











Diseñar un esquema de base de datos robusto para plataformas de redes sociales requiere una comprensión profunda de cómo los usuarios interactúan, comparten y consumen información. A diferencia de los sistemas transaccionales tradicionales, las redes sociales implican relaciones muchos a muchos complejas, estructuras de datos recursivas y requisitos de escala masiva. El Diagrama Entidad-Relación (ERD) sirve como plano maestro para estas interacciones, garantizando la integridad de los datos mientras se apoya el crecimiento rápido. Esta guía explora las estrategias críticas para modelar eficazmente los datos de redes sociales.
Comprendiendo el desafío principal 🧩
Las aplicaciones de redes sociales no son meros repositorios de contenido; son redes dinámicas de relaciones. Una publicación simple en un blog difiere significativamente de un feed de redes sociales debido a la capa de interacción. Me gusta, compartidos, comentarios y seguidores crean una red de conexiones que deben modelarse con precisión. Una mala modelización conduce a un rendimiento lento de las consultas, inconsistencia de datos y dificultad para implementar funciones como feeds de noticias o sugerencias de amigos.
- Volumen:Las plataformas sociales generan millones de eventos por segundo.
- Velocidad:Los datos llegan en flujos en tiempo real que deben procesarse de inmediato.
- Variedad:El contenido incluye texto, imágenes, videos, metadatos y datos de ubicación.
- Relaciones:El valor principal reside en las conexiones entre entidades.
Al construir un ERD, el objetivo principal es equilibrar la normalización con el rendimiento. La sobre-normalización puede hacer que las uniones sean demasiado costosas para lecturas de alta frecuencia. La sobre-desnormalización puede provocar redundancia de datos y problemas de consistencia. Las siguientes secciones detallan las entidades y relaciones específicas que definen este dominio.
Definiendo entidades principales 🔑
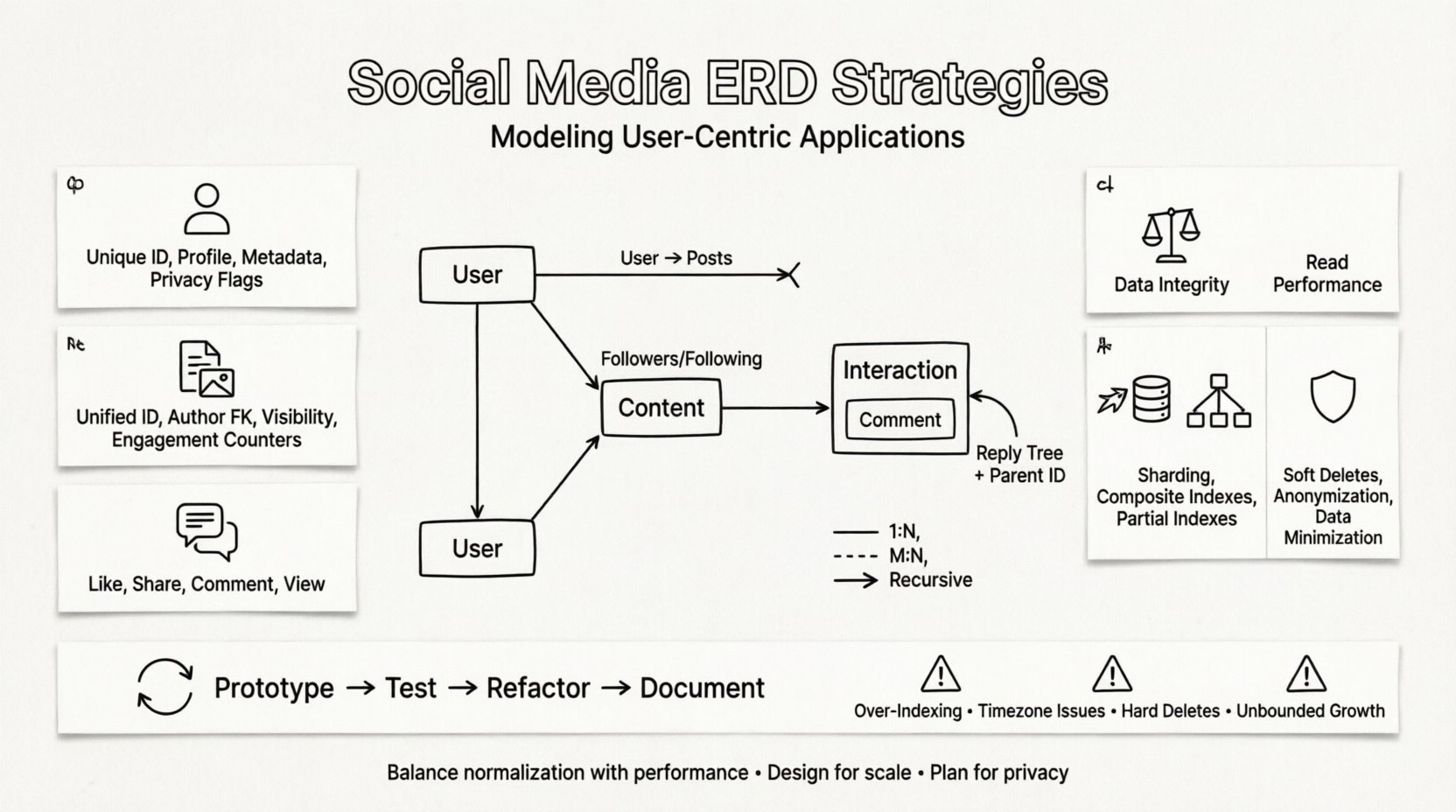
Cada sistema de redes sociales gira en torno a unas pocas entidades fundamentales. Identificarlas correctamente es el primer paso para crear un esquema escalable. Estas entidades representan los bloques de construcción principales de la aplicación.
1. La entidad Usuario 👤
El usuario es el nodo central en la red. Esta entidad almacena detalles de autenticación, información del perfil y preferencias. Debe diseñarse para manejar millones de registros de forma eficiente.
- Identificador único:Se prefiere una clave artificial sobre claves naturales por rendimiento y anonimato.
- Datos del perfil: Nombre, biografía, avatar y estado de verificación.
- Metadatos:Marcas de tiempo para la creación de la cuenta, inicio de sesión más reciente y eliminación.
- Marcas de privacidad:Configuraciones que controlan la visibilidad de los datos para otros usuarios.
2. La entidad Contenido 📝
El contenido es el combustible de las plataformas sociales. Incluye publicaciones, historias, imágenes, videos y comentarios. Se requiere un esquema flexible porque los diferentes tipos de contenido tienen atributos distintos.
- ID unificado:Un ID genérico que enlaza con tablas específicas de contenido.
- Referencia del autor: Una clave foránea que hace referencia a la entidad Usuario.
- Alcance de visibilidad: Público, privado, solo amigos o grupos específicos.
- Contadores de participación: Contadores almacenados en caché para me gusta y comentarios con el fin de reducir la carga de las consultas.
3. La entidad de interacción 💬
Las interacciones representan las acciones que los usuarios realizan sobre contenido o sobre otros usuarios. Son transacciones de alto volumen que a menudo determinan los requisitos de rendimiento del sistema.
- Me gusta: Un estado binario entre un usuario y el contenido.
- Compartir: Una referencia al contenido original con un nuevo contexto.
- Comentario: Una relación jerárquica o en hilo con respecto al contenido.
- Vista: A menudo se registra por separado debido al alto volumen y menor importancia para la integridad.
Modelado de relaciones 🕸️
La verdadera complejidad de las redes sociales reside en las relaciones entre entidades. Las técnicas estándar de modelado relacional a menudo tienen dificultades con la naturaleza recursiva de los grafos sociales. Se debe prestar especial atención a cómo se almacenan estas conexiones.
Relaciones uno a muchos
Son las más comunes y sencillas. Por ejemplo, un usuario puede tener muchas publicaciones, pero una publicación pertenece solo a un usuario. Esto se modela utilizando una clave foránea en la tabla hija.
- Ejemplo: ID de usuario en la tabla Publicaciones.
- Beneficio: Recuperación rápida de todas las publicaciones para un perfil específico.
- Restricción: Garantiza la integridad referencial automáticamente.
Relaciones muchos a muchos
Los seguidores y seguidos son el ejemplo clásico. Un usuario sigue a muchos otros, y un usuario es seguido por muchos otros. Esto requiere una tabla de unión para resolver la relación.
- Tabla de unión: Contiene el ID de usuario A y el ID de usuario B.
- Marcas de tiempo: Cuando ocurrió la acción siguiente.
- Estado: Pendiente, aceptado o bloqueado.
- Rendimiento: El indexado es fundamental en ambos claves foráneas.
Relaciones recursivas
Algunas relaciones implican el mismo tipo de entidad. Un comentario puede tener respuestas a respuestas. Esto crea una estructura de árbol que es difícil de consultar en modelos relacionales estándar.
- ID del padre: Una clave foránea que apunta al ID del comentario.
- Profundidad: Limitar la profundidad de recursión evita bucles infinitos.
- Rutas materializadas: Almacenar la ruta del árbol para una navegación más rápida.
| Tipo de relación | Ejemplo | Estrategia de implementación | Impacto en el rendimiento |
|---|---|---|---|
| Uno a muchos | Usuario – Publicaciones | Clave foránea en el hijo | Bajo (indexación estándar) |
| Muchos a muchos | Usuario – Sigue | Tabla de unión | Medio (sobrecarga de unión) |
| Recursivo | Comentario – Respuesta | FK que se refiere a sí misma | Alto (consultas complejas) |
| Asociativo | Etiqueta – Usuario | Claves compuestas | Medio (búsqueda intensiva) |
Normalización frente a denormalización ⚖️
En los sistemas de redes sociales, el rendimiento de lectura suele superar al de escritura. Los usuarios esperan que los feeds se carguen instantáneamente, incluso cuando intervienen millones de registros. Esto requiere un equilibrio cuidadoso entre normalización y denormalización.
El caso a favor de la normalización
La normalización garantiza la integridad de los datos y reduce la redundancia. Es esencial para los datos centrales que no cambian con frecuencia.
- Consistencia de datos:Las actualizaciones ocurren en un solo lugar.
- Eficiencia de almacenamiento:Menor almacenamiento de datos duplicados.
- Mantenibilidad:Más fácil de aplicar reglas de negocio.
El caso a favor de la denormalización
La denormalización implica duplicar datos para reducir el número de uniones necesarias durante las lecturas. Esto es común en los feeds sociales.
- Velocidad de lectura:Menos uniones significan una ejecución de consultas más rápida.
- Caché:Contadores agregados (por ejemplo, likes totales) almacenados directamente.
- Sobrecarga de escritura:Las actualizaciones deben propagarse a todas las copias.
Enfoque híbrido
Una estrategia práctica implica normalizar el esquema principal mientras se denormalizan las métricas frecuentemente leídas. Por ejemplo, almacene el nombre de usuario en la tabla de publicaciones junto con el ID de usuario. Esto evita una unión al mostrar la publicación, a costa de una lógica de sincronización ocasional.
Estrategias de escalabilidad para ERDs 🚀
A medida que crece la base de usuarios, el esquema debe evolucionar para manejar la carga aumentada. La escalabilidad vertical tiene límites; la escalabilidad horizontal requiere consideraciones específicas del esquema.
Particionamiento
El particionamiento divide tablas grandes en piezas más pequeñas y manejables. En redes sociales, los datos a menudo se particionan por ID de usuario o fecha.
- Particionamiento horizontal:Dividir usuarios entre diferentes fragmentos según rangos de ID.
- Particionamiento vertical: Moviendo las columnas poco accesadas a una tabla separada.
- Particionado por fecha:Archivando publicaciones antiguas en tablas de almacenamiento en frío.
Estrategias de indexación
Los índices son vitales para el rendimiento de las consultas, pero ralentizan las escrituras. Se requiere un enfoque estratégico para la indexación.
- Índices compuestos: Cubriendo patrones comunes de consulta (por ejemplo, ID de usuario + marca de tiempo).
- Índices parciales:Indexando solo las filas relevantes (por ejemplo, publicaciones activas).
- Índices de búsqueda:Utilizando motores de búsqueda de texto completo para la descubrimiento de contenido.
Consideraciones de privacidad y cumplimiento 🛡️
El modelado de datos moderno debe tener en cuenta las regulaciones de privacidad como el GDPR y el CCPA. El diseño del esquema afecta la facilidad con la que los datos pueden anonimizarse o eliminarse.
Derecho al olvido
Los usuarios pueden solicitar la eliminación de sus datos. El diagrama ER debe permitir eliminaciones en cascada o eliminaciones suaves sin romper la integridad referencial.
- Eliminaciones suaves:Añadiendo una bandera «is_deleted» en lugar de eliminar filas.
- Datos huérfanos:Manejo de datos que hacen referencia a un usuario eliminado.
- Anonimización:Reemplazando identificadores personales con hashes.
Minimización de datos
Almacene solo los datos estrictamente necesarios. La recopilación excesiva de metadatos aumenta los costos de almacenamiento y los riesgos de privacidad.
- Políticas de retención:Eliminación automática de registros después de un período determinado.
- Permisos granulares:Controles de acceso a nivel de fila.
- Cifrado:Campos sensibles cifrados en reposo.
Manejo de metadatos y registros 📉
Más allá de las entidades principales, los sistemas generan grandes cantidades de metadatos. Esto incluye análisis, registros de errores y rastros de auditoría. Estos no deberían ensuciar el esquema transaccional principal.
Separación de preocupaciones
Mantenga la base de datos transaccional limpia. Derive el registro pesado y el análisis a sistemas separados.
- Flujos de eventos:Utilice colas de mensajes para el registro asíncrono.
- Tablas de análisis:Tablas separadas para tendencias históricas.
- Datos de series temporales:Almacenamiento específico para métricas a lo largo del tiempo.
Proceso iterativo de diseño 🔄
Los diagramas ER rara vez son perfectos en el primer boceto. Los requisitos de redes sociales evolucionan rápidamente a medida que se introducen nuevas funciones. El proceso de diseño debe ser iterativo.
- Prototipo:Construya un esquema mínimo viable para la característica principal.
- Prueba:Realice pruebas de carga con volúmenes de datos realistas.
- Refactorización:Ajuste las relaciones según los cuellos de botella de rendimiento.
- Documente:Mantenga diagramas actualizados para futuros desarrolladores.
Errores comunes que deben evitarse ⚠️
Incluso arquitectos experimentados cometen errores al modelar datos sociales. Reconocer estos patrones ayuda a prevenir problemas futuros.
- Sobrecarga de índices:Demasiados índices ralentizan significativamente las operaciones de escritura.
- Ignorar husos horarios:Almacenar marcas de tiempo sin contexto de huso horario genera confusión.
- Valores codificados:Evite incorporar lógica de negocio en el esquema (por ejemplo, valores de estado específicos).
- Descuidar las eliminaciones suaves:Las eliminaciones duras pueden romper las restricciones de clave foránea en toda la red.
- Crecimiento ilimitado:No archivar los datos antiguos conduce a un crecimiento excesivo de las tablas.
Consideraciones finales para el crecimiento futuro 🔮
Construir una plataforma de redes sociales es una tarea de largo plazo. El modelo de datos debe ser lo suficientemente flexible para adaptarse a cambios sin requerir una reescritura completa. Enfóquese en la claridad, la escalabilidad y la mantenibilidad. Las revisiones regulares del esquema frente a los patrones reales de uso garantizan que el sistema permanezca robusto a medida que crece.
- Versionado:Planifique las migraciones de esquema que permitan la compatibilidad hacia atrás.
- Monitoreo:Monitoree el rendimiento de las consultas para identificar debilidades en el esquema desde temprano.
- Comentarios de la comunidad:Escuche cómo se utiliza realmente los datos por parte del equipo de ingeniería.
Al seguir estas estrategias, los desarrolladores pueden crear una base sólida para aplicaciones centradas en el usuario. El diagrama ER no es solo un esquema; es la integridad estructural de toda la plataforma. Una planificación cuidadosa ahora evita una deuda técnica significativa más adelante.