










La conception de bases de données est le pilier de toute application logicielle robuste. Lors de la construction de systèmes traitant des données complexes, la différence entre une architecture évolutif et un désordre fragile réside souvent dans la manière dont vous organisez les informations. Au cœur de cette structure se trouvent trois piliers fondamentaux : les entités, les attributs et les relations. Comprendre ces concepts n’est pas facultatif pour un développeur ; c’est essentiel pour créer des modèles de données maintenables, efficaces et logiques.
Un diagramme d’entité et de relation (ERD) sert de plan directeur pour ces structures. Il visualise la manière dont les données sont connectées, stockées et circulent dans votre système. Sans une compréhension claire de ces composants fondamentaux, même la logique d’application la plus avancée aura des difficultés à fonctionner. Ce guide analyse chaque élément avec précision, vous assurant de concevoir des modèles de données avec confiance et clarté.
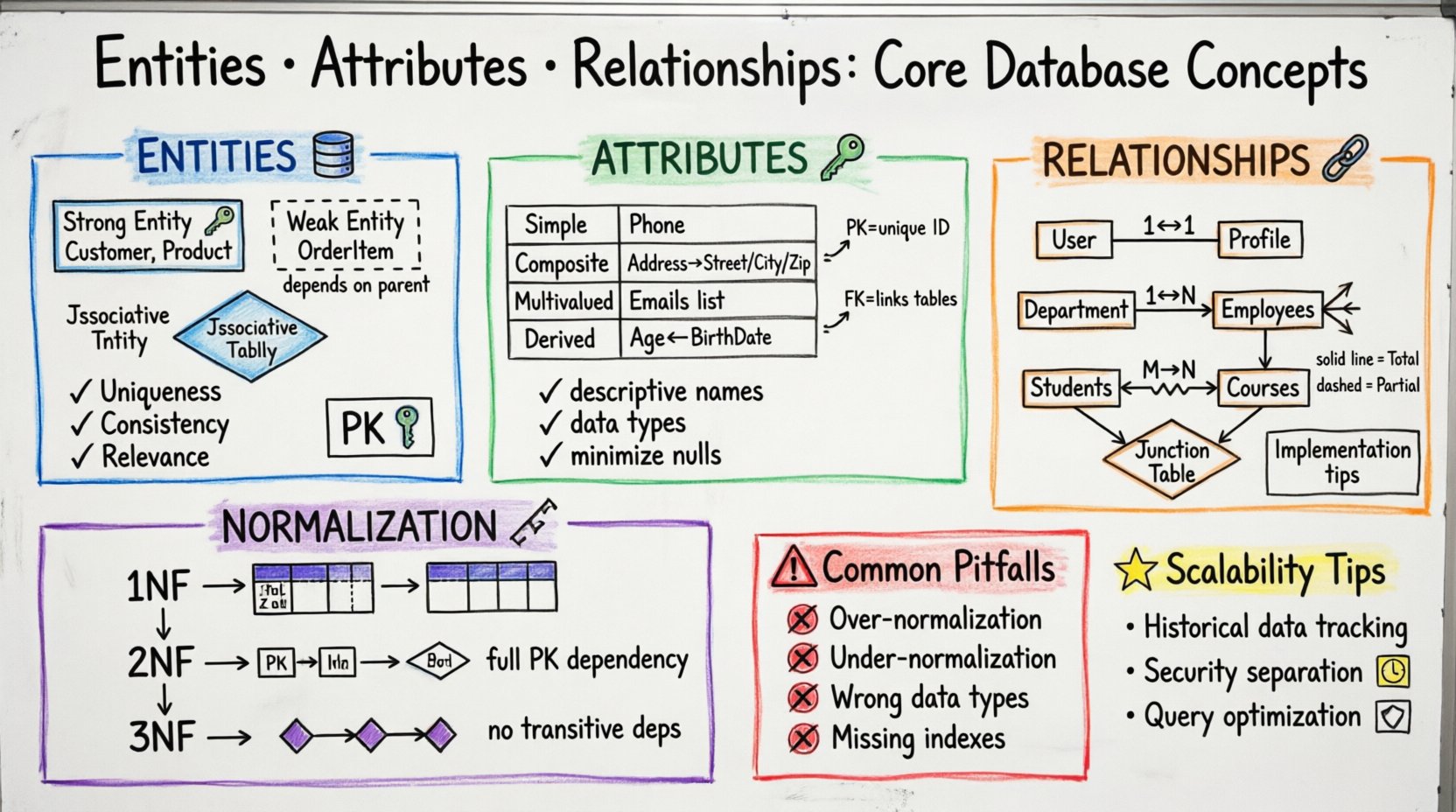
Comprendre les entités : la fondation des données 🧱
Dans le contexte de la conception de bases de données, une entité représente un objet ou un concept distinct dont vous devez stocker des informations. C’est le nom dans votre modèle de données. Pensez-y comme une catégorie ou une classe d’éléments existant dans le monde réel ou dans votre domaine métier. Chaque entité doit être unique et identifiable dans le contexte du système.
Types d’entités
Les entités ne sont pas toutes égales. Reconnaître le type d’entité avec laquelle vous avez affaire aide à définir les règles pour le stockage et la récupération des données.
- Entités fortes : Elles existent indépendamment. Elles ont leur propre clé primaire et ne dépendent pas d’autres entités pour exister. Par exemple, un Client ou un Produit peut exister seul.
- Entités faibles : Elles dépendent d’une entité forte pour exister. Elles ne peuvent pas être identifiées de manière unique sans l’entité parente. Un exemple classique est un ArticleDeCommande au sein d’une Commande. Sans le contexte de la commande, l’article n’a aucun sens dans ce schéma spécifique.
- Entités associatives : Aussi appelées tables de jonction, elles résolvent les relations many-to-many. Elles relient deux autres entités pour permettre plusieurs connexions entre elles.
Identifier les entités
Lors de la conception d’un modèle, vous devez vous demander quels objets du monde réel doivent être suivis. Cherchez les noms dans vos exigences métier. Si une règle métier impose que vous deviez suivre l’état, l’historique ou les propriétés d’un élément, cet élément est probablement une entité.
Pensez aux caractéristiques suivantes qui définissent une entité valide :
- Unicité : Chaque instance doit être distincte de toutes les autres instances.
- Consistance : La définition de l’entité doit rester cohérente à travers le système.
- Pertinence : L’entité doit servir un objectif dans la logique métier. Évitez de créer des entités pour des données peu interrogées ou peu utilisées.
Attributs : Définition des propriétés des entités 🔑
Une fois que vous avez identifié les entités, vous devez les décrire. Les attributs sont les caractéristiques, propriétés ou détails qui décrivent une entité. Si une entité est une table, un attribut est une colonne. Ensemble, ils forment l’image complète des données que vous gérez.
Clés primaires et clés étrangères
Tous les attributs ne sont pas égaux. Certains jouent un rôle crucial dans l’intégrité et le lien des données.
- Clé primaire (PK) : Un identifiant unique pour un enregistrement au sein d’une entité. Il garantit que deux lignes ne sont pas identiques. Une clé primaire peut être une seule colonne (comme un numéro d’identification) ou une clé composée constituée de plusieurs colonnes.
- Clé étrangère (FK) : Un attribut qui fait référence à la clé primaire d’une autre entité. Cela établit la relation entre les tables. Il garantit l’intégrité référentielle, en s’assurant qu’un enregistrement dans une table ne peut pas référencer un enregistrement inexistant dans une autre.
Classification des attributs
Les attributs varient selon la manière dont ils sont stockés et dérivés. Comprendre ces distinctions aide à optimiser le stockage et les performances des requêtes.
| Type | Description | Exemple |
|---|---|---|
| Simple | Ne peut pas être divisé davantage. Il est atomique. | Numéro de téléphone |
| Composé | Peut être divisé en parties sous-jacentes. | Adresse (Rue, Ville, Code postal) |
| Multivalué | Peut contenir plusieurs valeurs pour une instance unique d’une entité. | Adresses e-mail |
| Dérivé | Calculé à partir d’autres attributs. | Âge (dérivé de la date de naissance) |
Meilleures pratiques pour les attributs
Lors de la définition des attributs, gardez à l’esprit les directives suivantes pour garantir la qualité des données :
- Utilisez des noms descriptifs : Évitez les noms génériques comme
col1oudonnées. Utilisez des noms qui expliquent le contenu, tels quecourriel_clientoudate_commande. - Définir les types de données : Soyez précis. Utilisez des entiers pour les comptages, des dates pour les données liées au temps, et des chaînes de caractères pour le texte. Cela évite les erreurs lors de l’entrée et de la récupération des données.
- Minimiser les valeurs nulles : Là où c’est possible, appliquez des contraintes afin que les attributs ne restent pas vides. Les valeurs nulles peuvent compliquer les requêtes et entraîner des résultats inattendus.
- Normaliser les données : Assurez-vous que les attributs dépendent uniquement de la clé primaire. Évitez de stocker des données qui pourraient être déduites ou déplacées vers une autre entité.
Relations : Connecter les points 🔗
Les entités existent rarement en isolation. Les relations définissent comment les entités interagissent entre elles. Elles déterminent comment les données sont liées, comment les requêtes sont jointes, et comment l’intégrité est maintenue à travers la base de données. Une structure de relations bien conçue empêche la redondance des données et assure que les mises à jour sont correctement propagées.
Cardinalité
La cardinalité définit la relation numérique entre les entités. Elle répond à la question : « Combien d’instances de l’entité A sont liées à combien d’instances de l’entité B ? »
- Un à un (1:1) : Une instance de l’entité A est liée à exactement une instance de l’entité B. Cela est rare, mais se produit dans des scénarios comme un utilisateur ayant un seul profil.
- Un à plusieurs (1:N) : Une instance de l’entité A est liée à plusieurs instances de l’entité B. Par exemple, une Département possède plusieurs Employés.
- Plusieurs à plusieurs (M:N) : Plusieurs instances de l’entité A sont liées à plusieurs instances de l’entité B. Par exemple, un Étudiant peut s’inscrire à plusieurs Cours, et un Cours peut avoir plusieurs Étudiants.
Contraintes de participation
La cardinalité vous indique la quantité, mais les contraintes de participation vous indiquent si la relation est obligatoire.
- Participation totale : Chaque instance d’une entité doit participer à la relation. Par exemple, chaque Commande doit avoir un Client.
- Participation partielle : Une instance peut ou non participer à la relation. Par exemple, un Client peut ou non avoir une Commande à un moment donné.
Stratégies d’implémentation
Des cardinalités différentes exigent des stratégies d’implémentation différentes au sein du modèle de données.
| Type de relation | Méthode d’implémentation | Scénario d’exemple |
|---|---|---|
| 1:1 | Fusionner les tables ou ajouter une clé étrangère d’un côté. | Profil utilisateur lié au compte utilisateur. |
| 1:N | Ajouter une clé étrangère dans la table du côté « plusieurs ». | La table Employé possède un Dept_ID. |
| M:N | Créez une table de jonction avec deux clés étrangères. | Table d’inscription liant les étudiants et les cours. |
Normalisation : structuration pour la stabilité 📐
Alors que les entités, les attributs et les relations forment la structure, la normalisation organise cette structure afin de réduire la redondance et d’améliorer l’intégrité. La normalisation est une série d’étapes conçues pour garantir que les dépendances des données ont un sens.
Première forme normale (1NF)
En 1NF, chaque colonne doit contenir des valeurs atomiques. Vous ne pouvez pas stocker une liste de valeurs dans une seule cellule. Chaque ligne doit être unique, généralement assurée par une clé primaire. Cela élimine les groupes répétés.
Deuxième forme normale (2NF)
Une fois la 1NF atteinte, la 2NF garantit que tous les attributs non clés dépendent entièrement de la clé primaire. Si vous avez une clé composite, chaque attribut doit dépendre de toute la clé, et non seulement d’une partie.
Troisième forme normale (3NF)
La 3NF élimine les dépendances transitives. Les attributs non clés ne doivent pas dépendre d’autres attributs non clés. Par exemple, si Ville dépend de Code postal, et Code postal dépend de ID client, alors Ville dépend de ID client de manière transitive. Pour corriger cela, déplacez Ville vers une entité distincte ou assurez-vous qu’elle est directement liée à la clé.
Péchés courants dans la conception ⚠️
Même les développeurs expérimentés commettent des erreurs lors de la conception de modèles de données. Être conscient des pièges courants peut faire gagner énormément de temps pendant la phase de développement.
- Sur-normalisation :Diviser les données en trop nombreuses petites entités peut rendre les requêtes complexes et lentes. Parfois, une dénormalisation est acceptable pour les charges de travail intensives en lecture.
- Sous-normalisation : Le stockage des mêmes données à plusieurs endroits entraîne une incohérence. Si une adresse client change, vous devez la mettre à jour dans chaque enregistrement. Cela augmente le risque d’erreurs.
- Ignorer les types de données : Utiliser des chaînes de caractères pour les nombres ou les dates entraîne des problèmes de tri et des erreurs de validation. Assurez-vous toujours que le type d’attribut correspond aux données réelles.
- Valeurs codées en dur : Évitez de stocker les codes d’état sous forme de chaînes si ceux-ci ont des significations spécifiques. Utilisez des tables de référence pour des valeurs telles que « Statut » ou « Pays » afin de maintenir la cohérence.
- Index manquants : Les clés étrangères et les attributs fréquemment interrogés doivent être indexés pour améliorer les vitesses de recherche. Sans index, les opérations de jointure peuvent devenir des goulets d’étranglement.
Considérations avancées pour la scalabilité 🚀
À mesure que les applications grandissent, le modèle de données doit évoluer. Les décisions de conception initiales influencent la facilité avec laquelle le système peut être mis à l’échelle. Voici des éléments à considérer pour une stabilité à long terme.
Gestion des données historiques
Les règles métier évoluent au fil du temps. Des attributs qui étaient autrefois obligatoires peuvent devenir facultatifs. Les relations peuvent évoluer. Au lieu de modifier constamment le schéma, envisagez d’ajouter des colonnes pour l’historique ou d’utiliser des tables temporelles afin de suivre les modifications au fil du temps. Cela vous permet d’auditer les modifications sans altérer la fonctionnalité actuelle.
Sécurité et contrôle d’accès
Les entités contiennent souvent des informations sensibles. Concevez vos relations pour soutenir le contrôle d’accès. Par exemple, séparer Utilisateur des données de Journaux peut aider à gérer les autorisations. Assurez-vous que les clés étrangères ne mettent pas en danger les données sensibles aux utilisateurs non autorisés.
Performance des requêtes
La manière dont vous structurez les relations affecte directement les performances des requêtes. Les relations profondément imbriquées nécessitent plusieurs jointures, ce qui peut ralentir la récupération des données. Analysez vos requêtes les plus fréquentes et structurez vos entités pour minimiser le nombre de jointures nécessaires. Parfois, dénormaliser des attributs spécifiques dans un magasin optimisé pour la lecture est le choix approprié.
Conclusion 🏁
Maîtriser les concepts fondamentaux des entités, des attributs et des relations est un parcours qui s’étend tout au long de votre carrière. Ces éléments ne sont pas seulement des constructions théoriques ; ce sont des outils pratiques que vous utilisez pour construire des systèmes durables. En vous concentrant sur la clarté, l’intégrité et l’efficacité, vous créez des modèles de données qui soutiendront vos applications pendant des années.
Commencez par les bases. Définissez clairement vos entités. Affectez des attributs qui les décrivent précisément. Établissez des relations qui reflètent les interactions du monde réel. Au fur et à mesure que vous affinez ces conceptions, vous constaterez que la logique de votre application devient plus claire et plus robuste. Souvenez-vous qu’un bon design est celui qui est facile à comprendre et facile à modifier. Gardez ces principes à l’esprit tout au long de votre travail de développement.
Investir du temps dans une conception correcte des modèles ERD rapporte des dividendes sous forme de bogues réduits, de cycles de développement plus rapides et d’une base de code plus facile à maintenir. Que vous construisiez une petite utilitaire ou un système d’entreprise à grande échelle, les règles des entités, des attributs et des relations restent les mêmes. Restez fidèle aux fondamentaux, et votre architecture des données résistera à l’épreuve du temps.