











Merancang basis data bukan sekadar tentang menyimpan data; itu tentang menyusun informasi sedemikian rupa sehingga menjamin integritas, mengurangi redundansi, dan mengoptimalkan kinerja. Saat kita berbicara tentang struktur basis data yang efisien, dua pilar utama muncul: Diagram Hubungan Entitas (ERD) dan Normalisasi. Konsep-konsep ini bukan teknik yang terpisah, melainkan alat-alat yang saling melengkapi dan bekerja sama untuk menciptakan fondasi data yang kuat.
Panduan ini mengeksplorasi bagaimana menggabungkan kejelasan visual ERD dengan ketatnya struktur normalisasi. Kami akan membimbing Anda melalui proses mengubah model konseptual menjadi skema praktis yang mampu bertahan terhadap ujian waktu.
📐 Memahami Dasar: ERD dan Normalisasi
Sebelum terjun ke proses desain, sangat penting untuk memahami peran-peran khusus dari kedua metodologi ini.
📊 Apa itu Diagram Hubungan Entitas?
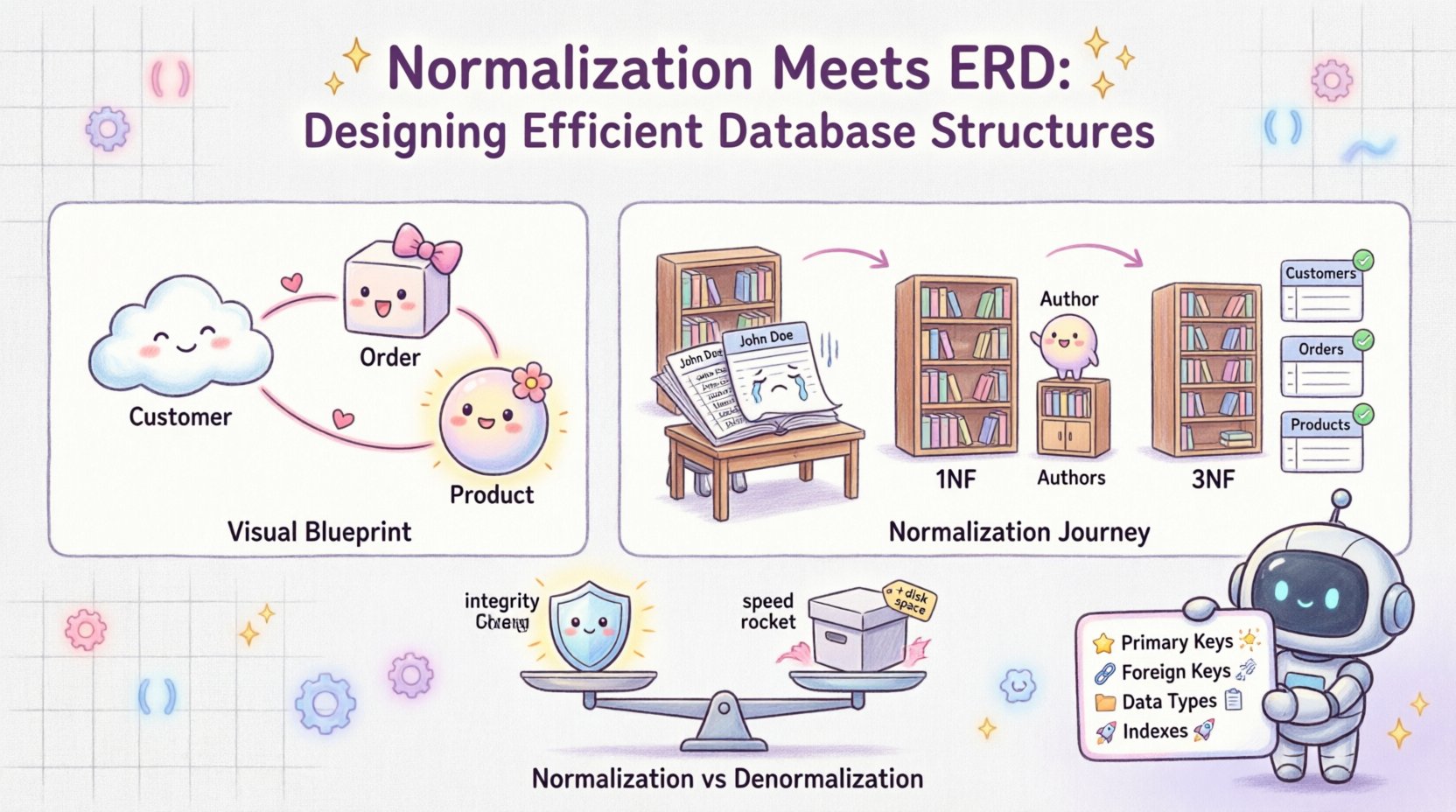
Diagram Hubungan Entitas berfungsi sebagai gambaran visual dari basis data. Ini memetakan entitas (tabel), atribut (kolom), dan hubungan (tautan) di antara mereka. Bayangkan sebagai gambar arsitektur untuk sebuah bangunan. Ini menjawab pertanyaan-pertanyaan seperti:
- Apa objek inti dalam sistem kita? (misalnya, Pelanggan, Pesanan)
- Bagaimana objek-objek ini berinteraksi? (misalnya, Seorang Pelanggan membuat banyak Pesanan)
- Data apa yang perlu kita simpan untuk setiap objek? (misalnya, Pelanggan membutuhkan Nama dan Email)
Tanpa ERD, desain basis data menjadi seperti tebakan. Ini memberikan gambaran tingkat tinggi yang dapat dipahami oleh para pemangku kepentingan, memastikan semua pihak setuju terhadap kebutuhan data sebelum satu baris kode pun ditulis.
🧼 Apa itu Normalisasi?
Normalisasi adalah proses mengorganisasi data dalam basis data untuk mengurangi redundansi dan meningkatkan integritas data. Ini melibatkan pembagian tabel besar menjadi struktur logis yang lebih kecil dan menentukan hubungan antar mereka. Tujuannya adalah memastikan bahwa setiap bagian data disimpan di satu tempat saja.
Mengapa hal ini penting?
- Integritas Data: Jika alamat pelanggan berubah, Anda memperbarui informasi tersebut di satu tempat, bukan sepuluh tempat.
- Efisiensi Penyimpanan: Data duplikat yang lebih sedikit berarti penggunaan ruang disk yang lebih sedikit.
- Pemeliharaan: Lebih mudah untuk memelihara dan memperbarui skema seiring waktu.
⚙️ Persilangan: Menggabungkan ERD dengan Normalisasi
Mendesain basis data sering kali dimulai dengan ERD, tetapi ERD mentah jarang siap untuk produksi. ERD sering mengandung redundansi yang diatasi oleh normalisasi. Alur kerja melibatkan pembuatan ERD konseptual, menganalisisnya untuk menemukan anomali, dan menerapkan aturan normalisasi untuk menyempurnakan skema.
Berikut adalah alur kerja umum:
- Desain Konseptual: Gambar ERD awal berdasarkan kebutuhan.
- Desain Logis: Sempurnakan ERD menjadi tabel dan kolom.
- Normalisasi: Terapkan bentuk normalisasi (1NF, 2NF, 3NF) untuk menghilangkan anomali.
- Desain Fisik: Optimalisasi untuk mesin basis data tertentu dan kebutuhan kinerja.
🔍 Langkah demi Langkah: Dari ERD ke Skema yang Dinormalisasi
Mari kita bahas sebuah skenario praktis untuk melihat bagaimana ini bekerja dalam praktik. Bayangkan kita sedang membangun sistem untuk mengelola perpustakaan.
1. Kondisi Tidak Dinormalisasi
Awalnya, Anda mungkin merancang satu tabel untuk menyimpan semua informasi tentang buku dan penulis. Ini dikenal sebagai tabel yang tidak dinormalisasi.
| IDBuku | Judul | NamaPenulis | TeleponPenulis | Genre |
|---|---|---|---|---|
| 101 | Novel Hebat | John Doe | 555-0101 | Fiksi |
| 102 | Buku Misteri | John Doe | 555-0101 | Misteri |
| 103 | Buku Lainnya | Jane Smith | 555-0102 | Fiksi |
Perhatikan masalah di sini?John Doenomor teleponnya diulang. Jika dia mengganti nomornya, Anda harus memperbarui beberapa baris. Ini adalah Anomali Pembaruan.
2. Bentuk Normal Pertama (1NF)
Aturan pertama normalisasi adalah memastikan atomisitas. Setiap kolom harus berisi hanya satu nilai, dan tidak boleh ada kelompok yang diulang.
- Aturan:Hilangkan kelompok yang diulang dan pastikan nilai-nilai bersifat atomik.
- Aplikasi: Dalam contoh perpustakaan kami, tabel awal mungkin sudah bersifat atomik, tetapi kita harus memastikan bahwa kita memiliki Kunci Utama. Mari kita asumsikan BookID adalah unik.
- Hasil:Kini kita memiliki tabel di mana setiap sel berisi satu bagian data.
3. Bentuk Normal Kedua (2NF)
Setelah sebuah tabel berada dalam 1NF, kita memeriksa ketergantungan parsial. Sebuah tabel berada dalam 2NF jika berada dalam 1NF dan setiap atribut non-kunci sepenuhnya tergantung pada kunci utama.
- Skenario: Jika kita memiliki kunci komposit (misalnya, BookID + AuthorID), kita akan memeriksa apakah AuthorPhone tergantung pada seluruh kunci atau hanya bagian penulis.
- Tindakan: Dalam contoh kita, AuthorPhone tergantung pada AuthorName, bukan pada BookID. Ini menunjukkan bahwa kita sebaiknya memisahkan data penulis dari data buku.
4. Bentuk Normal Ketiga (3NF)
Di sinilah keajaiban sebenarnya terjadi. 3NF menghilangkan ketergantungan transitif. Atribut non-kunci seharusnya tidak tergantung pada atribut non-kunci lainnya.
- Aturan:Tidak ada atribut yang boleh tergantung pada atribut non-kunci lainnya.
- Aplikasi: AuthorPhone tergantung pada AuthorName. Karena AuthorName bukan kunci utama dari tabel buku, maka kita pindahkan informasi penulis ke dalam tabel terpisah Authors tabel.
- Hasil: Sekarang, memperbarui nomor telepon seorang penulis hanya memerlukan perubahan satu catatan di dalam Penulis tabel, bukan beberapa catatan di dalam Buku tabel.
📋 Normalisasi vs. Denormalisasi: Menemukan Keseimbangan
Meskipun normalisasi sangat penting untuk menjaga integritas, tidak selalu menjadi solusi untuk kinerja. Terkadang, membaca data lebih sering daripada menulisnya. Dalam kasus-kasus ini, denormalisasi bisa menjadi bermanfaat.
📉 Kapan Saatnya Denormalisasi
Denormalisasi melibatkan penambahan data yang berulang ke dalam basis data yang telah dinormalisasi untuk meningkatkan kinerja baca. Ini merupakan pertukaran antara penyimpanan dan kecepatan.
- Volume Baca Tinggi: Jika aplikasi Anda mengakses data ribuan kali per detik, menggabungkan tabel dapat melambatkan kinerja.
- Dasbor Pelaporan: Data yang digabungkan mungkin telah dihitung sebelumnya dan disimpan untuk menghindari query yang rumit.
- Strategi Penyimpanan Sementara (Caching): Terkadang, tampilan yang denormalisasi berfungsi sebagai penyimpanan sementara untuk data yang sering diakses.
Namun, ini membawa risiko. Anda harus mengelola sinkronisasi data yang berulang secara manual atau melalui trigger. Jika tidak dikelola dengan hati-hati, integritas data akan terganggu.
| Faktor | Normalisasi | Denormalisasi |
|---|---|---|
| Integritas Data | Tinggi (satu sumber kebenaran) | Lebih Rendah (Membutuhkan logika sinkronisasi) |
| Kecepatan Menulis | Lebih Lambat (Banyak tabel) | Lebih Cepat (Lebih sedikit penggabungan) |
| Kecepatan Membaca | Lebih Lambat (Banyak penggabungan) | Lebih Cepat (Lebih sedikit penggabungan) |
| Penyimpanan | Efisien | Berulang |
🛠️ Kesalahan Umum dalam Desain Basis Data
Bahkan desainer berpengalaman membuat kesalahan. Hindari jebakan umum ini untuk memastikan struktur basis data Anda tetap sehat.
❌ Mengabaikan Tipe Data
Memilih tipe data yang salah dapat menyebabkan pemborosan penyimpanan dan masalah kinerja. Menggunakan bidang teks untuk tanggal atau bilangan bulat untuk nomor telepon membuang ruang dan mempersulit validasi.
❌ Normalisasi Berlebihan
Mendorong penerapan 5NF atau BCNF (Bentuk Normal Boyce-Codd) dalam setiap skenario dapat membuat kueri menjadi sangat rumit. Terkadang, 3NF sudah cukup. Jangan melakukan normalisasi hanya karena itu terlihat baik.
❌ Kunci Utama yang Lemah
Menggunakan kunci alami (seperti alamat email) sebagai kunci utama bisa berisiko jika data berubah. Kunci pengganti (bilangan bulat otomatis atau UUID) sering lebih aman untuk hubungan internal.
❌ Kekurangan Indeks
Skema yang telah dinormalisasi dengan baik masih bisa berkinerja buruk tanpa indeks yang tepat. Identifikasi kolom yang sering digunakan dalam WHERE, JOIN, atau ORDER BYklausa dan indeks mereka.
🔄 Proses Iteratif dalam Desain
Desain basis data jarang bersifat linier. Ini adalah proses iteratif. Anda mungkin mulai dengan ERD, normalisasikan, menyadari ada masalah kinerja, lakukan denormalisasi sedikit, lalu kembali meninjau ERD untuk memastikan hubungan tetap akurat.
🔄 Langkah-Langkah Penyempurnaan
- Ulas Persyaratan:Apakah fitur baru memerlukan tabel baru?
- Analisis Kueri:Lihat kueri yang paling lambat dan identifikasi hambatan utama.
- Pemeriksaan Keterbatasan:Pastikan kunci asing didefinisikan dengan benar untuk mencegah catatan terlantar.
- Dokumentasi:Jaga agar ERD Anda tetap diperbarui. Diagram yang usang justru lebih buruk daripada tidak ada diagram.
📈 Pertimbangan Kinerja
Normalisasi terutama menangani integritas data. Kinerja adalah masalah terpisah yang sering memerlukan penyesuaian. Namun, keduanya saling terkait.
🚀 Kompleksitas JOIN
Database yang sangat dinormalisasi membutuhkan lebih banyak JOINoperasi untuk mengambil data yang terkait. Mesin basis data modern sangat baik dalam mengoptimalkan JOIN, tetapi JOIN yang berlebihan masih dapat memengaruhi latensi.
📦 Mesin Penyimpanan
Mesin penyimpanan yang berbeda menangani data secara berbeda. Beberapa mengutamakan penyimpanan berbasis baris, sementara yang lain mengutamakan penyimpanan berbasis kolom. Strategi normalisasi Anda mungkin perlu disesuaikan berdasarkan mesin dasar yang digunakan.
🔒 Kendala dan Pemicu
Menerapkan aturan normalisasi melalui kendala (seperti Kunci Asing) menjamin kualitas data. Namun, penggunaan berlebihan pemicu untuk validasi dapat memperlambat operasi penulisan. Gunakan dengan bijak.
🧩 Contoh Dunia Nyata: Sistem Pesanan E-Commerce
Mari kita lihat skenario yang sedikit lebih kompleks: toko online.
Konsep ERD Awal
Pada awalnya, Anda mungkin memiliki sebuah Ordertabel yang berisi nama produk, harga, dan detail pelanggan. Ini adalah pendekatan klasik ‘file datar’.
Pendekatan Normalisasi
Untuk memperbaikinya, kita membagi data:
- Tabel Pelanggan: Menyimpan detail pelanggan (Nama, Alamat, Email).
- Tabel Produk: Menyimpan detail produk (Nama, Harga, Stok).
- Tabel Pesanan: Menyimpan transaksi (IDPelanggan, TanggalPesanan, Total).
- Tabel ItemPesanan: Menghubungkan Pesanan dan Produk (IDPesanan, IDProduk, Jumlah, HargaSaatItu).
Struktur ini memungkinkan kita untuk:
- Memperbarui harga produk di satu tempat (tabel Produk ).
- Lacak harga historis di tabel OrderItems tabel (snapshotting).
- Pastikan pelanggan tidak dapat dihapus jika mereka memiliki pesanan terbuka (melalui Foreign Keys).
🎯 Daftar Periksa Praktik Terbaik
Sebelum menerapkan skema Anda, lakukan daftar periksa ini untuk memastikan kualitas.
- ✅ Kunci Utama: Setiap tabel memiliki pengidentifikasi unik.
- ✅ Kunci Asing: Hubungan didefinisikan secara eksplisit.
- ✅ Kemungkinan Null: Kolom ditandai sebagai
TIDAK BOLEH NULLdi tempat yang sesuai. - ✅ Jenis Data: Gunakan jenis data yang paling spesifik sebisa mungkin.
- ✅ Konvensi Penamaan: Gunakan nama yang konsisten dan jelas untuk tabel dan kolom.
- ✅ Dokumentasi: ERD sesuai dengan skema fisik.
- ✅ Strategi Cadangan: Pertimbangkan bagaimana skema memengaruhi waktu cadangan dan pemulihan.
🔮 Masa Depan Desain Basis Data
Saat teknologi berkembang, prinsip dasar normalisasi dan ERD tetap relevan. Meskipun basis data NoSQL menawarkan fleksibilitas, model relasional masih mendominasi sistem transaksional. Memahami dasar-dasar ini memungkinkan Anda beradaptasi dengan teknologi baru tanpa kehilangan disiplin dalam pemodelan data.
Basis data cloud memperkenalkan dimensi baru, seperti sharding dan partitioning. Namun, struktur logis yang Anda rancang menggunakan ERD dan normalisasi tetap menjadi gambaran rancangan bagaimana data tersebut didistribusikan dan diakses.
📝 Ringkasan Poin Penting
Merancang struktur basis data yang efisien adalah keseimbangan antara struktur dan fleksibilitas. Berikut ini yang harus Anda ingat:
- ERD adalah Panduan Visual: Mereka memetakan hubungan sebelum Anda membangun.
- Normalisasi bersifat Struktural: Ini mengatur data untuk mengurangi redundansi.
- 3NF adalah Tujuan: Tujukan Bentuk Normal Ketiga untuk sebagian besar sistem transaksional.
- Denormalisasi Secara Bijak: Hanya tambahkan redundansi ketika kinerja mengharuskannya.
- Iterasi: Desain tidak pernah selesai; ia berkembang bersama aplikasi.
Dengan menggabungkan kejelasan visual Diagram Hubungan Entitas dengan aturan ketat normalisasi, Anda menciptakan fondasi data yang handal dan dapat diskalakan. Pendekatan ini menjamin bahwa basis data Anda dapat berkembang bersama aplikasi Anda, menangani kompleksitas tanpa mengorbankan integritas.
Mulailah dengan ERD yang bersih. Terapkan aturan normalisasi secara bertahap. Uji kueri Anda. Sempurnakan skema Anda. Dan selalu prioritaskan integritas data daripada kecepatan pada tahap awal.