











データベースを設計することは、単にデータを保存することにとどまらない。情報の構造を、整合性を保ち、重複を減らし、パフォーマンスを最適化する形で整えることである。効率的なデータベース構造について語るとき、二つの柱が際立つ:エンティティ関係図(ERD) および 正規化これらの概念は独立した技術ではなく、互いに補い合うツールであり、堅固なデータ基盤を構築するために連携して機能する。
このガイドでは、ERDの視覚的明確性と正規化の構造的厳密性を統合する方法を探る。概念モデルを、時代を経ても耐えうる実用的なスキーマに変換するプロセスを丁寧に説明する。
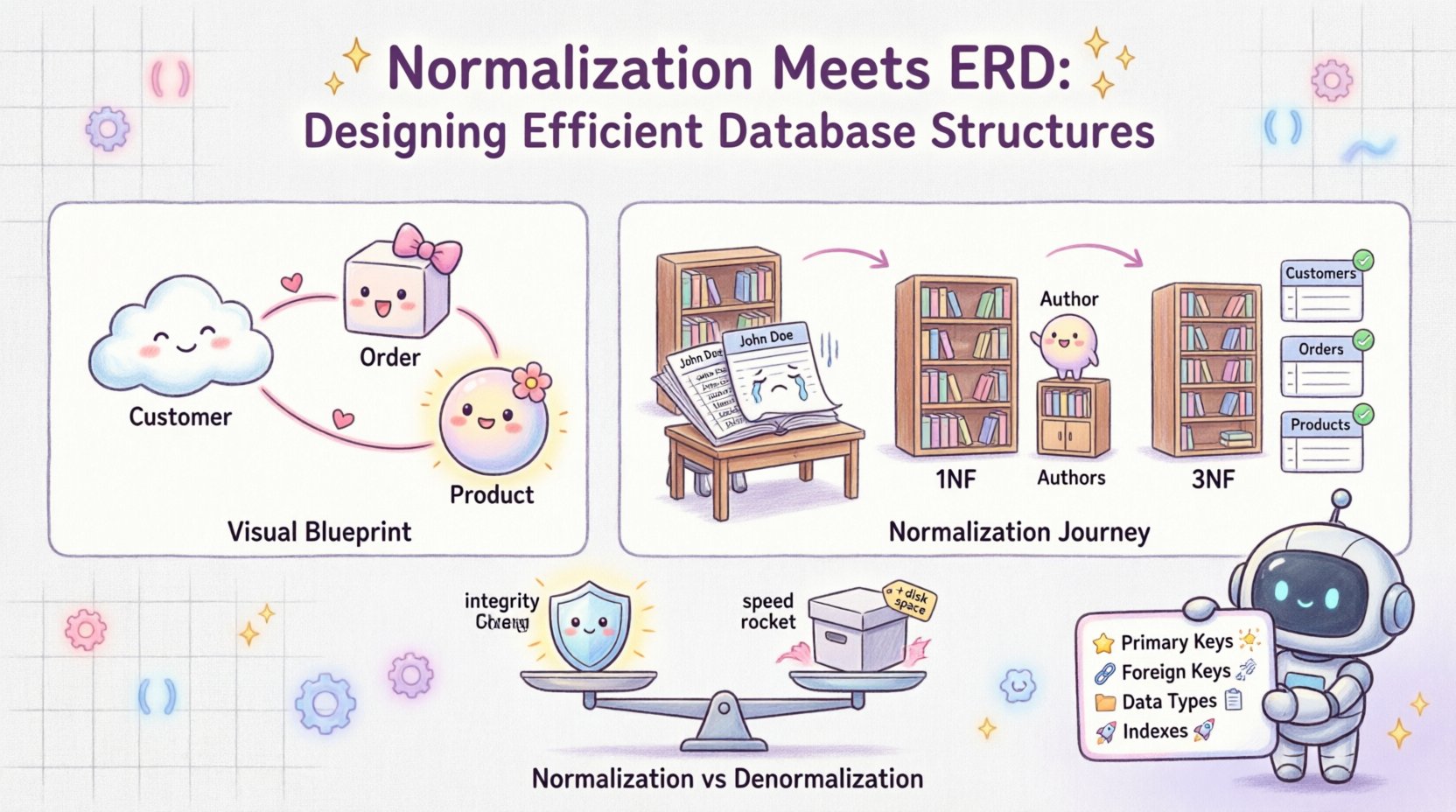
📐 基盤を理解する:ERDと正規化
設計プロセスに取り組む前に、これらの二つの手法がそれぞれ果たす異なる役割を理解することが不可欠である。
📊 エンティティ関係図とは何か?
エンティティ関係図は、データベースの視覚的設計図として機能する。エンティティ(テーブル)、属性(列)、それらの間の関係(リンク)を明示する。まるで建物の建築図のようなものだ。次のような問いに答えることができる:
- 私たちのシステムにおける核心となるオブジェクトは何ですか?(例:顧客, 注文)
- これらのオブジェクトはどのように相互作用しますか?(例:1人の顧客が多数の注文)
- 各オブジェクトに保存する必要のあるデータは何ですか?(例:顧客には氏名 および メールアドレス)
ERDがなければ、データベース設計は当てずっぽうのゲームになってしまう。ステークホルダーが理解できる高レベルな視点を提供し、コードが1行も書かれる前に、全員がデータ要件について合意できるようにする。
🧼 正規化とは何か?
正規化とは、データの重複を減らし、データの整合性を高めるために、データベース内のデータを整理するプロセスです。大きなテーブルをより小さな論理構造に分割し、それらの間の関係を定義することを含みます。目的は、各データが正確に1か所にのみ格納されることを保証することです。
なぜこれが重要なのか?
- データ整合性:顧客の住所が変更された場合、1か所で更新すればよく、10か所を更新する必要はありません。
- ストレージ効率:重複データが少なければ、ディスクスペースの使用量も少なくなります。
- 保守性:時間の経過とともに、スキーマの保守や更新が容易になります。
⚙️ 交差点:ERDと正規化の統合
データベース設計はしばしばERDから始まりますが、原始的なERDは生産環境にすぐには使用できません。正規化が対処する重複がしばしば含まれているからです。ワークフローは、概念的ERDを作成し、異常を検出するために分析し、正規化ルールを適用してスキーマを洗練することを含みます。
以下が一般的なワークフローです:
- 概念設計:要件に基づいて初期のERDを描画する。
- 論理設計:ERDをテーブルと列に洗練する。
- 正規化:異常を解消するために、正規化形式(1NF、2NF、3NF)を適用する。
- 物理設計:特定のデータベースエンジンおよびパフォーマンス要件に最適化する。
🔍 ステップバイステップ:ERDから正規化スキーマへ
実際にどう機能するかを確認するために、実際のシナリオをステップバイステップで見ていきましょう。図書館を管理するシステムを構築していると想像してください。
1. 正規化前の状態
初期段階では、本と著者のすべての情報を保持する1つのテーブルを設計するかもしれません。これを非正規化テーブルと呼びます。
| BookID | タイトル | 著者名 | 著者電話番号 | ジャンル |
|---|---|---|---|---|
| 101 | 偉大な小説 | ジョン・ドー | 555-0101 | フィクション |
| 102 | ミステリー本 | ジョン・ドー | 555-0101 | ミステリー |
| 103 | 別の本 | ジェーン・スミス | 555-0102 | フィクション |
ここに問題があることに気づきましたか?ジョン・ドーの電話番号が繰り返されています。もし彼が番号を変更したら、複数の行を更新しなければなりません。これは更新異常.
2. 第1正規形(1NF)
正規化の最初のルールは、原子性を確保することです。各列には単一の値のみを含み、繰り返しグループがあってはなりません。
- ルール:繰り返しグループを排除し、原子値を確保する。
- 適用: 当社の図書館の例では、初期テーブルはすでに原子的かもしれませんが、プライマリキーを持っていることを確認する必要があります。仮にBookIDは一意であると仮定します。
- 結果: 今や、各セルに1つのデータしか格納されていないテーブルを持っています。
3. 第2正規形(2NF)
テーブルが1NFにあれば、部分的依存関係を確認します。テーブルが2NFにあるのは、1NFにあり、かつすべての非キー属性がプライマリキーに完全に依存している場合です。
- シナリオ: もし複合キー(例:BookID + AuthorID)があった場合、AuthorPhoneが全体のキーに依存しているか、あるいは著者部分だけに依存しているかを確認する。
- アクション: 今回の例では、AuthorPhoneはAuthorNameに依存しており、BookIDではない。これは、著者データを書籍データから分離すべきであることを示唆している。
4. 第三正規形(3NF)
ここが本当の魔法が発動する場所です。3NFは推移的依存を排除します。非キー属性は他の非キー属性に依存してはいけません。
- ルール:どの属性も、他の非キー属性に依存してはいけません。
- 適用: AuthorPhoneはAuthorNameに依存している。AuthorNameが書籍テーブルの主キーではないため、著者情報を別々のAuthorsテーブルに移動する。
- 結果: さて、著者の電話番号を更新するには、データベースの「著者」テーブルのレコードを1つだけ変更すればよい。著者 テーブルで、複数のレコードを変更する必要はない。書籍 テーブル。
📋 正規化 vs. 非正規化:バランスを見つける
正規化は整合性にとって不可欠ですが、パフォーマンスのための万能解ではありません。場合によっては、データの読み込みが書き込みよりも頻繁に行われるのです。このような状況では、非正規化 が有益になることがあります。
📉 非正規化すべきタイミング
非正規化とは、読み取りパフォーマンスを向上させるために、正規化されたデータベースに重複データを追加することです。これは、ストレージと速度のトレードオフです。
- 高頻度の読み取り: アプリケーションが1秒間に数千回データを照会する場合、テーブルの結合はパフォーマンスを低下させる可能性があります。
- レポートダッシュボード: 集計データはあらかじめ計算・保存されており、複雑なクエリを回避することができる。
- キャッシュ戦略: 時には、非正規化されたビューが頻繁にアクセスされるデータのキャッシュとして機能する。
しかし、これにはリスクがあります。重複データの同期を手動またはトリガーで管理しなければなりません。適切に処理されないと、データの整合性が損なわれます。
| 要因 | 正規化 | 非正規化 |
|---|---|---|
| データ整合性 | 高い(唯一の真実のソース) | 低い(同期ロジックが必要) |
| 書き込み速度 | 遅い(複数のテーブル) | 速い(結合が少ない) |
| 読み取り速度 | 遅い(複数の結合) | 速い(結合が少ない) |
| ストレージ | 効率的 | 冗長 |
🛠️ データベース設計における一般的な落とし穴
経験豊富なデザイナーでさえミスを犯すことがあります。データベース構造が健全な状態を保つために、これらの一般的な罠を避けてください。
❌ データ型の無視
適切でないデータ型を選択すると、ストレージの膨張やパフォーマンスの問題につながります。日付にテキストフィールドを使用したり、電話番号に整数を使用したりすると、スペースを無駄に使い、検証を複雑にします。
❌ 過剰な正規化
すべての状況で5NFやBCNF(ボイス・コッド正規形)を目指すと、クエリが非常に複雑になります。場合によっては3NFで十分です。単に正規化するためだけに正規化してはいけません。
❌ 弱い主キー
データが変更される可能性がある場合、自然キー(メールアドレスなど)を主キーとして使用するのはリスクがあります。内部の関係性には、擬似キー(自動増分の整数やUUID)の方が安全なことが多いです。
❌ インデックスの欠如
適切に正規化されたスキーマでも、適切なインデックスがなければパフォーマンスが低下する可能性があります。頻繁に使用される列を特定し、WHERE, JOIN、またはORDER BY句で使用される列を特定し、それらにインデックスを設定してください。
🔄 設計の反復プロセス
データベース設計はほとんど線形ではありません。反復的なプロセスです。ERDから始め、正規化し、パフォーマンスに問題があることに気づき、わずかに非正規化し、その後ERDを再確認して関係性が正確であることを確認するかもしれません。
🔄 フィニッシュステップ
- 要件の見直し:新しい機能に新しいテーブルが必要ですか?
- クエリ分析:最も遅いクエリを確認し、ボトルネックを特定してください。
- 制約の確認:孤立したレコードを防ぐために、外部キーが適切に定義されていることを確認してください。
- ドキュメント化:ERDを常に最新の状態に保ってください。古くなった図は、何も描かれていない図よりも悪いです。
📈 パフォーマンスに関する考慮事項
正規化は主にデータの整合性に対処します。パフォーマンスは別問題であり、しばしばチューニングが必要です。しかし、両者は関連しています。
🚀 JOINの複雑さ
非常に正規化されたデータベースは、より多くのJOIN操作が必要になります。現代のデータベースエンジンはJOINの最適化が非常に優れていますが、過剰なJOINは依然としてレイテンシに影響を及ぼす可能性があります。
📦 ストレージエンジン
異なるストレージエンジンはデータを異なる方法で扱います。一部は行ベースのストレージを好む一方、他のものは列ベースのストレージを好みます。あなたの正規化戦略は、基盤となるエンジンに応じて調整が必要になる場合があります。
🔒 制約とトリガー
制約(外部キーなど)を用いて正規化ルールを強制することで、データの品質が保証されます。しかし、検証にトリガーを過剰に使用すると、書き込み操作が遅くなる可能性があります。賢く使いましょう。
🧩 実際の例:ECオーダーシステム
少し複雑なシナリオを見てみましょう:オンラインストアです。
初期のERDコンセプト
最初は、Orderテーブルがあり、製品名、価格、顧客情報が含まれます。これは伝統的な「フラットファイル」アプローチです。
正規化アプローチ
これを修正するために、データを分割します:
- Customersテーブル: 顧客情報を格納します(名前、住所、メールアドレス)。
- Productsテーブル: 製品情報を格納します(名前、価格、在庫)。
- Ordersテーブル: 取引情報を格納します(顧客ID、注文日、合計)。
- OrderItemsテーブル: 注文と製品をリンクします(注文ID、製品ID、数量、注文時の価格)。
この構造により、次のようなことが可能になります:
- 製品価格を1か所で更新できます(Productsテーブル)。
- 履歴価格を「OrderItems」テーブル(スナップショット)
- 外部キーを通じて、顧客に未処理の注文がある場合は削除できないようにする。
🎯 ベストプラクティスチェックリスト
スキーマをデプロイする前に、このチェックリストを確認して品質を確保してください。
- ✅ 主キー: すべてのテーブルに一意の識別子がある。
- ✅ 外部キー: 関係が明示的に定義されている。
- ✅ NULL許容性: 列は「
NOT NULL」としてマークされている。 - ✅ データ型: 可能な限り具体的なデータ型を使用する。
- ✅ 命名規則: テーブルと列に一貫性があり、明確な名前を使用する。
- ✅ ドキュメント: ERDが物理スキーマと一致している。
- ✅ バックアップ戦略: スキーマがバックアップおよび復元時間に与える影響を検討する。
🔮 データベース設計の未来
技術が進化する中で、正規化とERDの基本原則は依然として重要です。NoSQLデータベースは柔軟性を提供しますが、関係モデルは依然としてトランザクションシステムを支配しています。基礎を理解することで、データモデリングの厳密さを失うことなく、新しい技術に適応できます。
クラウドデータベースは、シャーディングやパーティショニングといった新しい次元をもたらします。しかし、ERDと正規化を使って設計した論理構造は、データの分散とアクセス方法の設計図として機能し続けます。
📝 主なポイントの要約
効率的なデータベース構造を設計することは、構造と柔軟性のバランスです。以下の点を覚えておきましょう:
- ERDは視覚的ガイドです: ビルドする前に、関係をマッピングします。
- 正規化は構造的です: データの重複を減らすために整理します。
- 3NFが目標です: 多くのトランザクションシステムでは、第三正規形を目指しましょう。
- デノーマライズは賢く行いましょう: パフォーマンスが要求する場合にのみ、重複を追加します。
- 反復しましょう: デザインは終わりがありません。アプリケーションと共に進化します。
エンティティ関係図の視覚的明確さと正規化の厳密なルールを組み合わせることで、信頼性とスケーラビリティの両方を備えたデータ基盤を構築できます。このアプローチにより、データベースがアプリケーションと共に成長し、整合性を保ちながら複雑さに対処できるようになります。
清潔なERDから始めましょう。正規化ルールを段階的に適用します。クエリをテストし、スキーマを改善しましょう。初期段階では、常に速度よりもデータの整合性を最優先してください。