











Les applications web modernes sont des écosystèmes complexes. Elles ne sont pas simplement des collections de fichiers, mais des systèmes interconnectés où les données circulent entre des frontières logiques distinctes. À mesure que les systèmes grandissent, maintenir une clarté devient un défi majeur. Les développeurs se retrouvent souvent à naviguer dans du code spaghetti où l’origine d’une donnée est floue et sa destination incertaine. Ce manque de visibilité entraîne un endettement technique, des dépendances fragiles et un temps accru passé au débogage.
Ce guide explore une approche concrète pour visualiser le flux de données à travers les packages. En nous concentrant sur les diagrammes de packages, nous établissons un plan directeur pour comprendre comment les informations circulent à travers l’architecture. Ce processus est essentiel pour maintenir une base de code saine, en s’assurant que les modifications dans une zone ne brisent pas involontairement la fonctionnalité dans une autre. Nous examinerons la méthodologie, les étapes spécifiques impliquées, ainsi que les bénéfices à long terme de la maintenance d’une documentation architecturale claire.
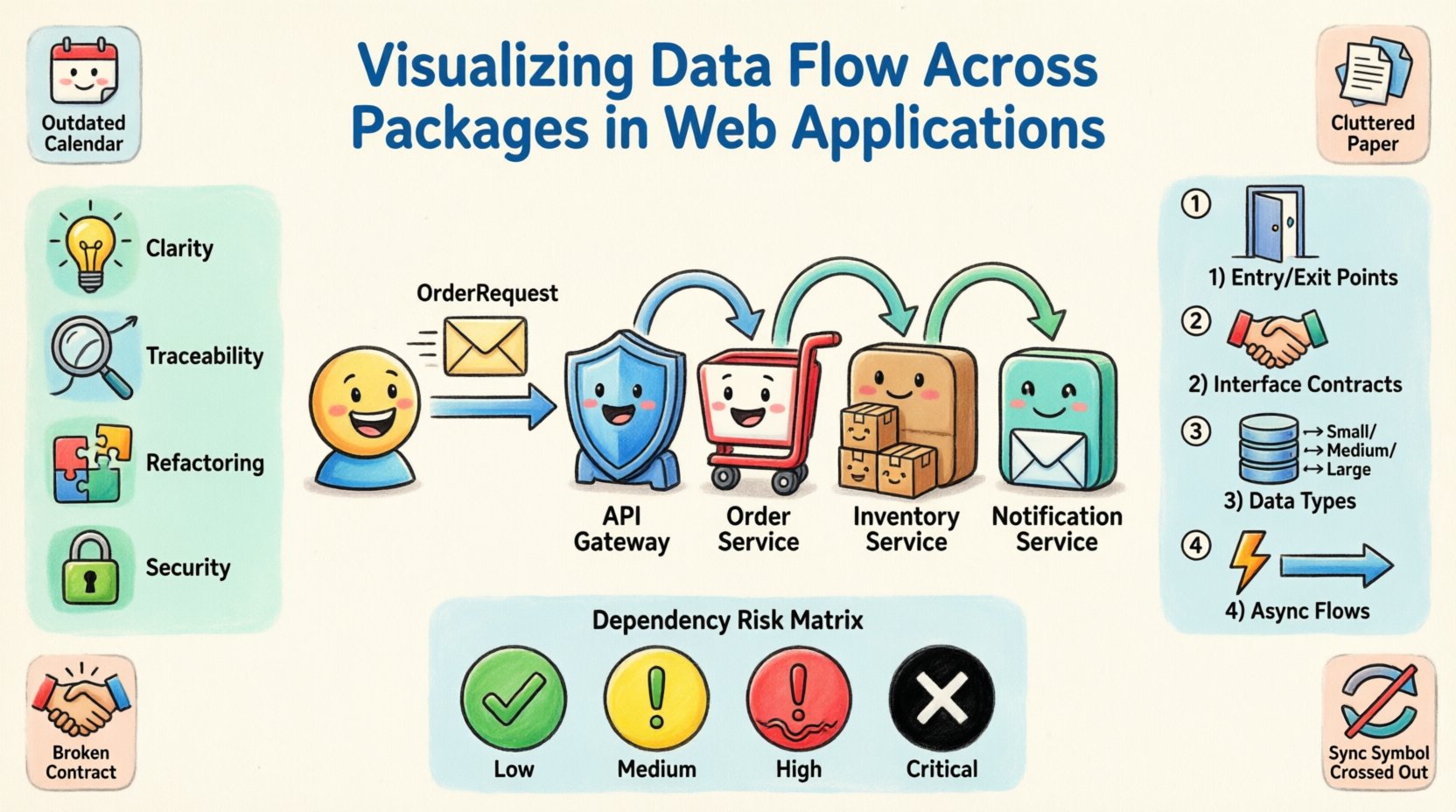
📐 Comprendre les diagrammes de packages et leur objectif
Un diagramme de package est un diagramme structurel qui montre l’organisation d’un système en groupes logiques. Dans le contexte d’une application web, un package représente souvent un domaine spécifique, un module ou une frontière de service. Ce n’est pas simplement une structure de dossiers ; c’est une représentation de l’intention du système.
Quand nous parlons de visualisation du flux de données, nous allons au-delà de la structure statique. Nous nous intéressons au mouvement dynamique de l’information. Pourquoi cette distinction est-elle importante ?
- Clarté : Elle aide les nouveaux membres de l’équipe à comprendre comment fonctionne le système sans avoir à lire chaque ligne de code.
- Traçabilité : Lorsqu’une erreur survient, vous pouvez suivre le parcours des données pour identifier la source.
- Refactoring : Elle vous permet de voir quels composants sont étroitement couplés avant d’entreprendre leur restructuration.
- Sécurité : Elle met en évidence les endroits où les données sensibles sont transmises et s’assure qu’elles passent par des couches de validation nécessaires.
Sans cette visualisation, les développeurs s’appuient souvent sur des modèles mentaux qui peuvent différer de l’implémentation réelle. Cette divergence est une cause principale des bogues de régression. Un diagramme de package agit comme la source unique de vérité pour les relations architecturales.
🎯 Définir le périmètre de la visualisation
Avant de tracer des lignes entre les boîtes, vous devez définir ce qui constitue un package. Un package ne doit ni être trop granulaire, ni trop large. Si un package contient une seule classe, cela contredit l’objectif du regroupement. Si un package contient tout, il ne permet pas de séparation des préoccupations.
Le périmètre de la visualisation doit s’aligner avec les frontières de déploiement et logiques de l’application. Prenez en compte les critères suivants lors de la définition de vos packages :
- Conception axée sur le domaine (DDD) : Alignez les packages avec les domaines métiers, tels que Gestion des commandes ou Authentification des utilisateurs.
- Stratification : Séparez les préoccupations en couches telles que Interface, Logique, et Accès aux données.
- Responsabilité : Chaque package doit avoir une seule responsabilité bien définie.
- Indépendance : Les packages doivent pouvoir évoluer avec un impact minimal sur les autres.
Définir cette portée dès le départ empêche le diagramme de devenir un réseau entremêlé. Cela garantit que la visualisation reste utile au fur et à mesure de l’évolution de l’application.
🏗️ L’architecture de l’étude de cas
Pour illustrer le processus, nous examinerons une application web hypothétique conçue pour une plateforme de commerce électronique. Ce scénario implique plusieurs domaines fonctionnels nécessitant un échange de données. L’architecture est divisée en packages logiques suivants :
- Domaine central : Contient la logique métier fondamentale, les entités et les objets valeur.
- Passerelle API : Gère les requêtes entrantes, l’authentification et le routage.
- Service de gestion des stocks : Gère les niveaux de stock et la disponibilité des produits.
- Service de commandes : Traite les transactions et crée les enregistrements de commandes.
- Service de notifications : Envoie des e-mails et des alertes push aux utilisateurs.
Dans ce scénario, un utilisateur passe une commande. Les données doivent circuler de la passerelle API au service de commandes, interagir avec le service de gestion des stocks, puis déclencher une notification. Visualiser ce flux nécessite de cartographier les interfaces et les dépendances entre ces packages.
🔄 Processus de visualisation étape par étape
Créer une représentation précise du flux de données nécessite une approche méthodique. Il ne suffit pas de dessiner des boîtes ; il faut annoter les connexions avec des détails précis sur les données en cours de déplacement.
1. Identifier les points d’entrée et de sortie
Chaque package doit avoir des limites définies. Identifiez où les données entrent dans le système et où elles en sortent. Pour la passerelle API, le point d’entrée est la requête HTTP. Le point de sortie pourrait être une transaction de base de données ou un événement de file d’attente de messages. Marquez-les clairement sur le diagramme.
2. Cartographier les contrats d’interface
Les dépendances doivent être définies par des interfaces, et non par des implémentations concrètes. Lors de la cartographie du flux entre le service de commandes et le service de gestion des stocks, précisez les méthodes d’interface appelées. Cela découple les packages et rend le diagramme plus stable.
- Entrée : Quelles données sont nécessaires ? (par exemple,
OrderRequest,IdentifiantUtilisateur) - Sortie : Quels données sont retournées ? (par exemple,
StatutStock,IdentifiantTransaction) - Erreurs : Comment les échecs sont-ils communiqués ? (par exemple,
ExceptionDélaiDépassé,ErreurDonnéesNonValides)
3. Annoter les types et volumes de données
Tous les flux de données ne sont pas égaux. Certains sont de petites mises à jour de métadonnées, tandis que d’autres sont des transferts de fichiers volumineux. Annoter le type et le volume des données aide à la planification des performances. Par exemple, le service de notification pourrait gérer un grand volume de petits messages, tandis que le service d’inventaire pourrait gérer de grandes mises à jour par lots.
4. Mettre en évidence les flux asynchrones
Les applications modernes reposent souvent sur une communication asynchrone. Si le service de commande ne patiente pas immédiatement pour la réponse du service d’inventaire, il s’agit d’un détail architectural critique. Distinct entre les appels synchrones (bloquants) et les événements asynchrones (envoyer et oublier). Utilisez des styles de traits différents pour représenter visuellement ces interactions.
🔗 Analyse des dépendances et du couplage
Une fois le schéma dessiné, le vrai travail commence : l’analyse. Vous devez rechercher des signes de couplage malsain. Le couplage fait référence au degré d’interdépendance entre les modules logiciels.
Un fort couplage signifie qu’une modification dans un package nécessite des modifications dans un autre. Cela réduit la flexibilité et augmente le risque de modifications cassantes. L’objectif est d’atteindre un faible couplage tout en maintenant une forte cohésion (où les éléments au sein d’un package sont étroitement liés).
Pendant le processus de revue, recherchez les motifs suivants :
- Dépendances circulaires : Le package A dépend de B, et B dépend de A. Cela crée un blocage lors de la compilation et de la logique.
- Couplage caché : Des dépendances qui existent uniquement à travers des variables statiques partagées ou un état global.
- Packages Dieu : Un seul package qui dépend de presque tout le reste, ou qui est dépendu par presque tout le reste.
- Abstractions fuyantes : Où les détails d’implémentation d’un package sont exposés à un autre.
Matrice de risque des dépendances
Pour aider à évaluer l’état de santé de votre architecture, utilisez une matrice de risque pour catégoriser les dépendances en fonction de leur impact.
| Type de dépendance | Niveau de couplage | Score de risque | Action recommandée |
|---|---|---|---|
| Dépendance d’interface | Faible | Faible | Acceptable |
| Dépendance de bibliothèque partagée | Moyen | Moyen | Réviser régulièrement |
| Dépendance directe de classe | Élevé | Élevé | Refactoriser vers une interface |
| Dépendance d’état global | Très élevé | Critique | Éliminer immédiatement |
| Dépendance circulaire | Bloqué | Critique | Réorganiser l’architecture |
⚠️ Pièges courants de visualisation
Même avec une méthodologie claire, des erreurs peuvent survenir au cours du processus de documentation. Être conscient des pièges courants aide à maintenir l’exactitude de vos diagrammes.
- Diagrammes obsolètes : Le problème le plus courant est une documentation qui suit de près le code. Si le code change et que le diagramme ne change pas, le diagramme devient du bruit. Établissez une règle selon laquelle le diagramme fait partie de la définition de terminé pour toute fonctionnalité majeure.
- Sur-abstraction : Créer un diagramme trop général ne fournit aucune information exploitée. Incluez suffisamment de détails pour comprendre les types de données et le sens du flux.
- Sous-abstraction : Inclure chaque appel de méthode rend la vue confuse. Concentrez-vous sur le flux de haut niveau et sur le chemin critique.
- Ignorer les contrats de données : Se concentrer uniquement sur le flux de contrôle (qui appelle qui) sans montrer le flux de données (ce qui est transmis) rend le diagramme moins utile pour le débogage.
- Supposer un flux synchrone : De nombreux systèmes sont pilotés par des événements. Supposer des appels synchrones dans un diagramme peut entraîner des malentendus concernant la latence et la fiabilité.
🛡️ Préserver l’intégrité architecturale
Créer le diagramme n’est que la première étape. Le maintenir exige de la discipline. L’intégrité architecturale n’est pas une tâche ponctuelle ; c’est un processus continu de vérification et d’ajustement.
Une stratégie efficace consiste à intégrer la vérification du diagramme dans le pipeline de construction. Des outils automatisés peuvent vérifier que la structure du code correspond aux dépendances documentées. Si une nouvelle dépendance est introduite sans mettre à jour le diagramme, la construction peut échouer ou générer un avertissement. Cela oblige les développeurs à maintenir la documentation à jour.
Une autre stratégie consiste en des revues architecturales régulières. Prévoyez des sessions trimestrielles où l’équipe passe en revue les diagrammes. Discutez des modifications récentes et mettez à jour la visualisation pour refléter l’état actuel du système. Cela garantit que les connaissances restent réparties au sein de l’équipe et ne sont pas isolées dans la tête d’une seule personne.
🤝 Intégration et transfert de connaissances
L’un des résultats les plus précieux d’un diagramme de paquetage bien maintenu est une meilleure intégration. Lorsqu’un nouveau développeur rejoint l’équipe, il fait face à une courbe d’apprentissage abrupte. Il doit comprendre où se trouve le code et comment il interagit.
Une visualisation claire réduit considérablement ce temps. Au lieu de chercher à travers des milliers de fichiers, un nouveau membre de l’équipe peut consulter le diagramme pour comprendre les points d’entrée. Il peut voir où les données entrent, comment elles sont transformées et où elles sont stockées.
- Moins de changements de contexte :Les développeurs passent moins de temps à comprendre le système et plus de temps à écrire du code.
- Débogage plus rapide :Lorsqu’un problème survient, l’équipe peut pointer vers le diagramme pour formuler une hypothèse sur l’endroit où l’échec s’est produit.
- Meilleure collaboration :Des équipes différentes peuvent travailler sur des paquetages différents avec confiance, sachant que les limites sont claires.
La documentation ne doit pas être un texte statique. Elle doit être un artefact vivant qui évolue avec la base de code. Traitez le diagramme comme un composant essentiel du logiciel, tout comme le code lui-même.
🚀 Réflexions finales sur la visualisation des données
Visualiser le flux de données entre les paquetages est une pratique fondamentale pour toute équipe mature de génie logiciel. Elle transforme une collection chaotique de fichiers en un système structuré et compréhensible. En suivant une approche disciplinée pour créer et entretenir ces diagrammes, vous réduisez les risques et améliorez la qualité globale de l’application.
L’effort requis pour documenter ces flux se traduit par des dividendes en temps de maintenance réduit, moins d’incidents en production et une équipe plus cohésive. Il ne s’agit pas de créer de la bureaucratie ; il s’agit de créer de la clarté. Dans un environnement où la complexité est inévitable, la clarté est l’actif le plus précieux que vous puissiez posséder.
Commencez par cartographier votre architecture actuelle. Identifiez les paquetages, suivez les données et mettez en évidence les dépendances. Vous pourriez découvrir des zones nécessitant une attention immédiate. Utilisez ces informations pour guider vos efforts de refactoring. Au fil du temps, le système deviendra plus résilient et plus facile à étendre. Tel est le chemin vers un développement logiciel durable.