno a uno, uno a muchos, muchos a muchos).
Normalización: El equilibrio entre redundancia y velocidad ⚖️
La normalización es el proceso de organizar los datos para reducir la redundancia y mejorar la integridad. Aunque a menudo se trata como una regla estricta, es un compromiso. Una alta normalización minimiza las anomalías, pero puede aumentar la complejidad de las consultas mediante combinaciones (joins). Una baja normalización (denormalización) acelera las lecturas, pero conlleva el riesgo de inconsistencia de datos.
Niveles de normalización
Comprender las formas estándar te ayuda a decidir dónde detenerte. Cada forma aborda anomalías de datos específicas.
- Primera Forma Normal (1FN): Garantiza la atomicidad. Cada columna debe contener valores indivisibles. No deben existir grupos repetidos ni arreglos dentro de una sola celda.
- Segunda Forma Normal (2FN): Se basa en la 1FN. Todos los atributos no clave deben depender de toda la clave primaria, no solo de parte de ella. Esto elimina las dependencias parciales.
- Tercera Forma Normal (3FN): Se basa en la 2FN. Los atributos no clave no deben depender de otros atributos no clave. Esto elimina las dependencias transitivas.
- Forma Normal de Boyce-Codd (FNBC): Una versión más estricta de la 3FN. Maneja casos en los que los determinantes no son claves candidatas.
Para la mayoría de los sistemas escalables, alcanzar la 3FN es el objetivo estándar. Avanzar más a menudo produce retornos decrecientes mientras aumenta la sobrecarga de mantenimiento. Sin embargo, para sistemas con carga pesada de análisis, es común un retorno controlado a la denormalización.
Tabla de compromisos de normalización
| Nivel de normalización | Beneficio principal | Desventaja principal |
|---|---|---|
| 1FN | Almacenamiento de datos atómicos | Ninguno |
| 2FN | Elimina dependencias parciales | Se requieren más uniones |
| 3FN | Elimina dependencias transitivas | Complejidad de unión aumentada |
| No normalizado | Consultas de lectura más rápidas | Redundancia de datos y anomalías de actualización |
Diseño de esquema para crecimiento y flexibilidad 📈
Diseñar para el presente es insuficiente. Debes anticipar la evolución futura del esquema. Las estructuras rígidas fallan cuando cambia la lógica de negocio. Un diseño flexible permite la expansión sin requerir una migración completa del sistema.
1. Convenciones y estándares de nomenclatura
La consistencia es vital para la mantenibilidad. Un esquema de nomenclatura caótico conduce a la confusión y errores. Establece una norma temprano y aplícala de forma estricta en todo el equipo.
- Usa nombres en singular:Las tablas deben representar una sola entidad (por ejemplo,
usuario, nousuarios). - Delimitadores consistentes:Usa snake_case para nombres de tablas y columnas para garantizar compatibilidad entre diferentes sistemas operativos y herramientas.
- Prefijos para especificidad:Usa prefijos como
fk_para claves foráneas oidx_para índices para hacer claro su propósito. - Evite palabras reservadas: Nunca use palabras clave como
orden,grupo, oseleccionecomo nombres de columna.
2. Tipos de datos y precisión
Elegir el tipo de datos correcto afecta el espacio de almacenamiento y la velocidad de las consultas. Los tipos demasiado genéricos desperdician espacio y ralentizan el procesamiento.
- Enteros: Use
TINYINTpara banderas (0-1) o conteos pequeños. UseBIGINTsolo cuando anticipa una escala masiva. - Cadenas: Evite
TEXTpara valores cortos. UseVARCHARcon una longitud específica para ahorrar espacio y permitir indexación. - Fechas: Use
TIMESTAMPpara momentos específicos yDATEsolo para fechas calendario. Siempre almacénelas en UTC para evitar confusiones con husos horarios. - Decimales: Para datos financieros, use decimales de punto fijo en lugar de números de punto flotante para evitar errores de redondeo.
Relaciones y gestión de cardinalidad 🔗
Cómo se relacionan las entidades define la integridad de sus datos. Las relaciones mal gestionadas conducen a registros huérfanos y pérdida de datos.
1. Restricciones de clave foránea
Las claves foráneas garantizan la integridad referencial. Aseguran que un registro en una tabla no pueda referenciar a un registro inexistente en otra. Aunque algunos desarrolladores las deshabilitan por rendimiento, los motores de bases de datos modernos las manejan de forma eficiente. Depender de comprobaciones a nivel de aplicación es propenso a errores.
2. Manejo de relaciones muchos a muchos
Una relación muchos a muchos (por ejemplo, Estudiantes y Cursos) no puede representarse directamente en dos tablas. Requiere una tabla de unión (entidad asociativa).
- Cree una nueva tabla que contenga las claves primarias de ambas tablas relacionadas.
- Agregue una clave primaria compuesta que consista en ambas claves foráneas.
- Utilice esta tabla para almacenar atributos adicionales específicos de la relación, como fechas de inscripción.
3. Relaciones opcionales frente a obligatorias
Defina claramente si una relación es obligatoria. Un NULLvalor en una columna de clave foránea indica una relación opcional. Esta decisión afecta la lógica de validación en la capa de aplicación.
Estrategias de indexación para el rendimiento de lectura 🏎️
Los índices son el mecanismo principal para acelerar la recuperación de datos. Sin embargo, no son gratuitos. Cada índice consume espacio en disco y ralentiza las operaciones de escritura (insertar, actualizar, eliminar).
1. Índices primarios
Cada tabla necesita una clave primaria. A menudo es agrupada, lo que significa que los datos físicos se almacenan en el orden de la clave. Elija una clave que sea estable y nunca actualizada. Las claves de sustitución (enteros autoincrementales) suelen ser mejores que las claves naturales (como correos electrónicos) en cuanto al rendimiento.
2. Índices secundarios
Utilice índices secundarios para optimizar consultas que filtran o ordenan columnas que no son primarias. Escenarios comunes incluyen:
- Búsqueda por dirección de correo electrónico.
- Filtrado por estado o categoría.
- Ordenar resultados por fecha.
3. Índices compuestos
Cuando se consulta por múltiples columnas, un índice compuesto puede ser más eficiente que índices separados por columna única. El orden de las columnas en el índice importa. Coloque primero la columna más selectiva.
4. Índices cubiertos
Un índice cubierto incluye todas las columnas necesarias para satisfacer una consulta. Esto permite que la base de datos recupere los datos directamente desde el índice sin acceder a la tabla principal, reduciendo significativamente la entrada/salida.
Diseño para escalabilidad horizontal 🌐
La escalabilidad vertical (añadir más potencia a un servidor único) tiene límites. En última instancia, debe distribuir los datos entre múltiples nodos. El diseño del ERD debe tener en cuenta esta realidad.
1. Claves de fragmentación
La fragmentación implica dividir los datos entre múltiples bases de datos. La elección de la clave de fragmentación es crítica. Debe usarse con frecuencia en consultas para garantizar la localidad de los datos. Si fragmenta por “user_id, puedes consultar fácilmente todos los datos de ese usuario en un solo nodo.
- Buenas claves de partición: Alta cardinalidad, utilizada con frecuencia en consultas.
- Malas claves de partición: Baja cardinalidad (por ejemplo,
country_code) o raramente utilizada.
2. Evitar combinaciones entre particiones
Las combinaciones entre particiones diferentes son costosas y complejas. Diseña tu esquema para minimizar la necesidad de ellas. Si necesitas datos de dos entidades que podrían estar en particiones diferentes, considera denormalizar los datos. Almacena directamente en la tabla los datos de clave foránea necesarios para evitar la combinación.
3. Particionamiento
El particionamiento divide una tabla grande en piezas más pequeñas y manejables. Esto se puede hacer por rango (fechas), lista (categorías) o hash. Mejora la mantenibilidad y el rendimiento de las consultas sin cambiar significativamente la lógica de la aplicación.
Evolution y migración de esquemas 🔄
Los requisitos cambian. Las nuevas características exigen nuevas columnas. Las características antiguas se deprecian. Un ERD robusto permite cambios sin romper la funcionalidad existente.
1. Compatibilidad hacia atrás
Al agregar nuevas características, asegúrate de que los clientes antiguos aún puedan funcionar. Agrega primero las nuevas columnas como nulas. Poblalas gradualmente. No elimines las columnas de inmediato; márquelas como obsoletas y mantenlas durante una ventana de migración.
2. Versionado de modelos de datos
Lleva un registro de las versiones del esquema. Esto te permite revertir cambios si una migración causa fallas críticas. Usa scripts de migración idempotentes, lo que significa que se pueden ejecutar múltiples veces sin causar errores.
3. Manejo de la migración de datos
Mover grandes volúmenes de datos requiere una planificación cuidadosa. Los bloqueos grandes pueden bloquear el tráfico de producción. Realiza las migraciones durante ventanas de bajo tráfico o utiliza estrategias de despliegue azul-verde cuando sea posible.
Errores comunes que debes evitar ⚠️
Incluso arquitectos experimentados cometen errores. La conciencia de errores comunes te ayuda a evitarlos.
- Sobrediseño: Diseñar para una escala que aún no tienes. Si estás empezando, manténlo simple. La complejidad añade costo y riesgo.
- Ignorar eliminaciones suaves: Nunca elimines permanentemente registros sensibles de inmediato. Usa una
deleted_atmarca de tiempo en su lugar. Esto preserva los registros de auditoría y permite la recuperación. - Conflictos de nombres: Usar el mismo nombre para una tabla y una columna crea ambigüedad. Adhírete a la regla de tabla en singular.
- Faltan restricciones:Depender únicamente de la lógica de la aplicación para aplicar reglas de negocio conduce a la corrupción de datos. Aplicar restricciones a nivel de base de datos.
- Ignorar la seguridad:El diseño debe incluir campos para el control de acceso. Asegúrese de que el acceso basado en roles se soporte en la fase de diseño de esquema.
Consideraciones finales para la longevidad 🏁
Crear una base de datos escalable es un proceso continuo. Requiere monitoreo, análisis y ajustes. Ningún diseño es perfecto al lanzamiento. El objetivo es crear una base que sea fácil de modificar.
Audite regularmente sus consultas. Identifique operaciones lentas y optimice el esquema subyacente. Utilice herramientas de perfilado para comprender cómo se accede a sus datos. Este bucle de retroalimentación garantiza que su arquitectura permanezca eficiente a medida que crece su datos.
Recuerde que la tecnología evoluciona. Aparecen nuevos motores de almacenamiento y lenguajes de consulta. Un esquema flexible se adapta mejor a estos cambios que uno rígido. Enfóquese en las relaciones fundamentales e integridad de datos. Esos aspectos permanecen constantes incluso cuando cambian las herramientas.
Al adherirse a estos principios, construye sistemas resilientes. Manejan el crecimiento con elegancia y mantienen el rendimiento bajo carga. Esta es la esencia de proteger su infraestructura de base de datos contra el futuro.