











Construire une boutique en ligne fiable exige bien plus qu’une simple interface front-end. Le pilier de tout marché numérique réussi réside dans son architecture des données. Un diagramme d’entités et de relations (ERD) sert de plan directeur pour le stockage, les liens et la récupération des informations. Lorsqu’on conçoit pour l’évolutivité, la complexité augmente considérablement. Il faut trouver un équilibre entre l’intégrité des données et les performances, en garantissant que chaque transaction s’exécute sans accroc, même sous une charge élevée.
Ce guide explore les composants essentiels de la conception de base de données pour le commerce électronique. Nous examinerons les entités fondamentales, leurs relations et les modèles nécessaires pour supporter un trafic élevé. En suivant ces principes structurels, vous pourrez construire un système stable même à mesure que votre base de clients croît. L’accent est mis sur la conception logique, la normalisation et les stratégies visant à prévenir les goulets d’étranglement avant qu’ils ne surviennent.
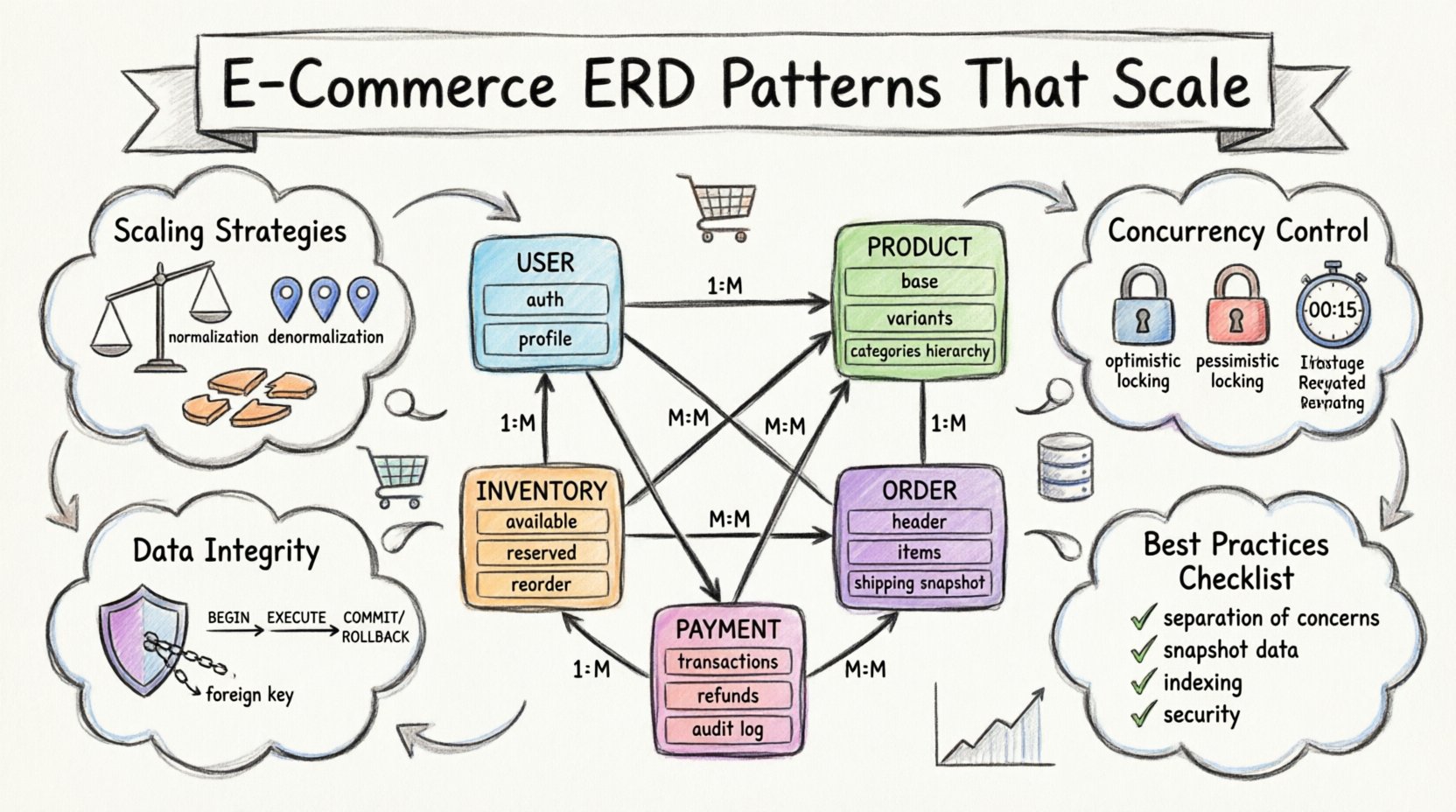
Entités fondamentales et relations principales 🏗️
Chaque plateforme de commerce électronique commence par les points de données fondamentaux qui définissent l’activité. Cela inclut qui sont les clients, ce qu’ils achètent et comment les articles sont catégorisés. La conception de ces tables principales détermine la flexibilité de l’ensemble du système.
1. L’entité Utilisateur
La table utilisateur est le point d’entrée pour l’authentification et la gestion du profil. Toutefois, séparer les identifiants d’authentification des détails du profil utilisateur est une pratique courante. Cette séparation permet de mettre à jour la sécurité sans perturber la structure globale des données utilisateur.
- Données d’authentification :Stocke les identifiants, les jetons de session et l’état du compte. Ces données nécessitent une sécurité élevée et une exposition minimale.
- Données de profil :Contient les noms, les informations de contact et les préférences de livraison. Ces données sont plus fréquemment mises à jour.
- Relations :Une relation un-à-plusieurs existe entre les utilisateurs et leur historique de commandes. Chaque utilisateur peut avoir plusieurs commandes, mais chaque commande appartient à un seul utilisateur.
Il est important de tenir compte des réglementations sur la vie privée à ce stade. Le stockage d’informations personnelles identifiables (PII) nécessite un traitement spécifique. Le chiffrement au repos et des contrôles d’accès stricts sont des pratiques standard pour cette entité.
2. Le catalogue de produits
La gestion des produits est souvent la partie la plus complexe du schéma de commerce électronique. Un article physique unique peut exister sous plusieurs variantes, telles que la taille ou la couleur. Cela nécessite une structure souple qui n’exige pas de modifications constantes du schéma.
- Table de base des produits :Stocke des informations générales telles que le titre, la description et le prix de base.
- Table des variantes :Stocke des attributs spécifiques tels que le SKU, la couleur, la taille et les prix individuels.
- Table des catégories :Définit la hiérarchie. Les catégories peuvent être imbriquées, ce qui nécessite une relation auto-référente ou une stratégie d’énumération de chemins.
La dénormalisation est souvent envisagée ici. Bien que la normalisation réduise la redondance, la lecture des données pour une page de liste de produits nécessite des jointures sur plusieurs tables. Dans les scénarios à fort trafic, le cache des données jointes ou la dénormalisation de champs spécifiques peut améliorer la vitesse des requêtes.
3. Gestion des stocks et de l’inventaire
Le suivi des niveaux de stock est crucial pour éviter les ventes excessives. La table d’inventaire doit être directement liée aux variantes de produits. Elle doit stocker la quantité disponible actuelle, la quantité réservée et la capacité totale.
- Stock disponible :Le nombre d’articles prêts à être achetés immédiatement.
- Stock réservé :Articles conservés dans le panier d’un client pendant le processus de paiement.
- Point de réapprovisionnement : Un seuil qui déclenche des alertes pour le réapprovisionnement.
La concurrence est un défi majeur ici. Si deux utilisateurs tentent d’acheter le dernier article simultanément, le système doit empêcher les deux d’aboutir. Cela implique généralement des transactions de base de données qui verrouillent la ligne d’inventaire spécifique pendant le processus de mise à jour.
Architecture transactionnelle et traitement des commandes 🛒
Le cycle de vie d’une commande est le battement du cœur de la plateforme. Il représente le transfert de valeur du client au marchand. La conception de la base de données doit soutenir les changements d’état qui se produisent du panier à la livraison.
Structure de l’entité commande
Un enregistrement de commande est une capture d’écran de la transaction à un moment donné. Il ne doit pas simplement faire référence au prix actuel du produit. Si le prix change après la passation de la commande, l’enregistrement historique doit rester précis.
- En-tête de commande : Contient l’ID de commande, l’ID utilisateur, le montant total, les taxes, le coût de livraison et l’état de la commande.
- Articles de commande : Une table de jonction reliant les commandes aux produits. Cette table enregistre la variante spécifique, la quantité et le prix au moment de l’achat.
- Adresse de livraison : Stocker l’adresse au moment de la commande est plus sûr que de la lier au profil actuel de l’adresse de l’utilisateur.
Gestion des états
Les commandes passent par divers états. Un champ d’état bien conçu permet au système de suivre l’évolution sans nécessiter des jointures complexes. Les états courants incluent :
- En attente : Commande créée mais non encore payée.
- Payée :Paiement confirmé.
- En traitement :Inventaire alloué et en préparation.
- Expédiée :Article expédié avec des informations de suivi.
- Livré :Le client a reçu l’article.
- Remboursée :Argent rendu au client.
Utiliser un type énuméré pour l’état garantit la cohérence des données. Il empêche les fautes de frappe qui pourraient briser les scripts d’automatisation dépendant de valeurs d’état spécifiques.
Paiements et enregistrements financiers 💳
Les données financières exigent le plus haut niveau de précision. Vous ne pouvez pas vous fier uniquement à la logique d’application standard pour les transactions d’argent. La base de données doit enregistrer chaque transaction financière comme un événement distinct.
- Transactions de paiement : Chaque tentative de paiement doit créer un enregistrement. Cela inclut la réponse de la passerelle, la méthode utilisée et le résultat final.
- Remboursements : Un remboursement est une transaction distincte liée au paiement initial. Il ne doit pas simplement annuler l’enregistrement initial.
- Calculs de taxes : Les taux de taxe varient selon l’emplacement. Le stockage du montant de taxe appliqué par article de commande garantit la traçabilité.
La journalisation d’audit est essentielle ici. Chaque modification d’un enregistrement financier doit être journalisée avec une horodatage et l’identifiant de l’utilisateur effectuant l’action. Cela fournit une trace pour la résolution des litiges et les audits internes.
Stratégies d’évolutivité pour un volume élevé 📈
À mesure que le trafic augmente, la base de données devient un goulot d’étranglement. L’évolutivité standard implique une évolutivité verticale (ajouter plus de puissance à un seul serveur), mais cela a des limites. L’évolutivité horizontale (ajouter plus de serveurs) nécessite une planification soigneuse de la distribution des données.
1. Normalisation vs. Dénormalisation
La normalisation réduit la duplication des données. Elle est la norme pour l’intégrité des transactions. Cependant, les requêtes complexes qui joignent de nombreuses tables peuvent devenir lentes à mesure que le volume de données augmente.
| Stratégie | Avantage | Inconvénient |
|---|---|---|
| Normalisation | Consistance des données, moins d’espace de stockage | Requêtes complexes, lectures plus lentes |
| Dénormalisation | Lectures plus rapides, requêtes plus simples | Redondance des données, complexité des mises à jour |
Dans le commerce électronique, une approche hybride est souvent la meilleure. Gardez les tables transactionnelles principales normalisées pour assurer l’intégrité. Créez des vues dénormalisées ou des tables séparées pour les rapports et la recherche. Cela permet une navigation rapide sur les produits sans compromettre l’exactitude du traitement des commandes.
2. Stratégies d’indexation
Les index sont cruciaux pour les performances. Ils permettent à la base de données de trouver des lignes sans scanner toute la table. Cependant, trop d’index ralentissent les opérations d’écriture.
- Clés primaires : Toujours indexées. Utilisées pour les recherches directes par ID.
- Clés étrangères : Souvent indexées pour accélérer les jointures entre des tables liées.
- Index composés : Utiles pour les requêtes qui filtrent par plusieurs colonnes, telles que l’état et la date.
- Index de texte intégral : Essentiels pour la fonctionnalité de recherche de produits.
Examinez régulièrement les plans d’exécution des requêtes. Si une requête n’utilise pas d’index, la base de données peut effectuer un balayage complet de la table, ce qui dégrade les performances à mesure que l’ensemble de données augmente.
3. Partitionnement et fractionnement
Lorsqu’une seule table devient trop grande, le partitionnement la divise en morceaux plus petits et plus faciles à gérer. Cela est souvent fait par date ou par plage d’ID.
- Partitionnement par plage :Fractionner les commandes par année ou par mois. Cela permet de conserver les données récentes sur un stockage plus rapide tout en archivant les anciennes données.
- Partitionnement par hachage :Répartir les données sur plusieurs serveurs en fonction du hachage de l’ID. Cela répartit la charge de manière équilibrée.
Le fractionnement (sharding) va plus loin en répartissant les données sur plusieurs serveurs physiques. Cela exige que l’application connaisse quel shard contient les données. Il s’agit d’une décision architecturale complexe, à mettre en œuvre après avoir épuisé les possibilités de mise à l’échelle verticale.
Intégrité des données et contraintes 🔒
Les bases de données relationnelles offrent des contraintes puissantes pour maintenir la qualité des données. Faire confiance au code d’application pour appliquer les règles est risqué, car le code peut contenir des bogues. Les contraintes de base de données constituent un filet de sécurité.
1. Intégrité référentielle
Les contraintes de clé étrangère garantissent qu’une commande est toujours liée à un utilisateur et un produit valides. Si un produit est supprimé, la base de données peut être configurée pour soit empêcher la suppression, soit propager l’action aux enregistrements dépendants. Dans le commerce électronique, empêcher la suppression des produits ayant des commandes existantes est généralement le choix le plus sûr.
2. Atomicité des transactions
Une transaction regroupe plusieurs opérations en une seule unité. Soit toutes les opérations réussissent, soit aucune ne le fait. Cela est essentiel pour les mises à jour du stock. Lorsqu’une commande est passée, le stock doit diminuer. Si la mise à jour du stock échoue, l’enregistrement de la commande ne doit pas être créé.
- Débuter la transaction :Verrouille les ressources pertinentes.
- Exécuter les mises à jour :Effectuer les écritures nécessaires.
- Valider :Rend les modifications permanentes.
- Annuler :Annule les modifications en cas d’erreur.
3. Contraintes d’unicité
Les contraintes d’unicité empêchent les entrées en double. Cela est utile pour les adresses e-mail dans la table des utilisateurs ou les codes SKU dans la table des produits. Cela empêche le système de créer accidentellement des comptes en double ou des articles de stock en conflit.
Gestion de la haute concurrence ⚡
Les ventes flash et les événements à fort trafic créent des conditions de course. Plusieurs utilisateurs pourraient essayer d’acheter le même article au même milliseconde précise.
Verrouillage optimiste
Le verrouillage optimiste suppose que les conflits sont rares. Il consiste à ajouter un numéro de version à la ligne. Lors de la mise à jour, la base de données vérifie si le numéro de version correspond. Si celui-ci a changé, la mise à jour est rejetée et l’application doit réessayer.
Verrouillage pessimiste
Le verrouillage pessimiste verrouille la ligne immédiatement lors de sa lecture. Les autres transactions doivent attendre que le verrou soit libéré. Cela garantit la cohérence des données, mais peut réduire le débit en cas de forte contention.
Réservation de stock
Pour éviter la vente excessive, réservez le stock lorsque l’utilisateur ajoute un article au panier. Définissez un délai pour cette réservation. Si l’utilisateur ne termine pas la commande dans le délai imparti, le stock est libéré et remis dans le pool disponible.
Considérations relatives à la recherche et à l’analyse 📊
Les bases de données transactionnelles ne sont pas conçues pour des requêtes analytiques complexes ou une recherche full-text. Exécuter des requêtes de recherche intensives sur les tables principales des commandes ou des produits peut dégrader les performances pour les utilisateurs réguliers.
- Moteurs de recherche :Utilisez un moteur de recherche dédié pour la découverte de produits. Synchronisez les données des produits depuis la base de données principale vers le moteur de recherche de manière asynchrone.
- Entrepôts d’analyse :Déplacez les données historiques vers un entrepôt analytique distinct pour les rapports. Cela maintient la base de données transactionnelle légère.
- Réplicas de lecture :Redirigez le trafic en lecture seule vers les serveurs répliqués. Cela sépare la charge du serveur principal d’écriture.
En séparant les opérations intensives en écriture de celles intensives en lecture, vous garantissez que le processus de paiement reste rapide, même lorsque les utilisateurs naviguent ou génèrent des rapports.
Maintenance et croissance à long terme 🔄
Un design de base de données n’est pas statique. Il doit évoluer avec l’entreprise. Lorsque de nouvelles fonctionnalités sont ajoutées, le schéma peut nécessiter des ajustements.
- Gestion des versions :Suivez les versions du schéma. Cela permet des annulations sécurisées en cas d’échec d’une migration.
- Archivage :Déplacez les anciennes commandes vers un stockage froid. Cela maintient la taille des tables actives gérable.
- Surveillance :Configurez des alertes pour les requêtes lentes, les attentes de verrouillage et l’utilisation de l’espace disque. La surveillance proactive prévient les pannes.
Revoyez régulièrement le MCD par rapport aux modèles d’utilisation réels. Certaines relations qui semblaient bonnes sur papier peuvent s’avérer inefficaces en production. Soyez prêt à refactoriser lorsque les modèles de données changeront de manière significative.
Résumé des meilleures pratiques ✅
Concevoir une base de données e-commerce évolutives exige un équilibre entre structure et flexibilité. Les points suivants résument les enseignements clés pour construire un système résilient.
- Séparation des préoccupations :Maintenez les données d’authentification, de catalogue et de transaction distinctes.
- Données en instantané :Stockez les détails de la commande au moment de l’achat, et non seulement des références.
- Contrôle de concurrence :Utilisez les transactions et les verrous pour éviter la vente excessive.
- Indexation :Optimisez pour les modèles de lecture et d’écriture les plus courants.
- Évolutivité : Prévoyez la partition et le fractionnement dès les premières étapes de l’architecture.
- Sécurité : Chiffrez les données sensibles et appliquez des contrôles d’accès stricts.
En suivant ces modèles, vous créez une base solide qui soutient la croissance. La base de données devient un moteur stable qui alimente l’entreprise sans nécessiter de corrections d’urgence constantes. Concentrez-vous d’abord sur l’intégrité des données, puis optimisez pour la vitesse. Un système lent est préférable à un système incorrect.