











Concevoir une base de données ne consiste pas seulement à stocker des données ; il s’agit de structurer l’information de manière à garantir l’intégrité, réduire la redondance et optimiser les performances. Lorsqu’on parle de structures de bases de données efficaces, deux piliers se détachent : Diagrammes Entité-Relation (DER) et Normalisation. Ces concepts ne sont pas des techniques isolées, mais des outils complémentaires qui s’associent pour créer une fondation de données solide.
Ce guide explore la manière de combiner la clarté visuelle des DER avec le rigueur structurelle de la normalisation. Nous passerons en revue le processus de transformation d’un modèle conceptuel en un schéma pratique qui résistera à l’épreuve du temps.
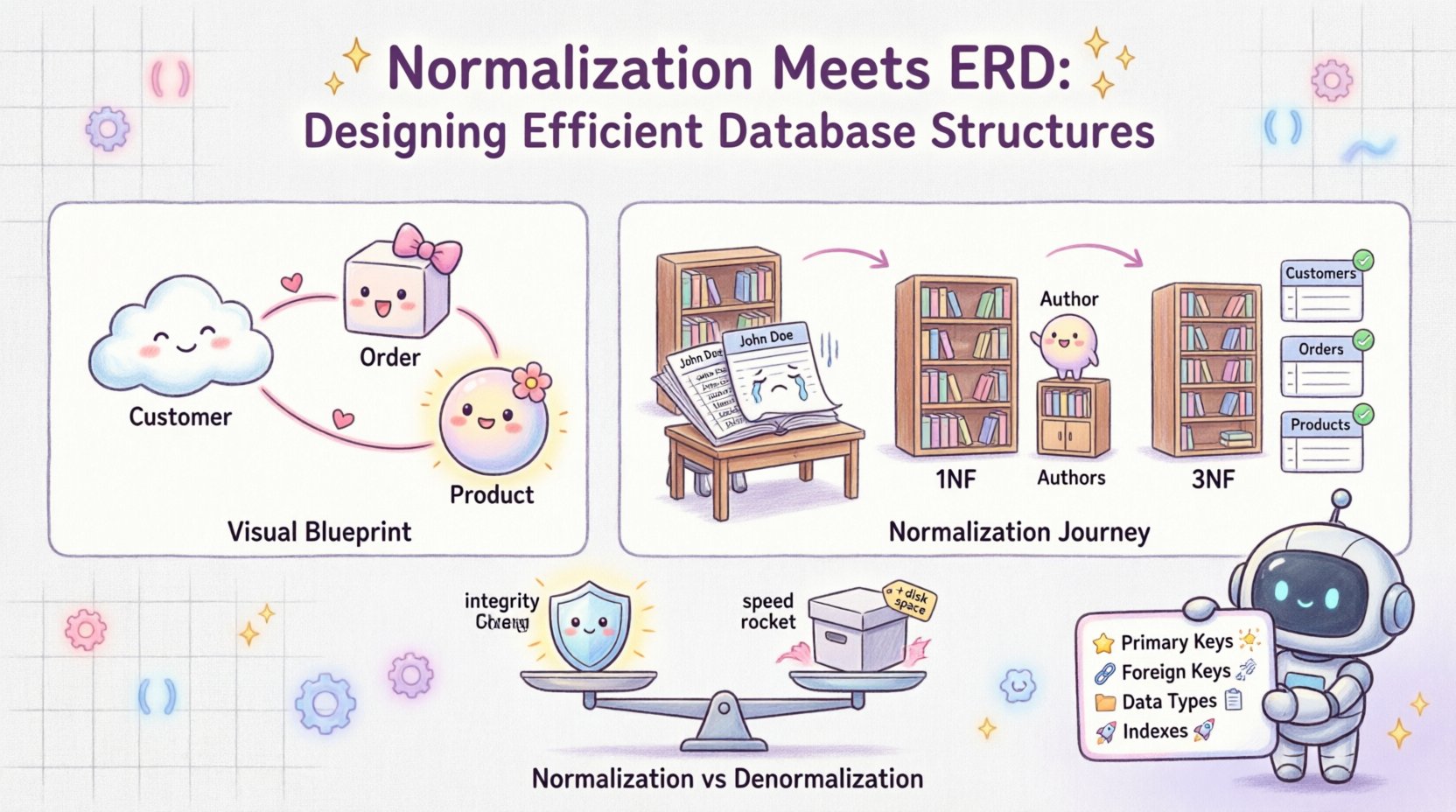
📐 Comprendre la fondation : les DER et la normalisation
Avant de plonger dans le processus de conception, il est essentiel de comprendre les rôles distincts de ces deux méthodologies.
📊 Qu’est-ce qu’un diagramme Entité-Relation ?
Un diagramme Entité-Relation sert de plan visuel pour une base de données. Il représente les entités (tables), les attributs (colonnes) et les relations (liens) entre elles. Pensez-y comme un plan architectural pour un bâtiment. Il répond à des questions telles que :
- Quels sont les objets principaux de notre système ? (par exemple, Client, Commande)
- Comment ces objets interagissent-ils ? (par exemple, un Client place de nombreuses Commandes)
- Quelles données devons-nous stocker pour chaque objet ? (par exemple, Client nécessite un Nom et Email)
Sans un DER, la conception d’une base de données devient un jeu de devinettes. Il fournit une vue d’ensemble que les parties prenantes peuvent comprendre, garantissant que tous s’entendent sur les exigences de données avant qu’une seule ligne de code ne soit écrite.
🧼 Qu’est-ce que la normalisation ?
La normalisation est le processus d’organisation des données dans une base de données afin de réduire la redondance et d’améliorer l’intégrité des données. Elle consiste à diviser les grandes tables en structures logiques plus petites et à définir des relations entre elles. L’objectif est de s’assurer que chaque morceau de données est stocké à un seul endroit.
Pourquoi cela importe-t-il ?
- Intégrité des données : Si l’adresse d’un client change, vous la mettez à jour à un seul endroit, et non à dix.
- Efficacité du stockage : Moins de données redondantes signifient une utilisation moindre de l’espace disque.
- Maintenance : Plus facile à maintenir et à mettre à jour le schéma au fil du temps.
⚙️ L’intersection : fusionner le MCD avec la normalisation
La conception d’une base de données commence souvent par un MCD, mais un MCD brut est rarement prêt pour la production. Il contient souvent des redondances que la normalisation corrige. Le processus consiste à créer un MCD conceptuel, à l’analyser pour détecter des anomalies, puis à appliquer les règles de normalisation afin de raffiner le schéma.
Voici le workflow typique :
- Conception conceptuelle : Dessinez le MCD initial en fonction des exigences.
- Conception logique : Affinez le MCD en tables et colonnes.
- Normalisation : Appliquez les formes de normalisation (1NF, 2NF, 3NF) pour éliminer les anomalies.
- Conception physique : Optimisez pour le moteur de base de données spécifique et les besoins de performance.
🔍 Étapes par étapes : du MCD au schéma normalisé
Examinons un scénario pratique pour voir comment cela fonctionne en pratique. Imaginez que nous développons un système pour gérer une bibliothèque.
1. L’état non normalisé
Au départ, vous pourriez concevoir une seule table pour stocker toutes les informations sur les livres et les auteurs. Cela s’appelle une table non normalisée.
| ID_Livre | Titre | NomAuteur | TéléphoneAuteur | Genre |
|---|---|---|---|---|
| 101 | Le Grand Roman | Jean Dupont | 555-0101 | Fiction |
| 102 | Le livre du mystère | Jean Dupont | 555-0101 | Mystère |
| 103 | Un autre livre | Jeanne Smith | 555-0102 | Fiction |
Remarquez les problèmes ici ? Jean Dupontle numéro de téléphone est répété. Si il change de numéro, vous devez mettre à jour plusieurs lignes. C’est une Anomalie de mise à jour.
2. Première forme normale (1NF)
La première règle de normalisation est d’assurer l’atomicité. Chaque colonne ne doit contenir qu’une seule valeur, et il ne doit pas y avoir de groupes répétés.
- Règle : Éliminez les groupes répétés et assurez-vous des valeurs atomiques.
- Application : Dans notre exemple de bibliothèque, le tableau initial pourrait déjà être atomique, mais nous devons nous assurer d’avoir une clé primaire. Supposons que BookID est unique.
- Résultat : Nous avons maintenant un tableau où chaque cellule contient une seule pièce de données.
3. Deuxième forme normale (2NF)
Une fois qu’un tableau est en 1NF, nous vérifions les dépendances partielles. Un tableau est en 2NF s’il est en 1NF et que chaque attribut non clé dépend entièrement de la clé primaire.
- Scénario : Si nous avions une clé composite (par exemple, BookID + AuthorID), nous vérifierions si AuthorPhone dépend de toute la clé ou seulement de la partie auteur.
- Action : Dans notre exemple, AuthorPhone dépend de AuthorName, pas de la BookID. Cela suggère que nous devrions séparer les données auteur des données livre.
4. Troisième forme normale (3NF)
C’est là que le vrai miracle se produit. La 3NF élimine les dépendances transitives. Les attributs non clés ne doivent pas dépendre d’autres attributs non clés.
- Règle :Aucun attribut ne doit dépendre d’un autre attribut non clé.
- Application : AuthorPhone dépend de AuthorName. Étant donné que AuthorName n’est pas la clé primaire de la table livre, nous déplaçons les informations auteur vers une table séparée Authors table.
- Résultat : Maintenant, mettre à jour le numéro de téléphone d’un auteur nécessite de modifier seulement un enregistrement dans la Auteurs table, et non plusieurs enregistrements dans la Livres table.
📋 Normalisation vs. Dénormalisation : Trouver un équilibre
Bien que la normalisation soit cruciale pour l’intégrité, elle n’est pas toujours la solution pour les performances. Parfois, la lecture des données est plus fréquente que l’écriture. Dans ces cas, la dénormalisation pourrait être bénéfique.
📉 Quand dénormaliser
La dénormalisation consiste à ajouter des données redondantes à une base de données normalisée afin d’améliorer les performances de lecture. C’est un compromis entre le stockage et la vitesse.
- Volume élevé de lectures : Si votre application interroge les données des milliers de fois par seconde, la jointure des tables peut ralentir les performances.
- Tableaux de bord de reporting : Les données agrégées pourraient être pré-calculées et stockées afin d’éviter des requêtes complexes.
- Stratégies de mise en cache : Parfois, les vues dénormalisées agissent comme une mémoire cache pour les données fréquemment consultées.
Cependant, cela comporte des risques. Vous devez gérer manuellement ou à l’aide de déclencheurs la synchronisation des données redondantes. Si ce n’est pas fait avec soin, l’intégrité des données en pâtit.
| Facteur | Normalisation | Dénormalisation |
|---|---|---|
| Intégrité des données | Élevée (source unique de vérité) | Moins élevée (nécessite une logique de synchronisation) |
| Vitesse d’écriture | Plus lente (plusieurs tables) | Plus rapide (moins de jointures) |
| Vitesse de lecture | Plus lente (plusieurs jointures) | Plus rapide (moins de jointures) |
| Stockage | Efficient | Redondant |
🛠️ Les pièges courants dans la conception des bases de données
Même les concepteurs expérimentés commettent des erreurs. Évitez ces pièges courants pour garantir que votre structure de base de données reste saine.
❌ Ignorer les types de données
Choisir le mauvais type de données peut entraîner un gaspillage d’espace de stockage et des problèmes de performance. Utiliser un champ texte pour les dates ou des entiers pour les numéros de téléphone gaspille de l’espace et complique la validation.
❌ Sur-normalisation
Forcer la 5NF ou la BCNF (forme normale de Boyce-Codd) dans chaque scénario peut rendre les requêtes incroyablement complexes. Parfois, la 3NF suffit. Ne normalisez pas simplement par souci de normalisation.
❌ Clés primaires faibles
Utiliser des clés naturelles (comme les adresses e-mail) comme clés primaires peut être risqué si les données changent. Les clés surrogates (entiers auto-incrémentés ou UUIDs) sont souvent plus sûres pour les relations internes.
❌ Index manquants
Un schéma bien normalisé peut encore avoir de mauvaises performances sans indexation appropriée. Identifiez les colonnes utilisées fréquemment dans lesWHERE, JOIN, ou ORDER BY clauses et indexez-les.
🔄 Le processus itératif de conception
La conception d’une base de données est rarement linéaire. C’est un processus itératif. Vous pouvez commencer par un MCD, le normaliser, réaliser que la performance est un problème, le dénormaliser légèrement, puis revenir au MCD pour vous assurer que les relations restent exactes.
🔄 Étapes de raffinement
- Revoyez les exigences : De nouvelles fonctionnalités nécessitent-elles de nouvelles tables ?
- Analyse des requêtes : Examinez les requêtes les plus lentes et identifiez les goulets d’étranglement.
- Vérification des contraintes : Assurez-vous que les clés étrangères sont correctement définies pour éviter les enregistrements orphelins.
- Documentation : Gardez votre MCD à jour. Un schéma obsolète est pire qu’aucun schéma.
📈 Considérations sur les performances
La normalisation traite principalement l’intégrité des données. Les performances constituent une préoccupation distincte qui nécessite souvent un ajustement. Toutefois, les deux sont liées.
🚀 Complexité des jointures
Les bases de données fortement normalisées nécessitent plus de JOINTURE opérations pour récupérer des données liées. Les moteurs de base de données modernes sont très bons pour optimiser les jointures, mais un trop grand nombre de jointures peut encore affecter la latence.
📦 Moteur de stockage
Les différents moteurs de stockage traitent les données différemment. Certains privilégient le stockage par lignes, tandis que d’autres privilégient le stockage par colonnes. Votre stratégie de normalisation pourrait devoir s’adapter en fonction du moteur sous-jacent.
🔒 Contraintes et déclencheurs
Imposer les règles de normalisation via des contraintes (comme les clés étrangères) garantit la qualité des données. Toutefois, une utilisation excessive de déclencheurs pour la validation peut ralentir les opérations d’écriture. Utilisez-les avec prudence.
🧩 Exemple du monde réel : système de commande pour e-commerce
Examinons un scénario légèrement plus complexe : une boutique en ligne.
Concept initial du schéma ERD
Au départ, vous pourriez avoir une Commande table qui inclut les noms des produits, les prix et les détails du client. Il s’agit de l’approche classique « fichier plat ».
Approche normalisée
Pour corriger cela, nous divisons les données :
- Table Clients : Stocke les informations du client (Nom, Adresse, Email).
- Table Produits : Stocke les informations du produit (Nom, Prix, Stock).
- Table Commandes : Stocke la transaction (IDClient, DateCommande, Total).
- Table LignesCommande : Lie les commandes et les produits (IDCommande, IDProduit, Quantité, PrixAuMoment).
Cette structure nous permet de :
- Mettre à jour le prix d’un produit à un seul endroit (la Produits table).
- Suivre les prix historiques dans la CommandeProduits table (instantanéisation).
- Assurez-vous qu’un client ne puisse pas être supprimé s’il a des commandes ouvertes (via des clés étrangères).
🎯 Liste de contrôle des meilleures pratiques
Avant de déployer votre schéma, passez en revue cette liste de contrôle pour garantir la qualité.
- ✅ Clés primaires : Chaque table possède un identifiant unique.
- ✅ Clés étrangères : Les relations sont explicitement définies.
- ✅ Nullabilité : Les colonnes sont marquées comme
NON NULLlà où cela est approprié. - ✅ Types de données : Utilisez le type de données le plus précis possible.
- ✅ Conventions de nommage : Utilisez des noms cohérents et clairs pour les tables et les colonnes.
- ✅ Documentation : Le MCD correspond au schéma physique.
- ✅ Stratégie de sauvegarde : Prenez en compte l’impact du schéma sur les temps de sauvegarde et de restauration.
🔮 L’avenir de la conception des bases de données
À mesure que la technologie évolue, les principes fondamentaux de la normalisation et des diagrammes entité-relations restent pertinents. Bien que les bases de données NoSQL offrent une flexibilité, le modèle relationnel domine encore les systèmes transactionnels. Comprendre les fondamentaux vous permet d’adapter votre approche aux nouvelles technologies sans perdre la rigueur de la modélisation des données.
Les bases de données cloud introduisent de nouvelles dimensions, telles que le fractionnement et le partitionnement. Toutefois, la structure logique que vous concevez à l’aide des diagrammes entité-relations et de la normalisation reste le plan directeur pour la distribution et l’accès à ces données.
📝 Résumé des points clés à retenir
Concevoir des structures de base de données efficaces consiste à trouver un équilibre entre structure et flexibilité. Voici ce que vous devez retenir :
- Les diagrammes entité-relations sont des guides visuels : Ils cartographient les relations avant que vous ne construisiez.
- La normalisation est structurale : Elle organise les données afin de réduire les redondances.
- La 3NF est l’objectif :Viser la Troisième Forme Normale pour la plupart des systèmes transactionnels.
- Dénormalisez avec sagesse :N’ajoutez des redondances que lorsque les performances le nécessitent.
- Itérez :La conception n’est jamais terminée ; elle évolue avec l’application.
En combinant la clarté visuelle des diagrammes entité-relations avec les règles rigoureuses de la normalisation, vous créez une fondation de données fiable et évolutif. Cette approche garantit que votre base de données peut évoluer avec votre application, en gérant la complexité sans compromettre l’intégrité.
Commencez par un diagramme entité-relations propre. Appliquez les règles de normalisation étape par étape. Testez vos requêtes. Affinez votre schéma. Et privilégiez toujours l’intégrité des données par rapport à la vitesse en phase initiale.