











Construire un système de base de données revient à construire la fondation d’un gratte-ciel. Si le plan est défectueux, la structure finira par céder sous la pression. Un diagramme d’entités et de relations (ERD) est ce plan. Il définit comment les données sont connectées, circulent et persistent dans votre application. À mesure que votre base d’utilisateurs grandit et que le volume de données explose, une conception statique devient souvent un goulot d’étranglement. Pour assurer la pérennité, vous devez adopter dès le départ des principes de conception d’ERD évolutifs. Ce guide explore les stratégies techniques nécessaires pour construire des systèmes durables.
Comprendre le cœur de la modélisation des données 🧱
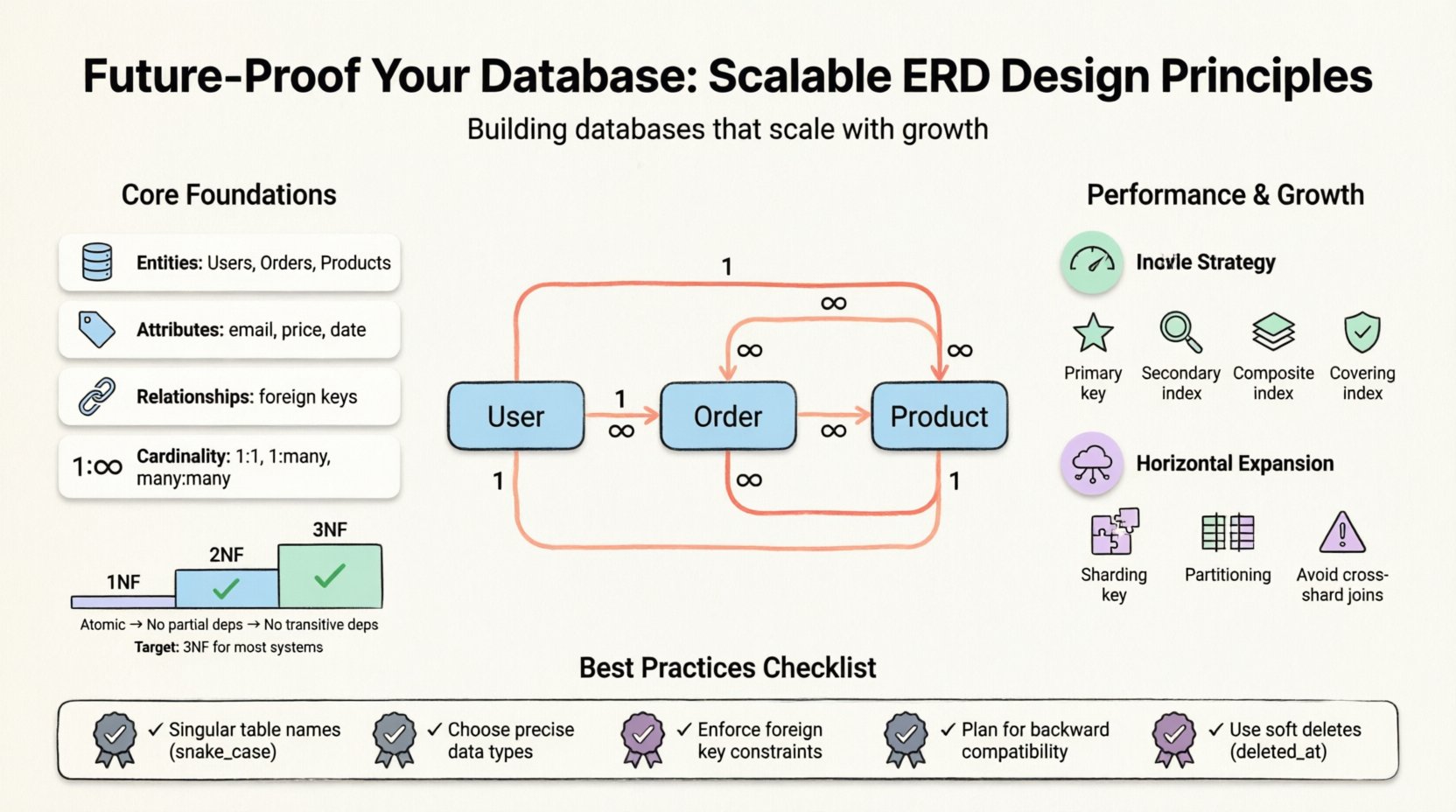
Avant de plonger dans des tactiques spécifiques, il est essentiel de comprendre ce qu’un ERD représente. Il visualise la structure logique d’une base de données. Il cartographie les entités (tables), les attributs (colonnes) et les relations (clés). Un modèle bien conçu équilibre l’intégrité des données et les performances. Toutefois, « les meilleures pratiques » varient selon la charge de travail. Une application fortement orientée lecture nécessite une optimisation différente d’un système transactionnel fortement orienté écriture.
Les composants clés incluent :
- Entités : Les objets principaux, tels que les Utilisateurs, les Commandes ou les Produits.
- Attributs : Les propriétés définissant une entité, comme les adresses e-mail ou les prix.
- Relations : La manière dont les entités interagissent, souvent définie par des clés étrangères.
- Cardinalité : La relation numérique entre les entités (un-à-un, un-à-plusieurs, plusieurs-à-plusieurs).
Normalisation : L’équilibre entre redondance et vitesse ⚖️
La normalisation est le processus d’organisation des données afin de réduire la redondance et d’améliorer l’intégrité. Bien qu’elle soit souvent traitée comme une règle stricte, elle représente un compromis. Une haute normalisation minimise les anomalies, mais peut augmenter la complexité des requêtes par des jointures. Une faible normalisation (dénormalisation) accélère les lectures, mais expose à des risques d’incohérence des données.
Niveaux de normalisation
Comprendre les formes standards vous aide à décider où s’arrêter. Chaque forme traite des anomalies de données spécifiques.
- Première forme normale (1NF) : Assure l’atomicité. Chaque colonne doit contenir des valeurs indivisibles. Aucun groupe répétitif ou tableau dans une seule cellule.
- Deuxième forme normale (2NF) : S’appuie sur la 1NF. Tous les attributs non clés doivent dépendre de la clé primaire entière, et non seulement d’une partie de celle-ci. Cela élimine les dépendances partielles.
- Troisième forme normale (3NF) : S’appuie sur la 2NF. Les attributs non clés ne doivent pas dépendre d’autres attributs non clés. Cela élimine les dépendances transitives.
- Forme normale de Boyce-Codd (BCNF) : Une version plus stricte de la 3NF. Elle traite les cas où les déterminants ne sont pas des clés candidates.
Pour la plupart des systèmes évolutifs, atteindre la 3NF est l’objectif standard. Aller plus loin donne souvent des retours décroissants tout en augmentant la charge de maintenance. Toutefois, pour les systèmes fortement orientés analyse, un retour contrôlé à la dénormalisation est courant.
Tableau des compromis de normalisation
| Niveau de normalisation | Avantage principal | Inconvénient principal |
|---|---|---|
| 1FN | Stockage de données atomiques | Aucun |
| 2FN | Élimine les dépendances partielles | Plus de jointures nécessaires |
| 3FN | Élimine les dépendances transitives | Complexité accrue des jointures |
| Non normalisé | Requêtes de lecture plus rapides | Redondance des données et anomalies de mise à jour |
Conception de schéma pour la croissance et la flexibilité 📈
Concevoir pour le présent est insuffisant. Vous devez anticiper l’évolution future du schéma. Les structures rigides se brisent lorsque la logique métier évolue. Une conception flexible permet une expansion sans nécessiter une migration complète du système.
1. Conventions et normes de nommage
La cohérence est essentielle pour la maintenabilité. Un schéma de nommage chaotique entraîne de la confusion et des erreurs. Établissez une norme dès le départ et appliquez-la rigoureusement dans toute l’équipe.
- Utilisez des noms au singulier :Les tables doivent représenter une entité unique (par exemple,
utilisateur, pasutilisateurs). - Délimiteurs cohérents :Utilisez snake_case pour les noms de tables et de colonnes afin d’assurer la compatibilité sur différents systèmes d’exploitation et outils.
- Préfixes pour la spécificité :Utilisez des préfixes comme
fk_pour les clés étrangères ouidx_pour les index afin de rendre leur objectif clair. - Évitez les mots réservés : N’utilisez jamais des mots-clés comme
order,group, ouselectcomme noms de colonnes.
2. Types de données et précision
Le choix du bon type de données affecte l’espace de stockage et la vitesse des requêtes. Les types trop génériques gaspillent de l’espace et ralentissent le traitement.
- Entiers : Utilisez
TINYINTpour les indicateurs (0-1) ou les petits comptages. UtilisezBIGINTuniquement lorsque vous prévoyez une échelle massive. - Chaînes de caractères : Évitez
TEXTpour les valeurs courtes. UtilisezVARCHARavec une longueur spécifique pour économiser de l’espace et permettre l’indexation. - Dates : Utilisez
TIMESTAMPpour des moments précis etDATEpour les dates calendaires uniquement. Stockez toujours en UTC pour éviter toute confusion liée aux fuseaux horaires. - Décimaux : Pour les données financières, utilisez des décimaux à point fixe plutôt que des nombres à virgule flottante pour éviter les erreurs d’arrondi.
Relations et gestion de la cardinalité 🔗
La manière dont les entités sont liées détermine l’intégrité de vos données. Une gestion inadéquate des relations entraîne des enregistrements orphelins et des pertes de données.
1. Contraintes de clés étrangères
Les clés étrangères garantissent l’intégrité référentielle. Elles assurent qu’un enregistrement dans une table ne puisse pas référencer un enregistrement inexistant dans une autre. Bien que certains développeurs les désactivent pour des raisons de performance, les moteurs de bases de données modernes les gèrent efficacement. Se fier aux vérifications au niveau de l’application est sujet aux erreurs.
2. Gestion des relations plusieurs-à-plusieurs
Une relation plusieurs-à-plusieurs (par exemple, Étudiants et Cours) ne peut pas être représentée directement dans deux tables. Elle nécessite une table de jonction (entité associative).
- Créez une nouvelle table contenant les clés primaires des deux tables associées.
- Ajoutez une clé primaire composée des deux clés étrangères.
- Utilisez cette table pour stocker des attributs supplémentaires spécifiques à la relation, tels que les dates d’inscription.
3. Relations optionnelles vs. obligatoires
Définissez clairement si une relation est obligatoire. Une NULLvaleur dans une colonne de clé étrangère indique une relation optionnelle. Cette décision influence la logique de validation au niveau de la couche application.
Stratégies d’indexation pour des performances de lecture 🏎️
Les index sont le mécanisme principal pour accélérer la récupération des données. Cependant, ils ne sont pas gratuits. Chaque index consomme de l’espace disque et ralentit les opérations d’écriture (insertions, mises à jour, suppressions).
1. Index primaires
Chaque table nécessite une clé primaire. Elle est souvent regroupée, ce qui signifie que les données physiques sont stockées dans l’ordre de la clé. Choisissez une clé stable et jamais mise à jour. Les clés de substitution (entiers auto-incrémentés) sont souvent préférables aux clés naturelles (comme les adresses e-mail) en termes de performance.
2. Index secondaires
Utilisez les index secondaires pour optimiser les requêtes qui filtrent ou trient sur des colonnes non primaires. Les scénarios courants incluent :
- Recherche par adresse e-mail.
- Filtrage par statut ou catégorie.
- Tri des résultats par date.
3. Index composés
Lorsqu’on interroge par plusieurs colonnes, un index composé peut être plus efficace qu’un ensemble d’index simples sur une seule colonne. L’ordre des colonnes dans l’index est important. Placez la colonne la plus sélective en premier.
4. Index couvrants
Un index couvrant inclut toutes les colonnes nécessaires pour satisfaire une requête. Cela permet à la base de données de récupérer les données directement depuis l’index sans accéder à la table principale, réduisant considérablement les opérations d’E/S.
Conception pour le dimensionnement horizontal 🌐
Le dimensionnement vertical (ajouter plus de puissance à un serveur unique) a des limites. À un moment donné, vous devez répartir les données sur plusieurs nœuds. La conception du schéma ERD doit tenir compte de cette réalité.
1. Clés de fractionnement
Le fractionnement consiste à diviser les données sur plusieurs bases de données. Le choix de la clé de fractionnement est crucial. Elle doit être utilisée fréquemment dans les requêtes afin de garantir la localité des données. Si vous fractionnez par “user_id, vous pouvez facilement interroger toutes les données de cet utilisateur sur un seul nœud.
- Clés de hachage efficaces : Haute cardinalité, fréquemment utilisée dans les requêtes.
- Clés de hachage peu efficaces : Faible cardinalité (par exemple,
code_pays) ou peu utilisée.
2. Éviter les jointures entre shards
Les jointures entre différents shards sont coûteuses et complexes. Concevez votre schéma pour minimiser leur nécessité. Si vous avez besoin de données provenant de deux entités qui pourraient se trouver sur des shards différents, envisagez de dénormaliser les données. Stockez les données de clés étrangères nécessaires directement dans la table afin d’éviter la jointure.
3. Partitionnement
Le partitionnement divise une grande table en morceaux plus petits et gérables. Cela peut être fait par plage (dates), liste (catégories) ou hachage. Cela améliore la maintenance et les performances des requêtes sans modifier de manière significative la logique de l’application.
Évolution et migration du schéma 🔄
Les exigences évoluent. De nouvelles fonctionnalités exigent de nouvelles colonnes. Les anciennes fonctionnalités sont dépréciées. Un ERD robuste permet d’adapter les changements sans briser la fonctionnalité existante.
1. Compatibilité descendante
Lors de l’ajout de nouvelles fonctionnalités, assurez-vous que les anciens clients peuvent toujours fonctionner. Ajoutez d’abord les nouvelles colonnes comme nulles. Remplissez-les progressivement. Ne supprimez pas immédiatement les colonnes ; marquez-les comme obsolètes et conservez-les pendant une période de migration.
2. Versionnement des modèles de données
Suivez les versions du schéma. Cela vous permet d’annuler les modifications si une migration provoque des échecs critiques. Utilisez des scripts de migration idempotents, c’est-à-dire qu’ils peuvent être exécutés plusieurs fois sans provoquer d’erreurs.
3. Gestion de la migration des données
Le déplacement de grandes quantités de données nécessite une planification soigneuse. Les verrous importants peuvent bloquer le trafic de production. Effectuez les migrations pendant les périodes de faible trafic ou utilisez des stratégies de déploiement bleu-vert lorsque cela est possible.
Péchés courants à éviter ⚠️
Même les architectes expérimentés commettent des erreurs. Être conscient des erreurs courantes vous aide à les éviter.
- Surconception : Concevoir pour une échelle que vous n’avez pas encore. Si vous commencez, gardez-le simple. La complexité ajoute des coûts et des risques.
- Ignorer les suppressions douces : Ne supprimez jamais immédiatement de manière définitive les enregistrements sensibles. Utilisez un
deleted_athorodatage à la place. Cela préserve les traces d’audit et permet la récupération. - Conflits de noms : Utiliser le même nom pour une table et une colonne crée une ambiguïté. Respectez la règle du nom singulier pour les tables.
- Contraintes manquantes :Se fier uniquement à la logique d’application pour appliquer les règles métier entraîne une corruption des données. Appliquez les contraintes au niveau de la base de données.
- Ignorer la sécurité :La conception doit inclure des champs pour le contrôle d’accès. Assurez-vous que l’accès basé sur les rôles est pris en charge dès la phase de conception du schéma.
Considérations finales pour la durabilité 🏁
Créer une base de données évolutif est un processus continu. Il nécessite un suivi, une analyse et des ajustements. Aucun design n’est parfait au lancement. L’objectif est de créer une base facile à modifier.
Audit régulier de vos requêtes. Identifiez les opérations lentes et optimisez le schéma sous-jacent. Utilisez des outils de profilage pour comprendre comment vos données sont accessibles. Ce cycle de retour d’information garantit que votre architecture reste efficace à mesure que vos données croissent.
Souvenez-vous que la technologie évolue. De nouveaux moteurs de stockage et de nouveaux langages de requête apparaissent. Un schéma souple s’adapte mieux à ces changements qu’un schéma rigide. Concentrez-vous sur les relations fondamentales et l’intégrité des données. Ces éléments restent constants même lorsque les outils évoluent.
En suivant ces principes, vous construisez des systèmes résilients. Ils gèrent la croissance avec élégance et maintiennent leurs performances sous charge. C’est l’essence de la future-proofing de votre infrastructure de base de données.