Designing a database is not merely about storing data; it is about structuring information in a way that ensures integrity, reduces redundancy, and optimizes performance. When we talk about efficient database structures, two pillars stand out: Entity Relationship Diagrams (ERD) and Normalization. These concepts are not isolated techniques but complementary tools that work together to create a robust data foundation.
This guide explores how to merge the visual clarity of ERDs with the structural rigor of normalization. We will walk through the process of transforming a conceptual model into a practical schema that stands the test of time.
📐 Understanding the Foundation: ERDs and Normalization
Before diving into the design process, it is essential to understand the distinct roles of these two methodologies.
📊 What is an Entity Relationship Diagram?
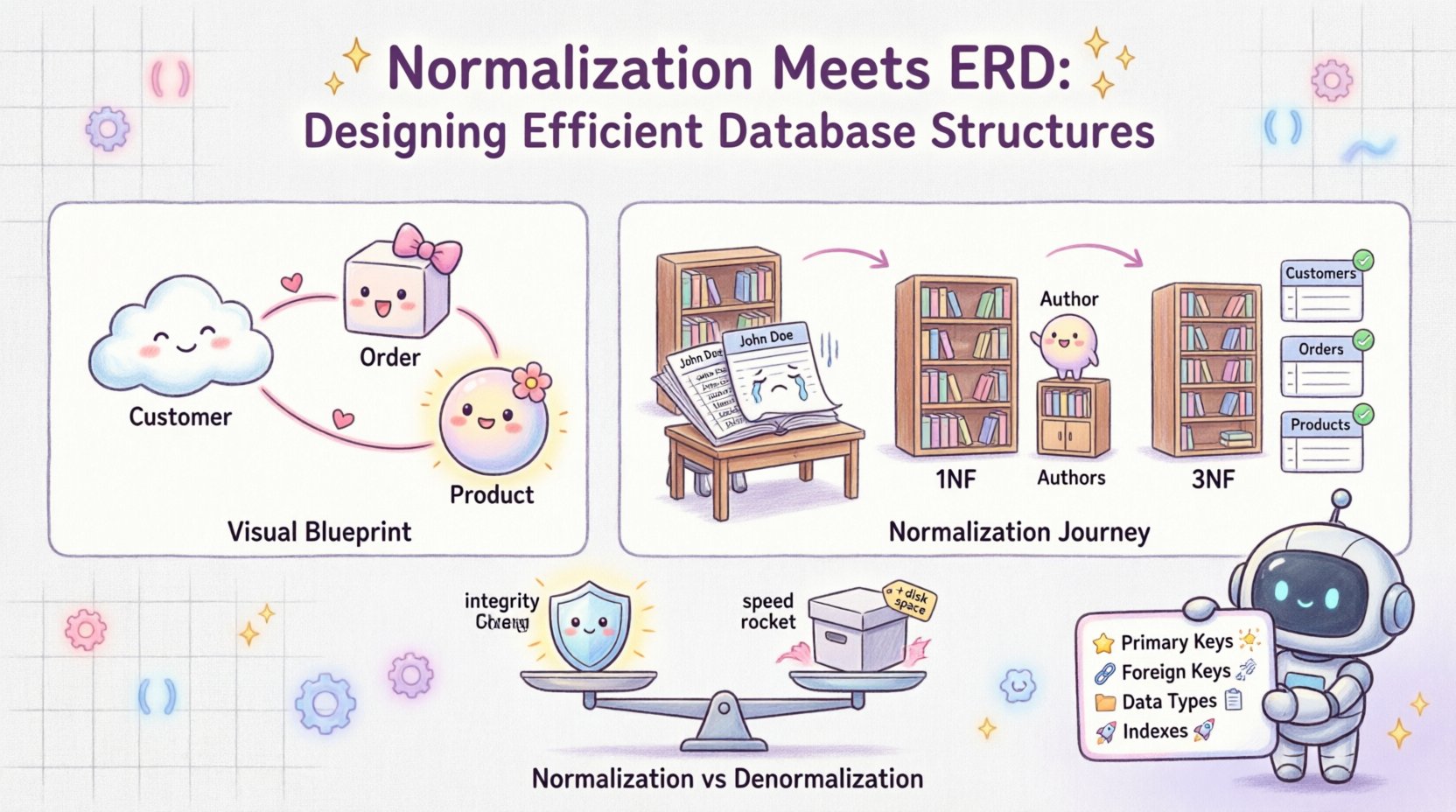
An Entity Relationship Diagram serves as the visual blueprint of a database. It maps out the entities (tables), attributes (columns), and relationships (links) between them. Think of it as the architectural drawing for a building. It answers questions like:
- What are the core objects in our system? (e.g., Customer, Order)
- How do these objects interact? (e.g., A Customer places many Orders)
- What data do we need to store for each object? (e.g., Customer needs a Name and Email)
Without an ERD, database design becomes a guessing game. It provides a high-level view that stakeholders can understand, ensuring everyone agrees on the data requirements before a single line of code is written.
🧼 What is Normalization?
Normalization is the process of organizing data in a database to reduce redundancy and improve data integrity. It involves dividing large tables into smaller, logical structures and defining relationships between them. The goal is to ensure that each piece of data is stored in exactly one place.
Why does this matter?
- Data Integrity: If a customer’s address changes, you update it in one place, not ten.
- Storage Efficiency: Less duplicate data means less disk space usage.
- Maintenance: Easier to maintain and update the schema over time.
⚙️ The Intersection: Merging ERD with Normalization
Designing a database often starts with an ERD, but a raw ERD is rarely ready for production. It often contains redundancies that normalization addresses. The workflow involves creating a conceptual ERD, analyzing it for anomalies, and applying normalization rules to refine the schema.
Here is the typical workflow:
- Conceptual Design: Draw the initial ERD based on requirements.
- Logical Design: Refine the ERD into tables and columns.
- Normalization: Apply normalization forms (1NF, 2NF, 3NF) to eliminate anomalies.
- Physical Design: Optimize for the specific database engine and performance needs.
🔍 Step-by-Step: From ERD to Normalized Schema
Let us walk through a practical scenario to see how this works in action. Imagine we are building a system to manage a library.
1. The Unnormalized State
Initially, you might design a single table to hold all information about books and authors. This is known as an unnormalized table.
| BookID | Title | AuthorName | AuthorPhone | Genre |
|---|---|---|---|---|
| 101 | The Great Novel | John Doe | 555-0101 | Fiction |
| 102 | The Mystery Book | John Doe | 555-0101 | Mystery |
| 103 | Another Book | Jane Smith | 555-0102 | Fiction |
Notice the issues here? John Doe‘s phone number is repeated. If he changes his number, you must update multiple rows. This is an Update Anomaly.
2. First Normal Form (1NF)
The first rule of normalization is to ensure atomicity. Each column must contain only a single value, and there should be no repeating groups.
- Rule: Eliminate repeating groups and ensure atomic values.
- Application: In our library example, the initial table might already be atomic, but we must ensure we have a Primary Key. Let’s assume BookID is unique.
- Result: We now have a table where every cell holds one piece of data.
3. Second Normal Form (2NF)
Once a table is in 1NF, we check for partial dependencies. A table is in 2NF if it is in 1NF and every non-key attribute is fully dependent on the primary key.
- Scenario: If we had a composite key (e.g., BookID + AuthorID), we would check if AuthorPhone depends on the whole key or just the author part.
- Action: In our example, AuthorPhone depends on AuthorName, not the BookID. This suggests we should separate author data from book data.
4. Third Normal Form (3NF)
This is where the real magic happens. 3NF eliminates transitive dependencies. Non-key attributes should not depend on other non-key attributes.
- Rule: No attribute should depend on another non-key attribute.
- Application: AuthorPhone depends on AuthorName. Since AuthorName is not the primary key of the book table, we move author information to a separate Authors table.
- Result: Now, updating an author’s phone number requires changing only one record in the Authors table, not multiple records in the Books table.
📋 Normalization vs. Denormalization: Finding Balance
While normalization is crucial for integrity, it is not always the answer for performance. Sometimes, reading data is more frequent than writing it. In these cases, denormalization might be beneficial.
📉 When to Denormalize
Denormalization involves adding redundant data to a normalized database to improve read performance. It is a trade-off between storage and speed.
- High Read Volume: If your application queries data thousands of times a second, joining tables can slow down performance.
- Reporting Dashboards: Aggregated data might be pre-calculated and stored to avoid complex queries.
- Caching Strategies: Sometimes, denormalized views act as a cache for frequently accessed data.
However, this comes with risks. You must manage the synchronization of redundant data manually or through triggers. If not handled carefully, data integrity suffers.
| Factor | Normalization | Denormalization |
|---|---|---|
| Data Integrity | High (Single source of truth) | Lower (Requires sync logic) |
| Write Speed | Slower (Multiple tables) | Faster (Fewer joins) |
| Read Speed | Slower (Multiple joins) | Faster (Less joins) |
| Storage | Efficient | Redundant |
🛠️ Common Pitfalls in Database Design
Even experienced designers make mistakes. Avoid these common traps to ensure your database structure remains healthy.
❌ Ignoring Data Types
Choosing the wrong data type can lead to storage bloat and performance issues. Using a text field for dates or integers for phone numbers wastes space and complicates validation.
❌ Over-Normalization
Pushing for 5NF or BCNF (Boyce-Codd Normal Form) in every scenario can make queries incredibly complex. Sometimes, 3NF is sufficient. Do not normalize just for the sake of it.
❌ Weak Primary Keys
Using natural keys (like email addresses) as primary keys can be risky if data changes. Surrogate keys (auto-incrementing integers or UUIDs) are often safer for internal relationships.
❌ Missing Indexes
A well-normalized schema can still perform poorly without proper indexing. Identify columns used frequently in WHERE, JOIN, or ORDER BY clauses and index them.
🔄 The Iterative Process of Design
Database design is rarely linear. It is an iterative process. You might start with an ERD, normalize it, realize performance is an issue, denormalize slightly, and then revisit the ERD to ensure relationships are still accurate.
🔄 Refinement Steps
- Review Requirements: Do new features require new tables?
- Query Analysis: Look at the slowest queries and identify bottlenecks.
- Constraint Checking: Ensure foreign keys are properly defined to prevent orphaned records.
- Documentation: Keep your ERD updated. An outdated diagram is worse than no diagram.
📈 Performance Considerations
Normalization primarily addresses data integrity. Performance is a separate concern that often requires tuning. However, the two are linked.
🚀 Join Complexity
Highly normalized databases require more JOIN operations to retrieve related data. Modern database engines are very good at optimizing joins, but excessive joins can still impact latency.
📦 Storage Engine
Different storage engines handle data differently. Some favor row-based storage, while others favor column-based storage. Your normalization strategy might need to adapt based on the underlying engine.
🔒 Constraints and Triggers
Enforcing normalization rules via constraints (like Foreign Keys) ensures data quality. However, heavy use of triggers for validation can slow down write operations. Use them wisely.
🧩 Real-World Example: E-Commerce Order System
Let us look at a slightly more complex scenario: an online store.
Initial ERD Concept
At first, you might have an Order table that includes product names, prices, and customer details. This is the classic “flat file” approach.
Normalized Approach
To fix this, we split the data:
- Customers Table: Stores customer details (Name, Address, Email).
- Products Table: Stores product details (Name, Price, Stock).
- Orders Table: Stores the transaction (CustomerID, OrderDate, Total).
- OrderItems Table: Links Orders and Products (OrderID, ProductID, Quantity, PriceAtTime).
This structure allows us to:
- Update a product price in one place (the Products table).
- Track historical prices in the OrderItems table (snapshotting).
- Ensure a customer cannot be deleted if they have open orders (via Foreign Keys).
🎯 Best Practices Checklist
Before deploying your schema, run through this checklist to ensure quality.
- ✅ Primary Keys: Every table has a unique identifier.
- ✅ Foreign Keys: Relationships are explicitly defined.
- ✅ Nullability: Columns are marked as
NOT NULLwhere appropriate. - ✅ Data Types: Use the most specific data type possible.
- ✅ Naming Conventions: Use consistent, clear names for tables and columns.
- ✅ Documentation: The ERD matches the physical schema.
- ✅ Backup Strategy: Consider how the schema impacts backup and restore times.
🔮 The Future of Database Design
As technology evolves, the core principles of normalization and ERDs remain relevant. While NoSQL databases offer flexibility, the relational model still dominates transactional systems. Understanding the fundamentals allows you to adapt to new technologies without losing the discipline of data modeling.
Cloud databases introduce new dimensions, such as sharding and partitioning. However, the logical structure you design using ERDs and normalization remains the blueprint for how that data is distributed and accessed.
📝 Summary of Key Takeaways
Designing efficient database structures is a balance between structure and flexibility. Here is what you should remember:
- ERDs are Visual Guides: They map the relationships before you build.
- Normalization is Structural: It organizes data to reduce redundancy.
- 3NF is the Goal: Aim for Third Normal Form for most transactional systems.
- Denormalize Wisely: Only add redundancy when performance demands it.
- Iterate: Design is never finished; it evolves with the application.
By combining the visual clarity of Entity Relationship Diagrams with the rigorous rules of Normalization, you create a data foundation that is both reliable and scalable. This approach ensures that your database can grow with your application, handling complexity without breaking integrity.
Start with a clean ERD. Apply normalization rules step-by-step. Test your queries. Refine your schema. And always prioritize data integrity over speed in the early stages.