


Diseñar esquemas de bases de datos robustos requiere más que simplemente listar tablas y columnas. Exige una comprensión profunda de cómo se relacionan entre sí las entidades. Entre los conceptos más potentes pero complejos en los Diagramas Entidad-Relación (ERD) está la herencia. Este mecanismo nos permite modelar jerarquías del mundo real donde los objetos comparten características comunes, pero también poseen atributos únicos. En el contexto del diseño de bases de datos, esto se traduce en supertipos y subtipos. 🧩
Cuando modelamos la herencia, estamos capturando esencialmente la relación «es-un». Por ejemplo, un Vehículo es un tipo de Producto, y un Automóvil es un tipo de Vehículo. Esta jerarquía nos permite reutilizar atributos a niveles superiores mientras definimos comportamientos o datos específicos a niveles inferiores. Comprender cómo implementar esto en una base de datos relacional es crucial para la integridad de los datos y el rendimiento de las consultas. 🗄️
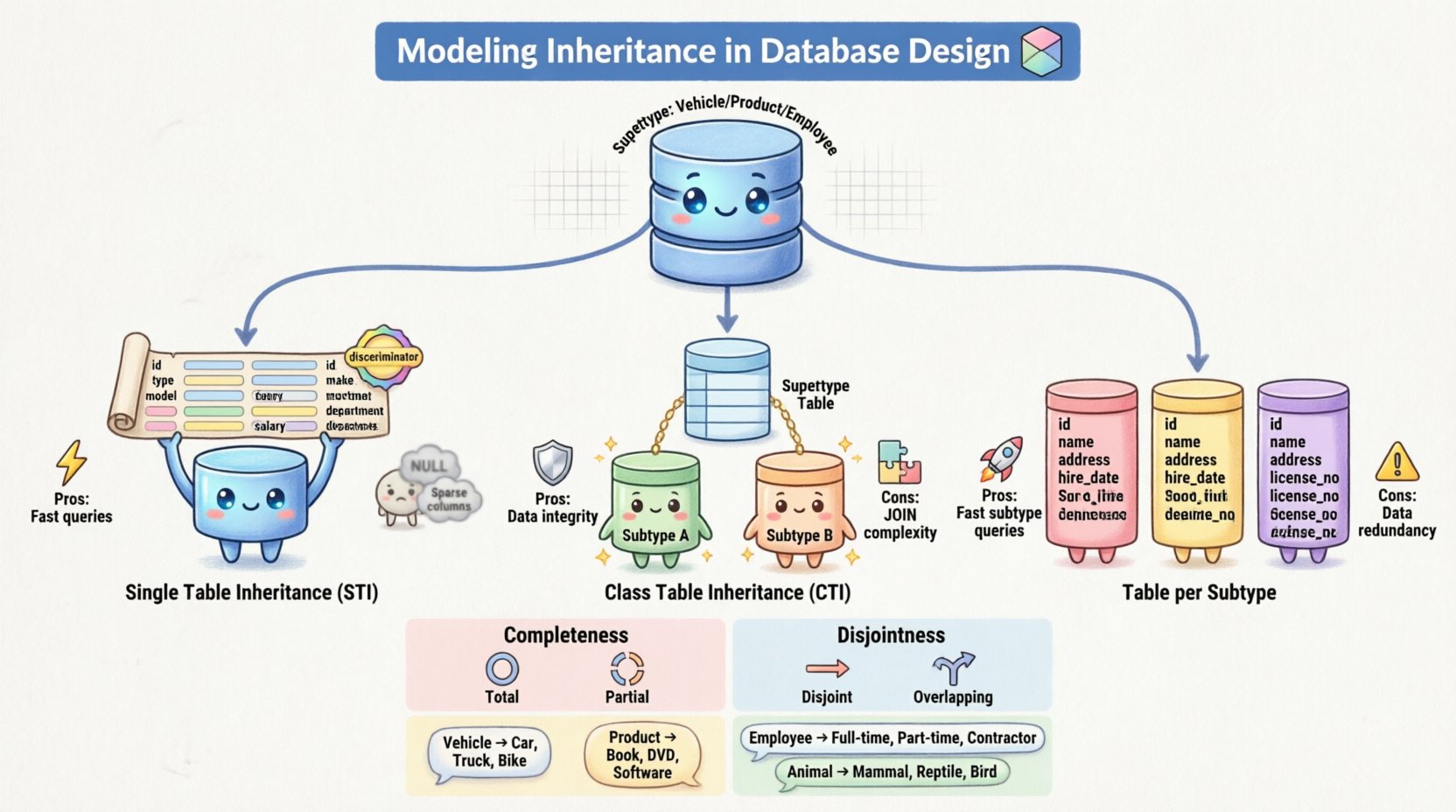
🔑 Conceptos fundamentales: Supertipos y subtipos
Antes de adentrarnos en la implementación, debemos definir claramente la terminología. La herencia en el modelado de bases de datos no se trata únicamente de código; se trata de la representación estructural de los datos.
- Supertipo: Esta es la entidad padre. Contiene atributos comunes a todas las entidades relacionadas. Representa la categoría general. Por ejemplo, Empleado podría ser un supertipo.
- Subtipo: Estas son las entidades hijas. Heredan atributos del supertipo, pero también pueden tener sus propios atributos únicos. Ejemplos incluyen Gerente o Desarrollador.
- Categoría de entidad: El supertipo a veces se denomina categoría de entidad, agrupando los subtipos juntos.
- Discriminador: Un atributo específico dentro del supertipo que identifica a qué subtipo pertenece una instancia. A menudo se utiliza en implementaciones físicas.
La relación entre un supertipo y un subtipo es estricta. Cada instancia de un subtipo también debe ser una instancia del supertipo. Sin embargo, no todas las instancias del supertipo necesitan ser instancias de un subtipo específico. Esta distinción es vital para la precisión en el modelado de datos. ✅
📊 Estrategias de implementación
Traducir el modelo lógico de ERD a un esquema de base de datos físico implica estrategias específicas de mapeo. Hay tres enfoques principales utilizados para representar la herencia en sistemas relacionales. Cada uno tiene compromisos en cuanto al almacenamiento, la velocidad de recuperación y la integridad de los datos. 🛠️
1. Herencia de tabla única (STI)
En este enfoque, todos los atributos del supertipo y todos los subtipos se combinan en una sola tabla. La tabla contiene columnas para cada atributo definido en toda la jerarquía. Para distinguir entre filas que pertenecen a diferentes subtipos, se agrega una columna discriminadora.
- Ventajas:Extremadamente eficiente para leer datos. Una consulta simple
SELECTrecupera toda la información sin joins complejos. - Desventajas:La tabla puede volverse muy ancha con muchos
NULLvalores para atributos que no aplican a subtipos específicos. También puede dificultar las actualizaciones si cambian las restricciones específicas de subtipo.
2. Herencia de tabla de clase (CTI)
Aquí, el supertipo y cada subtipo se asignan a sus propias tablas separadas. La tabla del supertipo contiene los atributos comunes y una clave primaria. Cada tabla de subtipo contiene los atributos únicos y una clave foránea que se vincula de nuevo con la clave primaria del supertipo.
- Ventajas:Altamente normalizada. Ningún
NULLvalores para atributos no aplicables. Aplica estrictamente la integridad referencial. - Desventajas:Recuperar datos requiere múltiples operaciones
JOINoperaciones, lo que puede afectar el rendimiento en conjuntos de datos grandes. También complica las operacionesINSERTya que los datos deben escribirse en múltiples tablas.
3. Tabla por subtipo (Herencia de tabla concreta)
Esta estrategia crea una tabla para cada subtipo, incluyendo el supertipo. Sin embargo, cada tabla de subtipo contiene una copia de los atributos del supertipo. No existe un vínculo directo de vuelta a una tabla central de supertipo.
- Ventajas:Consultar un subtipo específico es muy rápido, ya que todos los datos están en un solo lugar. Evita el problema de
NULLdel STI. - Desventajas:Redundancia de datos. Si un atributo común cambia en el supertipo, debe actualizarse en cada tabla de subtipo. Esto aumenta el riesgo de inconsistencia de datos.
⚖️ Restricciones sobre la herencia
No todas las relaciones de herencia son iguales. Debemos definir restricciones que regulen cómo las instancias se relacionan con sus tipos. Estas restricciones aseguran que los datos permanezcan lógicos y consistentes. 📝
Restricción de completitud
Esta restricción determina si cada instancia de un supertipo debe pertenecer a un subtipo.
- Completa: Cada instancia del supertipo debe ser miembro de al menos un subtipo. No existen instancias “genéricas”. Por ejemplo, cada Animal debe ser o bien un Mamífero o un Pájaro.
- Parcial: Una instancia del supertipo no necesariamente pertenece a ningún subtipo. Puede existir como una entidad general. Esto es común cuando la jerarquía se utiliza para categorización en lugar de clasificación estricta.
Restricción de disjuntividad
Esta restricción determina si una instancia puede pertenecer a múltiples subtipos simultáneamente.
- Disjunto: Una instancia puede pertenecer solo a un subtipo. No puede ser a la vez un Gerente y un Desarrollador al mismo tiempo dentro de este modelo.
- Superposición: Una instancia puede pertenecer a más de un subtipo. Esto permite roles complejos donde un Empleado puede tener múltiples posiciones o clasificaciones.
Combinar estas restricciones da lugar a cuatro escenarios de modelado distintos. Comprender cuál escenario se ajusta a tu lógica de negocio es fundamental antes de crear el esquema. 🧠
| Tipo de restricción | Definición | Escenario de ejemplo |
|---|---|---|
| Disjuntos + Completos | Solo un subtipo, sin instancias genéricas | Estado del pedido: Pendiente, Enviado, Entregado |
| Disjuntos + Parciales | Solo un subtipo, subtipo opcional | Cliente: VIP o Regular (algunos no son ninguno) |
| Superposición + Completos | Varios subtipos permitidos, debe pertenecer a uno | Rol de usuario: Administrador y Editor (debe tener al menos uno) |
| Superposición + Parciales | Varios subtipos permitidos, opcionales | Producto: Viable, Promocional (puede ser ambos o ninguno) |
🔍 Búsqueda y recuperación de datos
La elección de la estrategia de mapeo tiene un impacto significativo en la forma en que escribes consultas. En un entorno normalizado, a menudo necesitas recorrer la jerarquía para obtener una imagen completa de una entidad. 🔎
- Recuperación de datos de subtipo: Si necesitas acceder a atributos específicos de un subtipo, debes unir la tabla de subtipo. Esto es estándar en la Herencia de Tabla de Clases.
- Recuperación de datos de supertipo: Si necesitas atributos comunes, puedes consultar directamente la tabla de supertipo.
- Consultas polimórficas: Cuando se consulta todos los ejemplares sin importar el subtipo, el enfoque de una sola tabla es el más rápido. Sin embargo, si se usan múltiples tablas, debes usar
UNIÓNoperaciones o uniones complejas.
Considera las implicaciones de rendimiento. Una consulta que une cinco tablas para recuperar un solo registro puede ser más lenta que una consulta en una sola tabla desnormalizada. Sin embargo, la tabla desnormalizada puede violar las reglas de normalización, lo que lleva a anomalías de actualización. Equilibrar estos factores es una parte clave del diseño de esquemas. ⚖️
🛠️ Mantenimiento y evolución
Los esquemas no son estáticos. Los requisitos del negocio cambian, y por lo tanto debe cambiar también la estructura de la base de datos. El modelado de herencia ofrece flexibilidad, pero también introduce complejidad durante el mantenimiento. 🔄
Adición de nuevos subtipos
Agregar un nuevo subtipo es generalmente sencillo. Creas una nueva tabla (en CTI) o un nuevo valor en la columna discriminadora (en STI). Sin embargo, debes asegurarte de que las consultas existentes y la lógica de la aplicación puedan acomodar el nuevo tipo. El no actualizar el código puede provocar errores en tiempo de ejecución.
Modificación de atributos de supertipo
Si agregas un atributo al supertipo, debe reflejarse en cada tabla de subtipo si usas CTI o Tabla por Subtipo. En STI, lo agregas una sola vez en la tabla única. Esto hace que STI sea más fácil de mantener para cambios comunes, pero más difícil para cambios específicos.
Migración de datos
Refactorizar un modelo de herencia es una tarea importante. Pasar de una sola tabla a una estructura normalizada requiere migrar datos entre múltiples tablas. Este proceso debe gestionarse con cuidado para evitar pérdidas o corrupción de datos. 🚧
📈 Normalización e herencia
El modelado de herencia interactúa estrechamente con la normalización de bases de datos. El objetivo de la normalización es reducir la redundancia y mejorar la integridad de los datos. La herencia puede entrar a veces en conflicto con estos objetivos si no se maneja correctamente.
- Primera Forma Normal (1FN): Los modelos de herencia generalmente cumplen con la 1FN, ya que los atributos son atómicos.
- Segunda Forma Normal (2FN): En STI, una tabla podría contener atributos que no dependen completamente de la clave primaria si el discriminador no forma parte de la clave. Esto requiere un diseño cuidadoso de la clave.
- Tercera Forma Normal (3FN): En CTI, la separación de atributos en tablas de subtipos ayuda a menudo a alcanzar la 3FN al eliminar dependencias transitivas.
Al diseñar superclases, asegúrese de que los atributos comunes sean verdaderamente comunes. Si un atributo solo se utiliza por un subtipo, probablemente no debería estar en la superclase. Esto evita que la superclase se convierta en una “tabla diosa” que es difícil de consultar. 👁️
🎯 Mejores prácticas para el diseño de esquemas
Para asegurarse de que su modelo de herencia permanezca mantenible y eficiente, siga estas directrices.
- Limitar la profundidad: Evite jerarquías profundas. Tres niveles de herencia suelen ser el máximo recomendado. Más allá de esto, la complejidad de las consultas y el mantenimiento superan los beneficios.
- Usar nombres claros: Los nombres deben reflejar la jerarquía. Vehículo, Coche, Camión es claro. Entidad1, Entidad2 no lo es.
- Planificar el crecimiento: Anticipe subtipos futuros. Si espera muchos nuevos subtipos, una sola tabla podría volverse difícil de manejar. Si espera pocos, CTI podría ser mejor.
- Documentar restricciones: Documente claramente las restricciones de exclusividad y completitud. Los desarrolladores futuros necesitan saber si una instancia puede pertenecer a múltiples subtipos.
- Estrategia de indexación: Si se utiliza CTI, indexe las columnas de clave foránea en las tablas de subtipos para acelerar las uniones. Si se utiliza STI, indexe la columna discriminadora para filtrar.
🧪 Escenarios del mundo real
Veamos cómo se aplica esto a desafíos reales de modelado de datos.
Escenario 1: Recursos humanos
En un sistema de RRHH, tienes Persona como supertipo. Los subtipos incluyen Empleado, Contratista, y Pasante. Cada subtipo tiene datos únicos: Empleado tiene un ID de nómina, Contratista tiene una tasa de facturación. Una Personatabla almacena nombre y dirección. Esto se adapta muy bien al modelo de herencia de tabla de clases.
Escenario 2: Gestión de inventario
Considere un catálogo de productos. Producto es el supertipo. Los subtipos son Electrónicos, Muebles, y Ropa. Electrónica tiene Período de garantía. Ropa tiene Tamaño y Color. Si consulta todos los productos con garantía, debe unir la tabla Electrónica. Esto destaca el compromiso de rendimiento de las consultas. 🔍
Escenario 3: Transacciones financieras
En un sistema bancario, Cuenta es el supertipo. Los subtipos son Ahorros, Cheques, y Préstamo. Una Ahorros cuenta tiene una tasa de interés. Una Préstamo cuenta tiene una fecha de vencimiento. Este escenario a menudo se beneficia de un enfoque de tabla única para simplificar los cálculos de saldo entre todos los tipos de cuentas.
🚀 Consideraciones de rendimiento
El rendimiento suele ser el factor determinante al elegir una estrategia de mapeo. Los conjuntos de datos grandes amplifican las diferencias entre los enfoques.
- Rendimiento de escritura: STI es más rápido para inserciones porque es una sola
INSERTARsentencia. CTI requiere múltiplesINSERTARsentencias, lo que aumenta la sobrecarga de la transacción. - Rendimiento de lectura: Si consulta con frecuencia tipos específicos, CTI es más rápido que STI porque solo lee las columnas relevantes. Si consulta todas las instancias, STI es más rápido.
- Almacenamiento: STI utiliza más almacenamiento debido a
NULLrelleno. CTI utiliza más almacenamiento debido a claves primarias y claves foráneas duplicadas, pero menos debido a la falta deNULLrelleno.
Es fundamental realizar un perfilado de su aplicación. El rendimiento teórico no siempre coincide con los patrones de uso del mundo real. Probar con volúmenes de datos realistas es la única forma de confirmar su elección. 📊
🛡️ Integridad y validación de datos
Mantener la integridad de los datos en un modelo de herencia requiere reglas de validación estrictas. Debe asegurarse de que los datos ingresados en una tabla de subtipo coincidan con las restricciones del supertipo.
- Restricciones de clave foránea: Asegúrese de que las filas de subtipo siempre se enlacen con filas de supertipo válidas. Esto evita datos huérfanos.
- Restricciones de verificación: Utilice restricciones de verificación para imponer reglas de negocio. Por ejemplo, asegúrese de que la Tasa de interés en un ahorro subtipo nunca sea negativa.
- Disparadores: En algunos escenarios complejos, pueden ser necesarios disparadores de base de datos para mantener la consistencia entre las tablas durante las actualizaciones.
Las pruebas automatizadas deben cubrir escenarios de herencia. Verifique que la creación de una nueva instancia de subtipo actualice correctamente el supertipo. Verifique que la eliminación de una instancia de supertipo se propague correctamente a las subtipos si ese es el comportamiento deseado. 🧪
📝 Consideraciones finales
Modelar la herencia es un equilibrio entre flexibilidad y complejidad. No existe una única forma “correcta” de hacerlo. La mejor elección depende de sus patrones específicos de acceso a datos, reglas de negocio y requisitos de rendimiento.
- Comience con una comprensión clara del dominio. Represente las entidades antes de preocuparse por las tablas.
- Elija una estrategia de mapeo que se alinee con sus consultas más frecuentes.
- Documente sus decisiones. El mantenimiento futuro dependerá de esta documentación.
- Revise el esquema periódicamente. A medida que la empresa evoluciona, el modelo podría necesitar cambios.
Al diseñar cuidadosamente los super tipos y subtipos, creas una base de datos que es robusta, escalable y fácil de entender. Esta fundación apoya las aplicaciones que dependen de ella, asegurando estabilidad y eficiencia a largo plazo. 🏗️