











Las aplicaciones web modernas son ecosistemas complejos. No son meramente colecciones de archivos, sino sistemas interconectados en los que los datos circulan entre límites lógicos distintos. A medida que los sistemas crecen, mantener la claridad se convierte en un desafío importante. Los desarrolladores a menudo se ven atrapados en código espagueti donde el origen de un fragmento de datos es incierto y el destino es ambiguo. Esta falta de visibilidad conduce a deuda técnica, dependencias frágiles y mayor tiempo dedicado a depurar errores.
Esta guía explora un enfoque práctico para visualizar el flujo de datos entre paquetes. Al centrarnos en los diagramas de paquetes, establecemos una plantilla para comprender cómo la información circula a través de la arquitectura. Este proceso es esencial para mantener una base de código sana, asegurando que los cambios en una área no rompan accidentalmente la funcionalidad en otra. Examinaremos la metodología, los pasos específicos involucrados y los beneficios a largo plazo de mantener una documentación arquitectónica clara.
📐 Comprendiendo los diagramas de paquetes y su propósito
Un diagrama de paquetes es un diagrama estructural que muestra la organización de un sistema en grupos lógicos. En el contexto de una aplicación web, un paquete suele representar un dominio específico, un módulo o un límite de servicio. No es simplemente una estructura de carpetas; es una representación de la intención del sistema.
Cuando hablamos de visualizar el flujo de datos, estamos avanzando más allá de la estructura estática. Nos interesa el movimiento dinámico de la información. ¿Por qué es importante esta distinción?
- Claridad: Ayuda a los nuevos miembros del equipo a comprender cómo funciona el sistema sin tener que leer cada línea de código.
- Rastreabilidad: Cuando ocurre un error, puedes rastrear el camino del dato para identificar su origen.
- Refactorización: Te permite ver qué componentes están fuertemente acoplados antes de intentar reestructurarlos.
- Seguridad: Destaca dónde se transmite información sensible y asegura que pase por las capas de validación necesarias.
Sin esta visualización, los desarrolladores a menudo dependen de modelos mentales que pueden diferir de la implementación real. Esta discrepancia es una causa principal de errores de regresión. Un diagrama de paquetes actúa como la única fuente de verdad para las relaciones arquitectónicas.
🎯 Definiendo el alcance para la visualización
Antes de dibujar líneas entre cajas, debes definir qué constituye un paquete. Un paquete no debe ser demasiado granular ni demasiado amplio. Si un paquete contiene solo una clase, se anula el propósito del agrupamiento. Si un paquete contiene todo, no ofrece ninguna separación de responsabilidades.
El alcance de la visualización debe alinearse con los límites de despliegue y lógicos de la aplicación. Considera los siguientes criterios al definir tus paquetes:
- Diseño Orientado a Dominios (DDD): Alinea los paquetes con dominios empresariales, como Gestión de pedidos o Autenticación de usuarios.
- Capas: Separa las responsabilidades en capas como Interfaz, Lógica, y Acceso a datos.
- Responsabilidad: Cada paquete debe tener una única responsabilidad bien definida.
- Independencia: Los paquetes deben poder cambiar con un impacto mínimo en los demás.
Definir este alcance desde el principio evita que el diagrama se convierta en una red intrincada. Garantiza que la visualización siga siendo útil a medida que evoluciona la aplicación.
🏗️ La arquitectura del estudio de caso
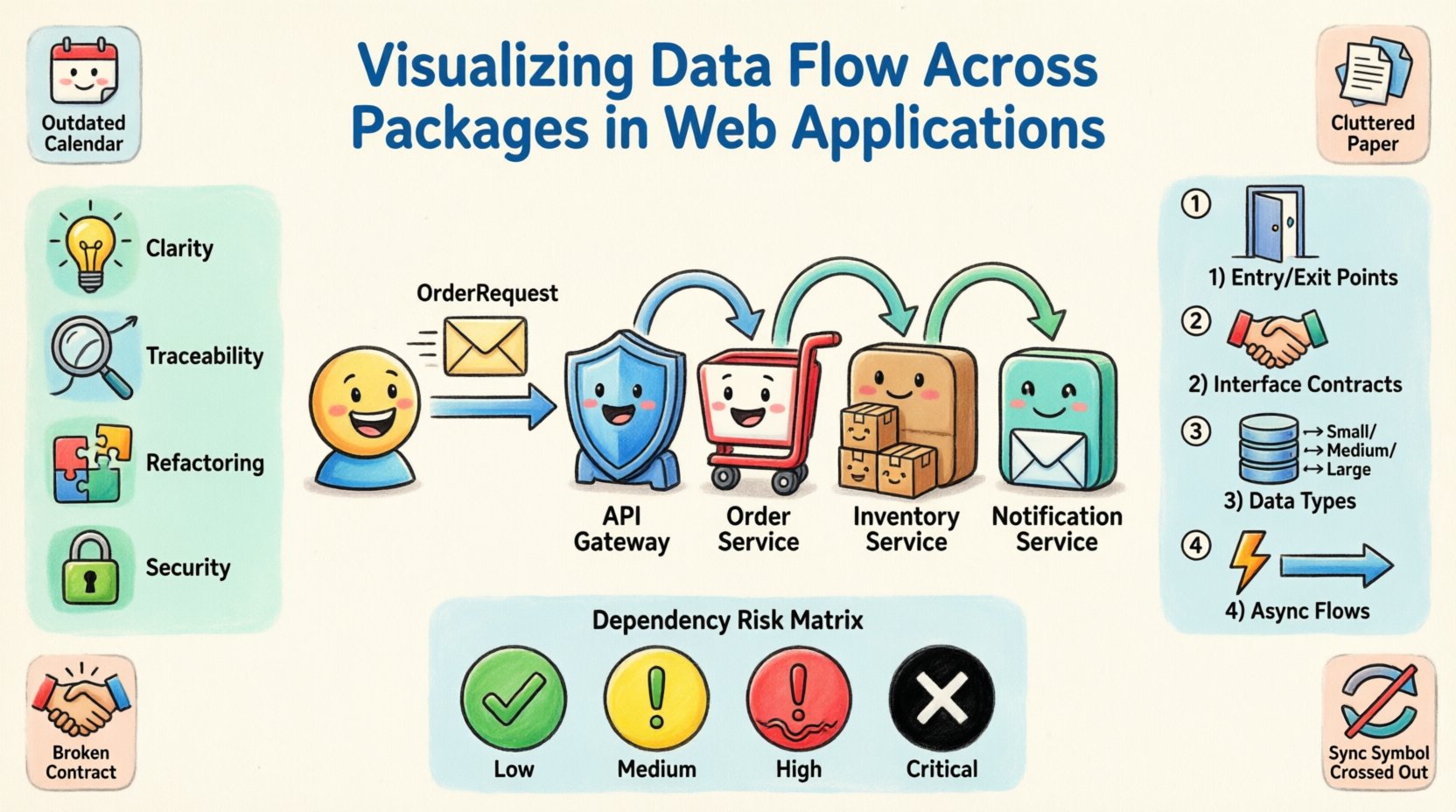
Para ilustrar el proceso, examinaremos una aplicación web hipotética diseñada para una plataforma de comercio electrónico. Este escenario implica varias áreas funcionales que requieren intercambio de datos. La arquitectura se divide en los siguientes paquetes lógicos:
- Dominio principal: Contiene la lógica empresarial fundamental, entidades y objetos de valor.
- Pasarela de API: Maneja las solicitudes entrantes, la autenticación y el enrutamiento.
- Servicio de inventario: Gestiona los niveles de stock y la disponibilidad de productos.
- Servicio de pedidos: Procesa las transacciones y crea registros de pedidos.
- Servicio de notificaciones: Envía correos electrónicos y alertas push a los usuarios.
En este escenario, un usuario realiza un pedido. Los datos deben fluir desde la pasarela de API hasta el servicio de pedidos, interactuar con el inventario y finalmente desencadenar una notificación. Visualizar este flujo requiere mapear las interfaces y dependencias entre estos paquetes.
🔄 Proceso paso a paso de visualización
Crear una representación precisa del flujo de datos requiere un enfoque metódico. No basta con dibujar cuadros; debe anotar las conexiones con detalles específicos sobre qué datos están en movimiento.
1. Identificar puntos de entrada y salida
Cada paquete debe tener límites definidos. Identifique dónde los datos entran al sistema y dónde salen. Para la pasarela de API, el punto de entrada es la solicitud HTTP. El punto de salida podría ser una transacción de base de datos o un evento de cola de mensajes. Marque estos claramente en el diagrama.
2. Mapear contratos de interfaz
Las dependencias deben definirse mediante interfaces, no mediante implementaciones concretas. Al mapear el flujo entre el servicio de pedidos y el servicio de inventario, especifique los métodos de interfaz que se están llamando. Esto desacopla los paquetes y hace que el diagrama sea más estable.
- Entrada: ¿Qué datos se requieren? (por ejemplo,
OrderRequest,IdUsuario) - Salida: ¿Qué datos se devuelven? (por ejemplo,
EstadoStock,IdTransacción) - Errores: ¿Cómo se comunican los fallos? (por ejemplo,
TimeoutException,InvalidDataError)
3. Anotar tipos y volúmenes de datos
No todos los flujos de datos son iguales. Algunos son actualizaciones pequeñas de metadatos, mientras que otros son transferencias de archivos grandes. Anotar el tipo y volumen de datos ayuda en la planificación del rendimiento. Por ejemplo, el servicio de notificaciones podría manejar un alto volumen de mensajes pequeños, mientras que el servicio de inventario podría manejar actualizaciones por lotes grandes.
4. Destacar flujos asíncronos
Las aplicaciones modernas dependen a menudo de la comunicación asíncrona. Si el servicio de pedidos no espera la respuesta inmediata del servicio de inventario, este es un detalle arquitectónico crítico. Distinga entre llamadas síncronas (bloqueantes) y eventos asíncronos (enviar y olvidar). Utilice estilos de línea diferentes para representar visualmente estas interacciones.
🔗 Análisis de dependencias y acoplamiento
Una vez que se dibuja el diagrama, comienza el verdadero trabajo: el análisis. Debe buscar señales de acoplamiento no saludable. El acoplamiento se refiere al grado de interdependencia entre los módulos de software.
Un alto acoplamiento significa que un cambio en un paquete requiere cambios en otro. Esto reduce la flexibilidad y aumenta el riesgo de cambios que rompen la funcionalidad. El objetivo es lograr un bajo acoplamiento manteniendo una alta cohesión (donde los elementos dentro de un paquete están estrechamente relacionados).
Durante el proceso de revisión, busque los siguientes patrones:
- Dependencias circulares:El paquete A depende de B, y B depende de A. Esto crea un bloqueo en la compilación y en la lógica.
- Acoplamiento oculto:Dependencias que existen únicamente a través de variables estáticas compartidas o estado global.
- Paquetes dioses:Un solo paquete que depende de casi todo lo demás o que es dependido por casi todo lo demás.
- Abstracciones filtradas:Donde los detalles de implementación de un paquete se exponen a otro.
Matriz de riesgo de dependencias
Para ayudar a evaluar la salud de su arquitectura, utilice una matriz de riesgo para categorizar las dependencias según su impacto.
| Tipo de dependencia | Nivel de acoplamiento | Puntuación de riesgo | Acción recomendada |
|---|---|---|---|
| Dependencia de interfaz | Bajo | Bajo | Aceptable |
| Dependencia de biblioteca compartida | Medio | Medio | Revisar regularmente |
| Dependencia directa de clase | Alto | Alto | Reestructurar hacia interfaz |
| Dependencia de estado global | Muy alto | Crítico | Eliminar inmediatamente |
| Dependencia circular | Bloqueado | Crítico | Reestructurar la arquitectura |
⚠️ Peligros comunes en la visualización
Aunque se cuente con una metodología clara, pueden ocurrir errores durante el proceso de documentación. Estar al tanto de los peligros comunes ayuda a mantener la precisión de sus diagramas.
- Diagramas desactualizados: El problema más común es la documentación que se queda atrás respecto al código. Si el código cambia y el diagrama no, el diagrama se convierte en ruido. Establezca una regla según la cual el diagrama forma parte de la definición de finalización para cualquier característica importante.
- Sobreactracción:Crear un diagrama que sea demasiado abstracto no proporciona ninguna información útil. Incluye suficiente detalle para entender los tipos de datos y la dirección del flujo.
- Subtractracción:Incluir cada llamada de método individual ensucia la vista. Enfócate en el flujo de alto nivel y en la ruta crítica.
- Ignorar los contratos de datos:Enfocarse únicamente en el flujo de control (quién llama a quién) sin mostrar el flujo de datos (qué se pasa) hace que el diagrama sea menos útil para depurar.
- Suponer un flujo síncrono:Muchos sistemas son impulsados por eventos. Suponer llamadas síncronas en un diagrama puede generar malentendidos sobre la latencia y la fiabilidad.
🛡️ Mantener la integridad arquitectónica
Crear el diagrama es solo el primer paso. Mantenerlo requiere disciplina. La integridad arquitectónica no es una tarea única; es un proceso continuo de verificación y ajuste.
Una estrategia efectiva es integrar la verificación del diagrama en la canalización de compilación. Las herramientas automatizadas pueden comprobar que la estructura del código coincida con las dependencias documentadas. Si se introduce una nueva dependencia sin actualizar el diagrama, la compilación puede fallar o generar una advertencia. Esto obliga a los desarrolladores a mantener la documentación actualizada.
Otra estrategia es realizar revisiones arquitectónicas periódicas. Programa sesiones trimestrales en las que el equipo recorra los diagramas. Discute los cambios recientes y actualiza la visualización para reflejar el estado actual del sistema. Esto asegura que el conocimiento permanezca distribuido entre el equipo y no se concentre en la cabeza de una sola persona.
🤝 Incorporación y transferencia de conocimientos
Uno de los resultados más valiosos de un diagrama de paquetes bien mantenido es una mejor incorporación. Cuando un nuevo desarrollador se une al equipo, enfrenta una curva de aprendizaje pronunciada. Necesita entender dónde se encuentra el código y cómo interactúa.
Una visualización clara reduce significativamente este tiempo. En lugar de buscar entre miles de archivos, un nuevo empleado puede consultar el diagrama para entender los puntos de entrada. Puede ver dónde entra los datos, cómo se transforman y dónde se almacenan.
- Reducción del cambio de contexto:Los desarrolladores dedican menos tiempo a entender el sistema y más tiempo a escribir código.
- Depuración más rápida:Cuando surge un problema, el equipo puede señalar el diagrama para formular hipótesis sobre dónde ocurrió el fallo.
- Mejor colaboración:Diferentes equipos pueden trabajar en diferentes paquetes con confianza, sabiendo que los límites están claros.
La documentación no debe ser texto estático. Debe ser un artefacto vivo que evolucione junto con la base de código. Trata el diagrama como un componente crítico del software, al igual que el código mismo.
🚀 Reflexiones finales sobre la visualización de datos
Visualizar el flujo de datos entre paquetes es una práctica fundamental para cualquier equipo maduro de ingeniería de software. Transforma una colección caótica de archivos en un sistema estructurado y comprensible. Al seguir un enfoque disciplinado para crear y mantener estos diagramas, reduces el riesgo y mejoras la calidad general de la aplicación.
El esfuerzo necesario para documentar estos flujos rinde dividendos en tiempo de mantenimiento reducido, menos incidentes en producción y un equipo más cohesionado. No se trata de crear burocracia; se trata de crear claridad. En un entorno donde la complejidad es inevitable, la claridad es el activo más valioso que puedes poseer.
Empieza mapeando tu arquitectura actual. Identifica los paquetes, rastrea los datos y destaca las dependencias. Es posible que encuentres áreas que requieren atención inmediata. Utiliza esta información para guiar tus esfuerzos de refactorización. Con el tiempo, el sistema se volverá más resistente y más fácil de extender. Este es el camino hacia el desarrollo sostenible de software.