











データベースシステムを構築することは、超高層ビルの基礎を築くことと似ています。図面に欠陥がある場合、構造はやがて圧力に耐えられず亀裂が入ります。エンティティ関係図(ERD)がその図面です。ERDは、データがどのように接続され、流れ、アプリケーション内で永続化されるかを定義します。ユーザー数が増加し、データ量が急増する中で、静的な設計はしばしばボトルネックになります。長期的な耐久性を確保するためには、初期段階からスケーラブルなERD設計原則を採用しなければなりません。このガイドでは、持続可能なシステムを構築するために必要な技術的戦略を検討します。
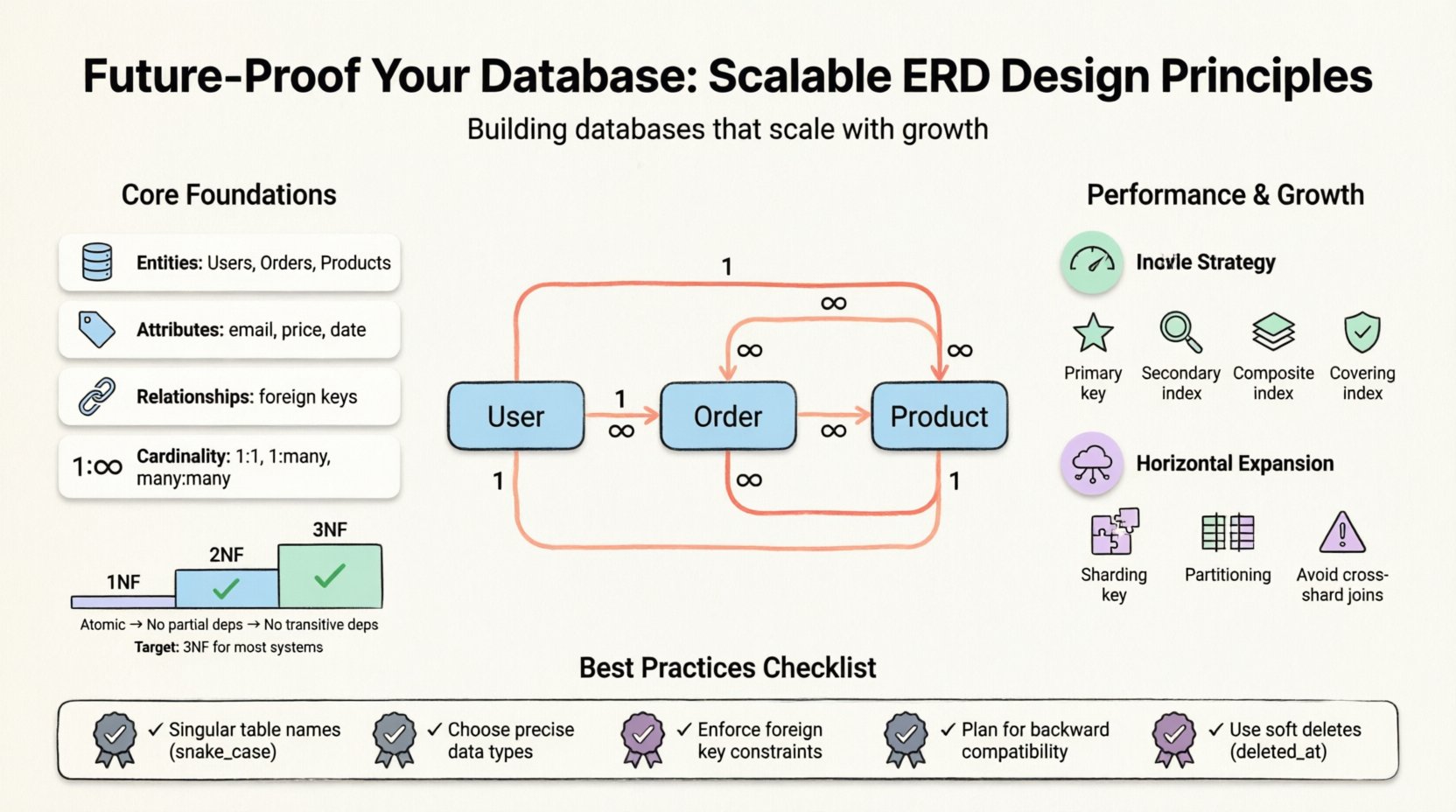
データモデリングの核を理解する 🧱
具体的な戦略に取り組む前に、ERDが何を表しているかを理解することが不可欠です。ERDはデータベースの論理構造を可視化します。エンティティ(テーブル)、属性(カラム)、関係(キー)をマッピングします。適切に設計されたモデルは、データの整合性とパフォーマンスのバランスを取っています。しかし、「ベストプラクティス」はワークロードによって異なります。読み込みが重いアプリケーションと書き込みが重いトランザクションシステムでは、最適化の方法が異なります。
主な構成要素には以下が含まれます:
- エンティティ:ユーザー、注文、製品など、主なオブジェクト。
- 属性:エンティティを定義するプロパティ、例えばメールアドレスや価格など。
- 関係:エンティティどうしの相互作用で、多くの場合、外部キーによって定義されます。
- 基数:エンティティ間の数値的な関係(1対1、1対多、多対多)。
正規化:冗長性と速度のバランス ⚖️
正規化は、冗長性を減らし、整合性を高めるためにデータを整理するプロセスです。しばしば厳格なルールとして扱われますが、実際にはトレードオフです。高い正規化は異常を最小限に抑えますが、結合(JOIN)によってクエリの複雑性が増す可能性があります。低正規化(非正規化)は読み取りを高速化しますが、データの不整合のリスクが高まります。
正規化の段階
標準形を理解することで、どこで止めるかを判断できます。各形式は特定のデータ異常に対処します。
- 第一正規形(1NF):原子性を保証します。各カラムには分割できない値が含まれる必要があります。単一のセル内に繰り返しグループや配列を含めることはできません。
- 第二正規形(2NF):1NFを基盤としています。すべての非キー属性は、主キーの一部ではなく、全体に依存しなければなりません。これにより部分的依存が排除されます。
- 第三正規形(3NF):2NFを基盤としています。非キー属性は、他の非キー属性に依存してはいけません。これにより推移的依存が排除されます。
- ボーイス・コッド正規形(BCNF):3NFのより厳格なバージョンです。決定要因が候補キーでない場合を扱います。
ほとんどのスケーラブルなシステムでは、3NFに到達することが標準的な目標です。それ以上進むと、維持管理の負担が増える一方で、得られる効果は次第に小さくなります。ただし、分析系が重いシステムでは、制御された非正規化への戻りは一般的です。
正規化のトレードオフ表
| 正規化レベル | 主な利点 | 主な欠点 |
|---|---|---|
| 1NF | 原子的なデータストレージ | なし |
| 2NF | 部分的依存関係を排除する | より多くの結合が必要 |
| 3NF | 推移的依存関係を排除する | 結合の複雑性の増加 |
| 非正規化 | 高速な読み取りクエリ | データの冗長性と更新異常 |
成長と柔軟性を考慮したスキーマ設計 📈
現在の状況だけを考慮するのでは不十分です。将来のスキーマの進化を予測しなければなりません。ビジネスロジックが変化すると、硬直した構造は崩れてしまいます。柔軟な設計により、システム全体の移行を必要とせずに拡張が可能になります。
1. 名前付け規則と標準
一貫性は保守性にとって不可欠です。混乱した名前付けは混乱やエラーを招きます。早期に標準を定め、チーム全体で徹底して遵守させることが重要です。
- 単数名を使用する: テーブルは単一のエンティティを表すべきです(例:
user、複数形のusers). - 一貫した区切り文字: テーブル名やカラム名に snake_case を使用することで、異なるオペレーティングシステムやツール間での互換性を確保します。
- 明確性のための接頭辞: 例えば、外部キーには
fk_、インデックスにはidx_を使用することで、その目的が明確になります。 - 予約語を避ける: 以下のキーワードを絶対に使用しないでください:
order,group、またはselectを列名として使用しないでください。
2. データ型と精度
適切なデータ型を選択することは、ストレージ容量とクエリ速度に影響します。あまりに一般的なデータ型はスペースを無駄にし、処理を遅くします。
- 整数: 特定の瞬間には
TINYINTフラグ(0-1)や小さなカウントに使用します。非常に大きなスケールを想定する場合にのみBIGINTを使用してください。 - 文字列: 短い値には
TEXTを使用しないでください。短い値の場合は、明確な長さを指定してVARCHARを使用することで、スペースを節約し、インデックス作成が可能になります。 - 日付: 特定の瞬間には
TIMESTAMPを使用し、カレンダー上の日付にはDATEを使用してください。常にUTCで保存して、タイムゾーンの混乱を避けてください。 - 小数: 金融データの場合は、四捨五入誤差を避けるために、浮動小数点数ではなく固定小数点数を使用してください。
関係性と基数管理 🔗
エンティティの関係性がデータの整合性を決定します。関係性が適切に管理されないと、孤立したレコードやデータ損失が発生します。
1. 外部キー制約
外部キーは参照整合性を強制します。これにより、あるテーブルのレコードが存在しないレコードを参照することはできません。一部の開発者はパフォーマンスのためこれらを無効にすることがありますが、現代のデータベースエンジンはそれらを効率的に処理できます。アプリケーション層でのチェックに頼るのは誤りを招きやすいです。
2. 多対多関係の扱い方
多対多関係(例:生徒と授業)は、2つのテーブルに直接表現できません。結合テーブル(関連エンティティ)が必要です。
- 関連する両方のテーブルの主キーを含む新しいテーブルを作成します。
- 両方の外部キーからなる複合主キーを追加します。
- このテーブルを使って、登録日時など関係性固有の追加属性を保存します。
3. オプション関係と必須関係
関係が必須かどうかを明確に定義してください。NULL外部キー列にNULL値があることは、オプションの関係であることを示します。この決定はアプリケーション層の検証ロジックに影響を与えます。
読み取りパフォーマンス向上のためのインデックス戦略 🏎️
インデックスはデータ取得を高速化する主なメカニズムです。しかし、インデックスにはコストがかかります。すべてのインデックスはディスク容量を消費し、書き込み操作(挿入、更新、削除)を遅くします。
1. 主キーインデックス
すべてのテーブルには主キーが必要です。これは通常クラスタ化されており、物理的なデータがキーの順序で格納されることを意味します。変更されない安定したキーを選択してください。パフォーマンスの観点から、サロゲートキー(自動増分整数)は自然キー(メールアドレスなど)よりも優れています。
2. セカンダリインデックス
非主キー列でのフィルタリングやソートを最適化するために、セカンダリインデックスを使用します。一般的なシナリオには以下が含まれます:
- メールアドレスで検索する場合。
- ステータスやカテゴリでフィルタリングする場合。
- 日付で結果を並べ替える場合。
3. 複合インデックス
複数の列でクエリを行う場合、個別の単一列インデックスよりも複合インデックスの方が効率的になることがあります。インデックス内の列の順序は重要です。最も選択性の高い列を最初に配置してください。
4. カバーインデックス
カバーインデックスは、クエリを満たすために必要なすべての列を含みます。これにより、データベースはメインテーブルにアクセスせずにインデックスから直接データを取得でき、I/Oを著しく削減できます。
水平スケーリングを考慮した設計 🌐
垂直スケーリング(単一サーバーにパワーを追加)には限界があります。最終的には、データを複数のノードに分散する必要があります。ERD設計はこの現実を考慮しなければなりません。
1. シャーディングキー
シャーディングは、データを複数のデータベースに分割することを意味します。シャーディングキーの選択は非常に重要です。データローカリティを確保するために、クエリで頻繁に使用されるキーを選ぶべきです。もしシャーディングキーを”user_id、そのユーザーのすべてのデータを単一のノードで簡単に照会できます。
- 良いシャーディングキー:高い基数、クエリで頻繁に使用される。
- 悪いシャーディングキー:低い基数(例:
country_code)またはめったに使われない。
2. クロスシャード結合の回避
異なるシャード間の結合は高コストで複雑です。それらの必要性を最小限に抑えるようにスキーマを設計してください。2つのエンティティのデータが必要で、それらが異なるシャードにある可能性がある場合は、データを正規化しない(デノーマライズ)ことを検討してください。結合を避けるために、必要な外部キー情報をテーブルに直接格納します。
3. パーティショニング
パーティショニングは、大きなテーブルをより小さく管理しやすい部分に分割します。範囲(日付)、リスト(カテゴリ)、ハッシュのいずれかで行うことができます。アプリケーションロジックを大きく変更せずに、メンテナンス性とクエリパフォーマンスを向上させます。
スキーマの進化とマイグレーション 🔄
要件は変化します。新しい機能には新しいカラムが必要になります。古い機能は非推奨になります。堅牢なERDは、既存の機能を破壊せずに変更に対応できます。
1. 後方互換性
新しい機能を追加する際は、古いクライアントが依然として動作することを確認してください。新しいカラムは最初にnullableとして追加してください。徐々にデータを埋めていきます。すぐにカラムを削除しないでください。非推奨としてマークし、マイグレーション期間中は保持してください。
2. データモデルのバージョン管理
スキーマのバージョンを管理してください。マイグレーションで重大な障害が発生した場合、変更をロールバックできるようにします。エラーを引き起こさずに複数回実行できる、イデムポテンであるマイグレーションスクリプトを使用してください。
3. データマイグレーションの対応
大量のデータを移動するには慎重な計画が必要です。大きなロックは本番トラフィックをブロックする可能性があります。トラフィックが少ない時間帯にマイグレーションを実行するか、可能な場合はブルーグリーンデプロイ戦略を使用してください。
避けるべき一般的な落とし穴 ⚠️
経験豊富なアーキテクトですらミスを犯します。一般的なミスに気づくことで、それらを回避できます。
- 過剰設計:まだ持っていないスケールを想定して設計すること。始まりの段階ではシンプルを保つこと。複雑さはコストとリスクを増加させる。
- ソフトデリートの無視:機密記録を即座に永続的に削除しないでください。代わりに
deleted_atタイムスタンプを使用してください。これにより監査ログが保持され、復旧が可能になります。 - 名前衝突:テーブルとカラムに同じ名前を使用すると曖昧さが生じます。単数表則に従ってください。
- 制約の欠如:アプリケーションロジックのみに依存してビジネスルールを強制すると、データの破損が発生する。制約はデータベースレベルで強制する。
- セキュリティの無視:設計にはアクセス制御用のフィールドを含めるべきである。スキーマ設計段階でロールベースのアクセス制御がサポートされることを確認する。
持続可能性のための最終的な考慮事項 🏁
スケーラブルなデータベースを作ることは継続的なプロセスである。モニタリング、分析、調整が必要である。初期段階で完璧な設計は存在しない。変更が容易な基盤を構築することが目的である。
定期的にクエリを監査する。遅延する操作を特定し、下位のスキーマを最適化する。プロファイリングツールを用いて、データがどのようにアクセスされているかを理解する。このフィードバックループにより、データが増大してもアーキテクチャが効率性を保つ。
技術は進化することを忘れないでください。新しいストレージエンジンやクエリ言語が登場する。柔軟なスキーマは、硬直したスキーマよりもこれらの変化に適応しやすい。コアとなる関係性とデータの整合性に注目する。ツールが変化しても、これらは変わらない。
これらの原則に従うことで、耐障害性のあるシステムを構築できる。成長に応じてスムーズに対応し、負荷下でもパフォーマンスを維持できる。これがデータベースインフラを将来に備えて強化する本質である。