


Concevoir des schémas de base de données robustes exige plus que la simple liste des tables et des colonnes. Il demande une compréhension approfondie de la manière dont les entités se rapportent les unes aux autres. Parmi les concepts les plus puissants mais aussi les plus complexes des diagrammes Entité-Relation (ERD), figure l’héritage. Ce mécanisme nous permet de modéliser des hiérarchies du monde réel où les objets partagent des caractéristiques communes tout en possédant également des attributs uniques. Dans le contexte de la conception de bases de données, cela se traduit par des supertypes et des sous-types. 🧩
Lorsque nous modélisons l’héritage, nous capturons essentiellement la relation « est-un ». Par exemple, un Véhicule est un type de Produit, et un Voiture est un type de Véhicule. Cette hiérarchie nous permet de réutiliser des attributs au niveau supérieur tout en définissant des comportements ou des données spécifiques au niveau inférieur. Comprendre comment implémenter cela dans une base de données relationnelle est crucial pour l’intégrité des données et les performances des requêtes. 🗄️
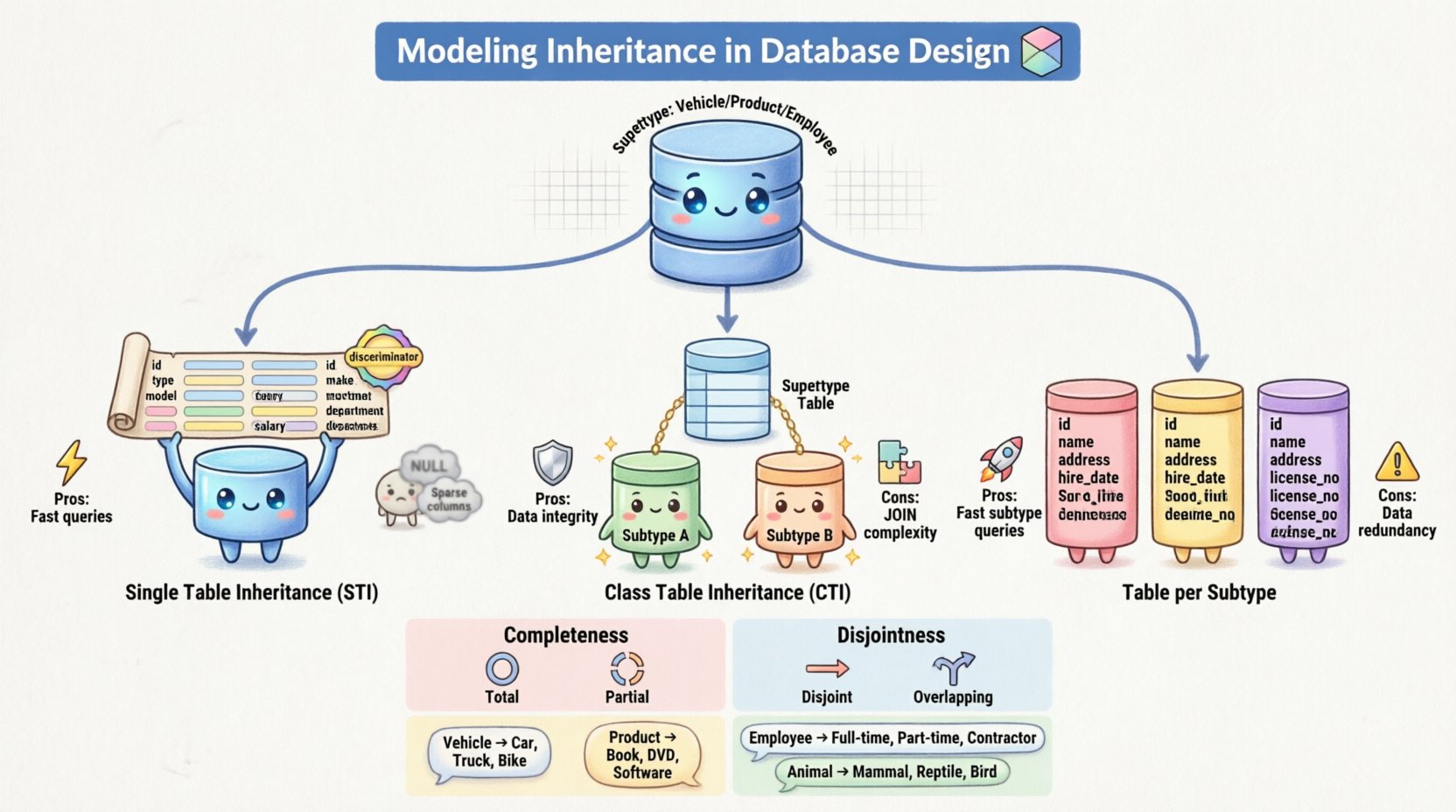
🔑 Concepts fondamentaux : Supertypes et sous-types
Avant de plonger dans l’implémentation, nous devons définir clairement la terminologie. L’héritage dans la modélisation des bases de données ne concerne pas uniquement le code ; il s’agit de la représentation structurelle des données.
- Supertype : Il s’agit de l’entité parente. Il contient les attributs communs à toutes les entités associées. Il représente la catégorie générale. Par exemple, Employé pourrait être un supertype.
- Sous-type : Ce sont les entités enfants. Elles héritent des attributs du supertype, mais peuvent aussi posséder leurs propres attributs uniques. Des exemples incluent Gérant ou Développeur.
- Catégorie d’entité : Le supertype est parfois appelé catégorie d’entité, regroupant les sous-types ensemble.
- Discriminateur : Un attribut spécifique au sein du supertype qui identifie à quel sous-type appartient une instance. Cela est souvent utilisé dans les implémentations physiques.
La relation entre un supertype et un sous-type est stricte. Chaque instance d’un sous-type doit également être une instance du supertype. Toutefois, toutes les instances du supertype n’ont pas besoin d’être des instances d’un sous-type spécifique. Cette distinction est essentielle pour la précision de la modélisation des données. ✅
📊 Stratégies d’implémentation
Traduire le modèle logique ERD en un schéma de base de données physique implique des stratégies de mappage spécifiques. Il existe trois approches principales utilisées pour représenter l’héritage dans les systèmes relationnels. Chacune présente des compromis en matière de stockage, de vitesse de récupération et d’intégrité des données. 🛠️
1. Héritage de table unique (STI)
Dans cette approche, tous les attributs du supertype et de tous les sous-types sont combinés dans une seule table. La table contient des colonnes pour chaque attribut défini dans toute la hiérarchie. Pour distinguer les lignes appartenant à différents sous-types, une colonne discriminante est ajoutée.
- Avantages : Extrêmement efficace pour la lecture des données. Une requête simple
SELECTrécupère toutes les informations sans jointures complexes. - Inconvénients : La table peut devenir très large avec de nombreuses
NULLvaleurs pour les attributs qui ne s’appliquent pas aux sous-types spécifiques. Cela peut également rendre les mises à jour difficiles si les contraintes propres aux sous-types changent.
2. Héritage de table de classe (CTI)
Ici, le supertype et chaque sous-type sont mappés à leurs propres tables distinctes. La table du supertype contient les attributs communs et une clé primaire. Chaque table de sous-type contient les attributs uniques et une clé étrangère qui renvoie à la clé primaire du supertype.
- Avantages : Très normalisé. Aucune
NULLvaleurs pour les attributs non applicables. Applique strictement l’intégrité référentielle. - Inconvénients : Récupérer les données nécessite plusieurs opérations de type
JOINopérations, ce qui peut affecter les performances sur de grands jeux de données. Cela complique également les opérations de typeINSERTpuisque les données doivent être écrites dans plusieurs tables.
3. Table par sous-type (Héritage de table concrète)
Cette stratégie crée une table pour chaque sous-type, y compris le supertype. Toutefois, chaque table de sous-type contient une copie des attributs du supertype. Il n’y a pas de lien direct vers une table centrale du supertype.
- Avantages : Interroger un sous-type spécifique est très rapide car toutes les données sont regroupées en un seul endroit. Cela évite le problème des
NULLproblème du STI. - Inconvénients : Redondance des données. Si un attribut commun change dans le supertype, il doit être mis à jour dans chaque table de sous-type. Cela augmente le risque d’incohérence des données.
⚖️ Contraintes sur l’héritage
Toutes les relations d’héritage ne sont pas identiques. Nous devons définir des contraintes qui régissent la manière dont les instances se rapportent à leurs types. Ces contraintes assurent que les données restent logiques et cohérentes. 📝
Contrainte de complétude
Cette contrainte détermine si chaque instance de supertype doit appartenir à un sous-type.
- Complète : Chaque instance du supertype doit être membre d’au moins un sous-type. Il n’existe pas d’instances « génériques ». Par exemple, chaque Animal doit être soit un Mammifère soit un Oiseau.
- Partielle : Une instance du supertype n’appartient pas nécessairement à un sous-type. Elle peut exister comme une entité générale. Cela est courant lorsque la hiérarchie est utilisée pour la catégorisation plutôt que pour une classification stricte.
Contrainte de disjonction
Cette contrainte détermine si une instance peut appartenir à plusieurs sous-types simultanément.
- Disjoint : Une instance ne peut appartenir qu’à un seul sous-type. Elle ne peut pas être à la fois un Manager et un Développeur en même temps dans ce modèle.
- Chevauchement : Une instance peut appartenir à plus d’un sous-type. Cela permet des rôles complexes où un Employé peut occuper plusieurs postes ou classifications.
Combiner ces contraintes donne lieu à quatre scénarios de modélisation distincts. Comprendre lequel correspond à votre logique métier est essentiel avant de créer le schéma. 🧠
| Type de contrainte | Définition | Scénario d’exemple |
|---|---|---|
| Disjoint + Complet | Un seul sous-type, pas d’instances génériques | Statut de la commande : En attente, Expédiée, Livrée |
| Disjoint + Partiel | Un seul sous-type, sous-type facultatif | Client : VIP ou Régulier (certains ne sont ni l’un ni l’autre) |
| Chevauchement + Complet | Plusieurs sous-types autorisés, doit appartenir à un seul | Rôle utilisateur : Administrateur et Éditeur (doit en avoir au moins un) |
| Chevauchement + Partiel | Plusieurs sous-types autorisés, facultatifs | Produit : Vendable, Promotionnel (peut être les deux ou aucun des deux) |
🔍 Requêtes et récupération des données
Le choix de la stratégie de mappage a un impact significatif sur la manière dont vous écrivez les requêtes. Dans un environnement normalisé, vous devez souvent parcourir la hiérarchie pour obtenir une vue complète d’une entité. 🔎
- Récupération des données du sous-type : Si vous devez accéder à des attributs spécifiques à un sous-type, vous devez joindre la table du sous-type. C’est la norme dans l’héritage par table de classe.
- Récupération des données du super-type : Si vous avez besoin d’attributs communs, vous pouvez interroger directement la table du super-type.
- Requêtes polymorphes : Lorsque vous interrogez toutes les instances indépendamment du sous-type, l’approche par une seule table est la plus rapide. Toutefois, si vous utilisez plusieurs tables, vous devez utiliser
UNIONdes opérations ou des jointures complexes.
Pensez aux implications de performance. Une requête qui joint cinq tables pour récupérer un seul enregistrement peut être plus lente qu’une requête sur une seule table non normalisée. Toutefois, la table non normalisée peut violer les règles de normalisation, entraînant des anomalies de mise à jour. Équilibrer ces facteurs est une étape clé dans la conception du schéma. ⚖️
🛠️ Maintenance et évolution
Les schémas ne sont pas statiques. Les exigences métier évoluent, et le schéma de base de données doit évoluer en conséquence. Le modèle d’héritage offre de la flexibilité, mais introduit également une complexité lors de la maintenance. 🔄
Ajout de nouveaux sous-types
L’ajout d’un nouveau sous-type est généralement simple. Vous créez une nouvelle table (dans CTI) ou une nouvelle valeur dans la colonne discriminante (dans STI). Toutefois, vous devez vous assurer que les requêtes existantes et la logique d’application prennent en compte le nouveau type. L’oubli de mettre à jour le code peut entraîner des erreurs d’exécution.
Modification des attributs du super-type
Si vous ajoutez un attribut au super-type, il doit être reflété dans chaque table de sous-type si vous utilisez CTI ou Table par sous-type. Dans STI, vous l’ajoutez une seule fois dans la table unique. Cela rend STI plus facile à maintenir pour les modifications courantes, mais plus difficile pour les modifications spécifiques.
Migration des données
Refactoriser un modèle d’héritage est une entreprise importante. Passer d’une seule table à une structure normalisée nécessite le déplacement des données à travers plusieurs tables. Ce processus doit être soigneusement géré pour éviter la perte ou la corruption des données. 🚧
📈 Normalisation et héritage
Le modèle d’héritage interagit étroitement avec la normalisation des bases de données. L’objectif de la normalisation est de réduire la redondance et d’améliorer l’intégrité des données. L’héritage peut parfois entrer en conflit avec ces objectifs si ce n’est pas correctement géré.
- Première forme normale (1NF) : Les modèles d’héritage satisfont généralement la 1NF, car les attributs sont atomiques.
- Deuxième forme normale (2NF) : Dans le STI, une table pourrait contenir des attributs qui ne dépendent pas entièrement de la clé primaire si le discriminateur n’en fait pas partie. Cela exige une conception soigneuse de la clé.
- Troisième forme normale (3NF) : Dans le CTI, la séparation des attributs en tables de sous-types aide souvent à atteindre la 3NF en éliminant les dépendances transitives.
Lors de la conception des super-types, assurez-vous que les attributs communs sont véritablement communs. Si un attribut est utilisé uniquement par un seul sous-type, il devrait probablement ne pas figurer dans le super-type. Cela empêche le super-type de devenir une « table-dieu » difficile à interroger. 👁️
🎯 Meilleures pratiques pour la conception du schéma
Pour garantir que votre modèle d’héritage reste maintenable et performant, suivez ces recommandations.
- Limitez la profondeur : Évitez les hiérarchies profondes. Trois niveaux d’héritage sont généralement le maximum recommandé. Au-delà, la complexité des requêtes et de la maintenance dépasse les avantages.
- Utilisez des noms clairs : Les noms doivent refléter la hiérarchie. Véhicule, Voiture, Camion est clair. Entité1, Entité2 ne l’est pas.
- Prévoyez la croissance : Prévoyez les sous-types futurs. Si vous attendez de nombreux nouveaux sous-types, une seule table pourrait devenir difficile à gérer. Si vous en attendez peu, le CTI pourrait être préférable.
- Documentez les contraintes : Documentez clairement les contraintes d’exclusivité et de complétude. Les développeurs futurs doivent savoir si une instance peut appartenir à plusieurs sous-types.
- Stratégie d’indexation : Si vous utilisez le CTI, indexez les colonnes clés étrangères dans les tables de sous-types pour accélérer les jointures. Si vous utilisez le STI, indexez la colonne discriminante pour le filtrage.
🧪 Scénarios du monde réel
Examinons comment cela s’applique aux défis réels de modélisation des données.
Scénario 1 : Ressources humaines
Dans un système RH, vous avez Personne comme supertype. Les sous-types incluent Employé, Contractuel, et Stagiaire. Chaque sous-type possède des données uniques : Employé possède un identifiant de paie, Contractuel possède un taux de facturation. Une Personnetable contient le nom et l’adresse. Cela correspond bien au modèle d’héritage de table de classe.
Scénario 2 : Gestion des stocks
Considérez un catalogue de produits. Produit est le supertype. Les sous-types sont Électroniques, Meubles, et Vêtements. Électronique a Période de garantie. Vêtements a Taille et Couleur. Si vous interrogez tous les produits avec une garantie, vous devez effectuer une jointure avec la table Électronique. Cela met en évidence le compromis de performance des requêtes. 🔍
Scénario 3 : Transactions financières
Dans un système bancaire, Compte est le supertype. Les sous-types sont Épargne, Chèques, et Prêt. Un Épargne compte a un taux d’intérêt. Un Prêt compte a une date d’échéance. Ce scénario bénéficie souvent d’une approche en table unique pour simplifier les calculs de soldes sur tous les types de comptes.
🚀 Considérations sur les performances
Les performances sont souvent le facteur déterminant lors du choix d’une stratégie de mappage. Les grands ensembles de données amplifient les différences entre les approches.
- Performance d’écriture : STI est le plus rapide pour les insertions car il s’agit d’une seule
INSERTinstruction. CTI nécessite plusieursINSÉRERinstructions, ce qui augmente la charge des transactions. - Performance de lecture : Si vous interrogez fréquemment des sous-types spécifiques, le CTI est plus rapide que le STI car vous ne lisez que les colonnes pertinentes. Si vous interrogez toutes les instances, le STI est plus rapide.
- Stockage : Le STI utilise plus d’espace de stockage en raison de
NULLle remplissage. Le CTI utilise plus d’espace de stockage en raison des clés primaires et étrangères en double, mais moins en raison de l’absence deNULLle remplissage.
Il est essentiel de profiler votre application. Les performances théoriques ne correspondent pas toujours aux modèles d’utilisation réels. Tester avec des volumes de données réalistes est la seule façon de confirmer votre choix. 📊
🛡️ Intégrité des données et validation
Maintenir l’intégrité des données dans un modèle d’héritage nécessite des règles de validation strictes. Vous devez vous assurer que les données insérées dans une table de sous-type respectent les contraintes du type supérieur.
- Contraintes de clé étrangère : Assurez-vous que les lignes de sous-type sont toujours liées à des lignes de type supérieur valides. Cela évite les données orphelines.
- Contraintes de vérification : Utilisez des contraintes de vérification pour imposer des règles métier. Par exemple, assurez-vous que le Taux d’intérêt dans un Compte d’épargne sous-type n’est jamais négatif.
- Déclencheurs : Dans certains scénarios complexes, des déclencheurs de base de données peuvent être nécessaires pour maintenir la cohérence entre les tables lors des mises à jour.
Les tests automatisés doivent couvrir les scénarios d’héritage. Vérifiez que la création d’une nouvelle instance de sous-type met correctement à jour le type supérieur. Vérifiez que la suppression d’une instance de type supérieur se propage correctement aux sous-types si c’est le comportement souhaité. 🧪
📝 Considérations finales
Modéliser l’héritage est un équilibre entre flexibilité et complexité. Il n’existe pas une seule « bonne » façon de le faire. Le meilleur choix dépend de vos modèles d’accès aux données spécifiques, de vos règles métier et de vos exigences de performance.
- Commencez par une compréhension claire du domaine. Cartographiez les entités avant de vous soucier des tables.
- Choisissez une stratégie de mappage qui correspond à vos requêtes les plus fréquentes.
- Documentez vos décisions. La maintenance future reposera sur cette documentation.
- Revoyez la structure périodiquement. Au fur et à mesure que l’entreprise évolue, le modèle pourrait avoir besoin d’être modifié.
En concevant soigneusement les supertypes et les sous-types, vous créez une base de données robuste, évolutif et facile à comprendre. Cette fondation soutient les applications qui en dépendent, garantissant une stabilité et une efficacité à long terme. 🏗️