











システム工学の分野は顕著な変化を遂げつつある。長年にわたり、システムモデリング言語(SysML)は複雑な要件、振る舞い、構造を定義する基盤として機能してきた。しかし、現在の視野は、モデルが単に設計を記録するだけでなく、実行可能なアーティファクトを積極的に合成するより統合的なアプローチへと移行しつつある。この移行は、受動的なドキュメント作成から能動的なエンジニアリング合成への転換を意味する。
この包括的なガイドでは、SysMLエコシステム内における自動コード生成の動向を検討する。技術的基盤、必要なアーキテクチャの変更、エンジニアリングチームが求められる戦略的準備について探求する。目的は、モデルが実装を駆動する堅牢なワークフローを構築することであり、忠実度を損なわず、管理されない複雑性を導入しないことである。
🛠️ モデル駆動型開発の現状
現在、多くの組織がSysMLを用いて高レベルの抽象化を構築している。これらのモデルは、ステークホルダーにとって単一の真実の源として機能することが多く、ハードウェア、ソフトウェア、システム工学の分野間のコミュニケーションを促進する。この成功にもかかわらず、モデルと最終的な展開されたシステムとの間にしばしばギャップが生じる。このギャップは通常、手動による翻訳プロセスで埋められるが、これにより人的ミスの可能性が生じ、設計意図と実装との間にずれが生じるリスクが高まる。
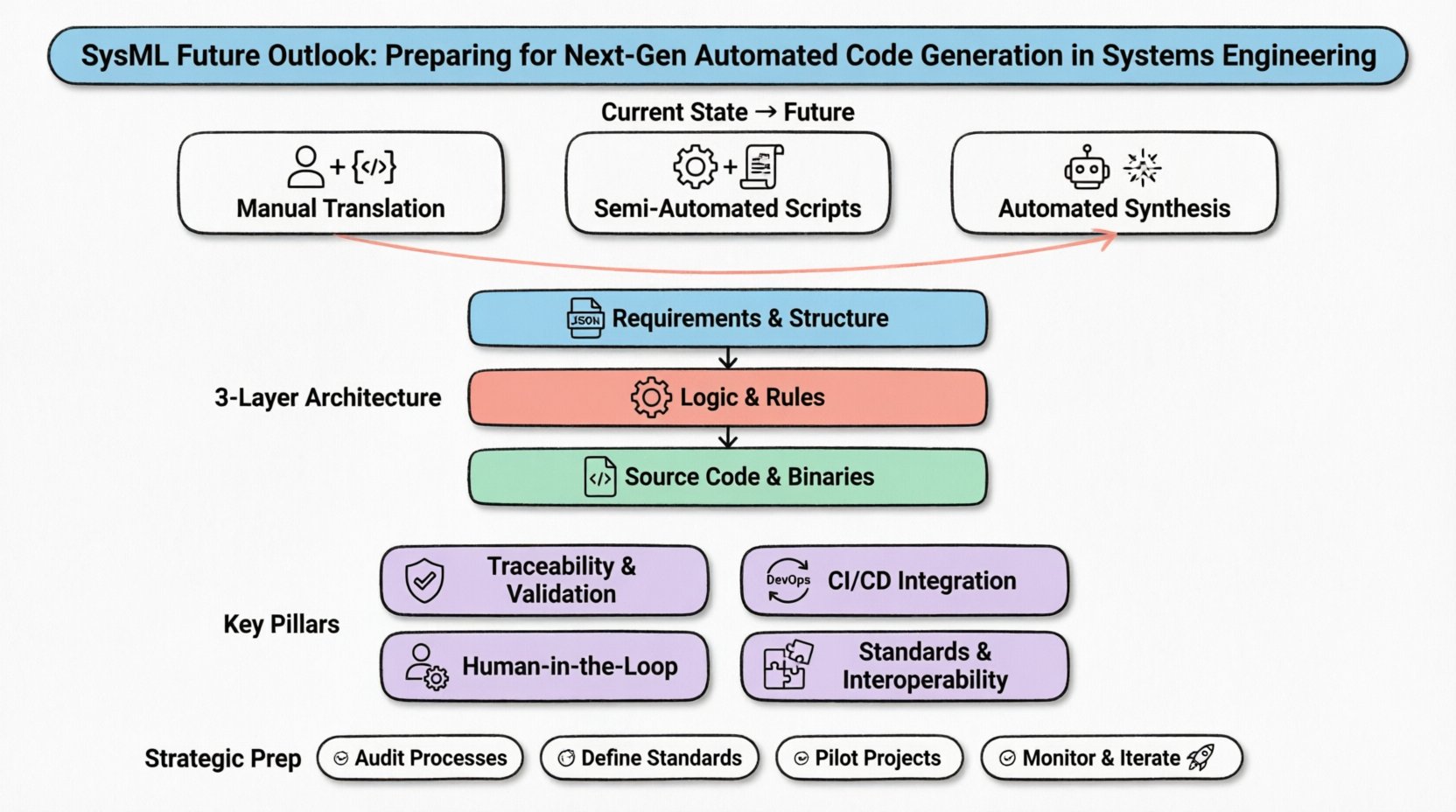
この文脈におけるモデル駆動型開発(MDE)の現状は、主に三つのアプローチに分類できる:
-
手動翻訳:エンジニアは図を読み、直接コードを記述する。これは人的負荷が大きく、一貫性の欠如を招きやすい。
-
準自動スクリプト:カスタムスクリプトがモデルリポジトリからデータを抽出し、ボイラープレートコードを生成する。速いとはいえ、しばしば大きな保守作業を要し、意味的深さに欠ける。
-
標準変換:特定のSysML図をコードスタブに変換するための既定のパターンが存在する。構造には有用だが、動的振る舞いにはしばしば対応できない。
現在の状態の限界は、生成プロセスがしばしば脆弱である点にある。モデルの変更が頻繁に生成スクリプトの再作業を要し、脆弱なパイプラインを生み出す。業界は、変換ロジックを特定のモデル構文から分離したより耐性のあるアーキテクチャへと移行しており、より高い適応性を可能にする。
⚙️ 自動合成への移行
自動コード生成は新しい概念ではないが、複雑なシステム工学における応用は進化している。次世代のツールとプロセスは、意味的整合性に焦点を当てる。つまり、生成されたコードはコンパイルできることに加え、SysMLモデルで定義された論理制約、状態遷移、データフローを正確に反映しなければならない。
この移行は、いくつかの重要な技術的要因に依存している:
-
強化されたメタモデリング:言語構造の高度な定義により、振る舞い論理のより正確な抽出が可能になる。
-
グラフ変換エンジン:これらのエンジンはモデルをグラフとして処理し、関係性をナビゲートするルールを適用して、動的にコードセグメントを生成する。
-
制約解決:制約ソルバーとの統合により、生成されたコードが要件で定義された安全性およびタイミング制約を遵守することを保証する。
これらの技術を実装する際の焦点は、エンジニアの認知的負荷を軽減することにある。状態機械やアクティビティ図の翻訳を自動化することで、エンジニアは構文の詳細ではなく、論理やアーキテクチャに注力できる。これにより、設計フェーズにおいてより高い抽象度が可能になる。
🏗️ 未来のコード生成の技術的アーキテクチャ
自動合成を効果的に支援するためには、モデリング環境の基盤となるアーキテクチャが堅牢でなければならない。現代的な生成パイプラインは通常、三つの異なるレイヤーで構成される:モデルレイヤー、変換レイヤー、アーティファクトレイヤー。
1. モデルレイヤー
このレイヤーにはSysMLモデルが含まれる。バージョン管理、ブランチ、競合解決をサポートしなければならない。コード生成を信頼できるものにするためには、モデルが適切に構成されている必要がある。無効な状態が生成プロセスに伝搬しないように、モデルの入力ポイントで検証ルールを適用するべきである。
2. 変換レイヤー
これはコアのロジックエンジンである。モデルデータを読み取り、変換ルールを適用して中間表現を生成する。高度な設定では、このレイヤーが変換ルール自体を記述するためにドメイン固有言語(DSL)を活用する可能性があり、これにより監査や修正が容易になる。
3. アーティファクトレイヤー
このレイヤーは最終出力の処理を担当します。ソースコード、構成ファイル、ドキュメントを含みます。ターゲットビルド環境と互換性がある必要があります。このレイヤーは、生成されたアーティファクトが即座にテスト可能であることを保証するために、既存の継続的インテグレーションツールと頻繁に連携します。
以下の表は、各レイヤーの責任を概説しています:
|
レイヤー |
主な責任 |
主要出力 |
|---|---|---|
|
モデル |
要件と構造を定義する |
XML/JSON モデルファイル |
|
変換 |
論理とルールを適用する |
中間コード/抽象構文木 |
|
アーティファクト |
デプロイ可能なファイルを生成する |
ソースコード、バイナリ |
🛡️ 検証と検査における課題
自動コード生成における最も重要な側面の一つは、出力が正しいことを保証することです。モデルが正しいにもかかわらず、ジェネレータがエラーを導入すると、システム全体が危うくなります。検証と検査(V&V)は、生成パイプラインに統合されるべきであり、別段階として扱うべきではありません。
主な課題には以下が含まれます:
-
トレーサビリティ:生成されたコードの各行が、SysMLモデル内の特定の要素に追跡可能であることを保証すること。これがないと、デバッグはほぼ不可能になります。
-
動作の同等性:生成されたコードの実行時動作が、モデルのシミュレーション動作と一致することを証明すること。ステートマシンは特に微細なタイミングのずれに起因する問題を引き起こしやすい。
-
ツールチェーンの互換性:生成されたコードがターゲットコンパイラおよびオペレーティングシステムと互換性があることを確認すること。異なる言語やプラットフォームには、それぞれ異なる標準やライブラリがあります。
これらの課題に対処するために、チームはしばしばラウンドトリップエンジニアリングアプローチを採用します。これは、コードを生成し、コンパイルして、実行結果をモデルに戻して整合性を検証するプロセスを含みます。不一致が見つかった場合、モデルが更新され、このサイクルが繰り返されます。これにより、モデルが真実の権威あるソースであることが保証されます。
🔄 DevOpsおよびCI/CDパイプラインとの統合
自動コード生成は、現代のDevOps実践に自然に適合します。継続的インテグレーションおよび継続的デプロイメント(CI/CD)環境では、SysMLモデルがビルドパイプラインのトリガーとなります。モデルの変更がコミットされると、生成プロセスが自動的に実行され、その後、コンパイル、テスト、パッケージングが行われます。
この統合には以下の利点があります:
-
より迅速なフィードバックループ: エンジニアは、モデルの変更が有効なコードをもたらすかどうかについて、即時にフィードバックを受けます。
-
一貫したビルド:生成プロセスは決定論的であり、同じモデルが常に同じコードアーティファクトを生成することを保証します。
-
人的ミスの削減:ビルドプロセスにおける手動ステップが最小限に抑えられ、人的ミスのリスクが低減されます。
しかし、モデル生成をCI/CDに統合するには慎重な設定が必要です。生成プロセスは計算コストが高くなる可能性があるため、キャッシュ戦略が不可欠です。さらに、パイプラインは失敗を適切に処理できる必要があります。生成ステップが失敗した場合、パイプラインは直ちに停止し、チームに通知すべきであり、破損したコードがマージされるのを防ぐべきです。
👤 ヒューマンインザループに関する考慮事項
自動化の進展にもかかわらず、エンジニアの役割は中心的です。複雑で安全が求められるシステムでは、完全な自律的生成はまだ現実的ではありません。アーキテクチャの決定、制約の設定、例外処理には人間の要素が必要です。
効果的なワークフローは、自動化と人的監視のバランスを保ちます:
-
レビューのゲート:生成されたコードの重要な部分は、展開前にシニアエンジニアによるレビューが必要です。
-
オーバーライド機構:エンジニアは、特定のエッジケースに対して手動コードを生成出力に挿入できるようにする必要があります。
-
トレーニング:エンジニアは生成ツールの限界を理解する必要があります。出力に信頼を置くべき時と、介入すべき時を把握しなければなりません。
このアプローチにより、システムは人間の創造性の柔軟性を維持しながら、自動化の効率性を活用できます。目的はエンジニアを置き換えることではなく、その能力を強化することです。
🔗 標準化と相互運用性
業界が自動化へと進む中で、相互運用性が重要な課題となります。異なるモデリングツールやコード生成エンジンは、データをシームレスに交換できる必要があります。ベンダーの縛りを防ぎ、長期的な保守性を確保するためには、オープンな標準への準拠が不可欠です。
標準化の主な領域には以下が含まれます:
-
モデル交換フォーマット:モデルデータに標準化されたファイルフォーマットを使用することで、異なるツール間でモデルを移動してもデータ損失が生じないことが保証されます。
-
変換言語:変換ルールを記述するための共通言語により、チーム間での生成ロジックの共有が容易になります。
-
API:オープンなアプリケーションプログラミングインターフェース(API)により、要件管理やテスト管理ツールなどの外部システムとのカスタム統合が可能になります。
組織は、これらの標準をサポートするツールやプラットフォームを優先すべきです。これにより、エンジニアリング投資の将来性が確保され、新しいツールが利用可能になった際にも、ワークフロー全体を中断することなく導入が可能になります。
🎓 次世代エンジニアに求められるスキル
自動コード生成の台頭により、システムエンジニアに求められるスキルセットが変化しています。ドメイン知識は依然として重要ですが、モデル変換およびソフトウェアエンジニアリングの実践における技術的熟練度も同様に重要になります。
必須のスキルには以下が含まれます:
-
モデル分析: 複雑なモデル構造を読み取り、理解し、適切に構成されていることを確認する能力。
-
スクリプト作成と自動化:生成ロジックのカスタマイズやパイプライン管理に使用されるスクリプト言語への熟練。
-
ソフトウェアアーキテクチャ:生成されたコードが広範なソフトウェアアーキテクチャにどのように適合するか、および他のシステムとどのように相互作用するかを理解すること。
-
品質保証:モデル生成コードに特化したテスト戦略に関する知識、ユニットテストおよび統合テストを含む。
トレーニングプログラムは、進化する環境に従業員を備えるためにこれらの分野に注力すべきである。ツールや基準が継続的に進化しているため、継続的な学習が不可欠である。
📋 戦略的準備の概要
次世代の自動コード生成に対応するためには戦略的なアプローチが必要である。新しいツールを導入するだけではなく、エンジニアリングプロセスそのものを見直す必要がある。組織はトレーニングへの投資、明確な基準の確立、既存のワークフローとシームレスに統合できる堅牢なパイプラインの構築を進めるべきである。
準備のための主なステップには以下が含まれる:
-
現在のプロセスの監査:手動翻訳が遅延やエラーを引き起こしているボトルネックや領域を特定する。
-
基準の定義:モデルの品質および生成出力に関する明確なガイドラインを確立する。
-
パイロットプロジェクト:スケーリングする前に、生成ツールのテストとワークフローの最適化を行うために、小さな制御されたプロジェクトから始める。
-
モニタリングと改善:生成プロセスの効果を継続的に測定し、必要に応じて調整を行う。
システム工学の未来は、モデルとコードのシームレスな統合にある。自動化を採用しつつ厳格な監視を維持することで、組織はより高い品質のシステムをより短い時間で達成できる。移行は挑戦的だが、効率性と信頼性という点で大きな報酬が得られる。
⚡ 結論
SysMLと自動コード生成の進化は、システム工学における転換点を象徴している。設計と実装の間のギャップを、これまで以上に効果的に埋める可能性を提供している。技術的アーキテクチャを理解し、検証の課題に対処し、従業員を準備することで、組織はこの移行を成功裏に乗り越えることができる。焦点は、厳密でモデル駆動のアプローチを通じて、堅牢で信頼性の高いシステムを構築することにある。