











Tworzenie niezawodnego sklepu internetowego wymaga więcej niż tylko interfejsu front-end. Tłem każdego pomyślnego rynku cyfrowego jest architektura danych. Diagram relacji encji (ERD) pełni rolę projektu, jak informacje są przechowywane, powiązane i pobierane. Przy projektowaniu z myślą o skalowalności złożoność znacznie rośnie. Należy zrównoważyć integralność danych z wydajnością, zapewniając, że każda transakcja przetwarza się płynnie nawet pod dużym obciążeniem.
Ten przewodnik omawia kluczowe elementy projektowania bazy danych e-commerce. Przeanalizujemy podstawowe encje, ich relacje oraz wzorce niezbędne do obsługi dużych objętości ruchu. Przestrzegając tych zasad strukturalnych, możesz stworzyć system, który pozostaje stabilny wraz ze wzrostem liczby klientów. Nacisk kładziony jest na projektowanie logiczne, normalizację oraz strategie zapobiegające zatorom jeszcze przed ich wystąpieniem.
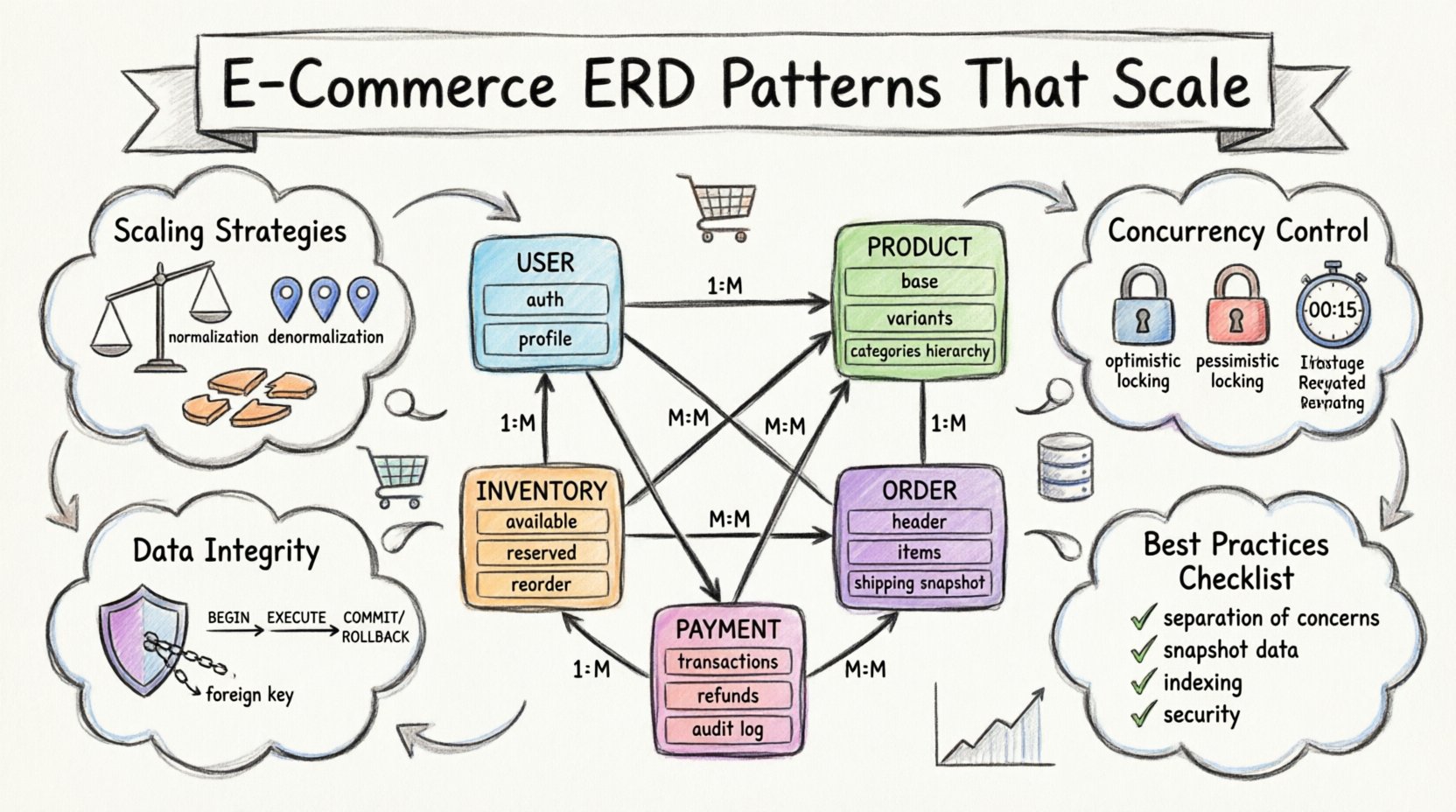
Podstawowe encje i kluczowe relacje 🏗️
Każda platforma e-commerce zaczyna się od podstawowych punktów danych definiujących działalność biznesową. Obejmują one, kim są klienci, co kupują oraz jak są kategoryzowane towary. Projektowanie tych podstawowych tabel decyduje o elastyczności całego systemu.
1. Encja Użytkownika
Tabela użytkownika jest punktem wejścia do uwierzytelniania i zarządzania profilami. Jednak rozdzielenie danych uwierzytelniających od szczegółów profilu użytkownika jest powszechnym wzorcem. To rozdzielenie pozwala na aktualizacje bezpieczeństwa bez zakłócania szerokiej struktury danych użytkownika.
- Dane uwierzytelniania:Przechowuje dane logowania, tokeny sesji oraz stan konta. Dane te wymagają wysokiej ochrony i minimalnego narażenia.
- Dane profilu:Zawiera imiona, dane kontaktowe oraz preferencje dostawy. Dane te są częściej aktualizowane.
- Relacje:Między użytkownikami a ich historią zamówień istnieje relacja jeden do wielu. Każdy użytkownik może mieć wiele zamówień, ale każde zamówienie należy do dokładnie jednego użytkownika.
W tym etapie ważne jest uwzględnienie przepisów o prywatności. Przechowywanie informacji osobistych (PII) wymaga specjalnej obsługi. Szyfrowanie danych w spoczynku i ściśle kontrolowany dostęp to standardowe praktyki dla tej encji.
2. Katalog produktów
Zarządzanie produktami jest często najbardziej złożonym elementem schematu e-commerce. Jedno fizyczne przedmiot może występować w wielu wariantach, takich jak rozmiar lub kolor. Wymaga to elastycznej struktury, która nie wymaga ciągłych zmian schematu.
- Tabela podstawowa produktów:Przechowuje ogólne informacje takie jak tytuł, opis i podstawowa cena.
- Tabela wariantów:Przechowuje konkretne atrybuty takie jak SKU, kolor, rozmiar i indywidualne ceny.
- Tabela kategorii:Definiuje hierarchię. Kategorie mogą być zagnieżdżone, co wymaga relacji samodzielnej lub strategii enumeracji ścieżki.
Tutaj często rozważa się denormalizację. Choć normalizacja zmniejsza nadmiarowość, odczytywanie danych do strony listy produktów wymaga łączenia wielu tabel. W sytuacjach o dużym ruchu, buforowanie połączonych danych lub denormalizacja wybranych pól może poprawić szybkość zapytań.
3. Inwentaryzacja i zarządzanie zapasami
Śledzenie poziomu zapasów jest kluczowe, aby zapobiec nadmiarowemu sprzedawaniu. Tabela inwentaryzacji musi być bezpośrednio powiązana z wariantami produktów. Powinna przechowywać aktualną ilość dostępnych produktów, ilość zarezerwowaną oraz całkowitą pojemność.
- Dostępne zapasy:Liczba produktów gotowych do natychmiastowej zakupu.
- Zarezerwowane zapasy:Przedmioty przechowywane w koszyku klienta podczas procesu zakupu.
- Punkt ponownego zamówienia: Próg, który wywołuje ostrzeżenia o uzupełnieniu zapasów.
Zgodność (konkurencja) to tutaj duży wyzwanie. Jeśli dwóch użytkowników spróbuje kupić ostatni przedmiot jednocześnie, system musi zapobiegać powodzeniu obu operacji. Zazwyczaj wymaga to transakcji bazodanych, które blokują konkretny wiersz zapasów podczas procesu aktualizacji.
Architektura transakcyjna i przetwarzanie zamówień 🛒
Cykl życia zamówienia to serce platformy. Reprezentuje przepływ wartości od klienta do sprzedawcy. Projekt bazy danych musi wspierać zmiany stanu od koszyka do realizacji.
Struktura jednostki zamówienia
Rekord zamówienia to zdjęcie transakcji w konkretnym momencie. Nie powinien po prostu odwoływać się do aktualnej ceny produktu. Jeśli cena zmieni się po złożeniu zamówienia, rekord historyczny musi pozostać dokładny.
- Nagłówek zamówienia: Zawiera identyfikator zamówienia, identyfikator użytkownika, łączną kwotę, podatek, koszt wysyłki oraz status zamówienia.
- Pozycje zamówienia: Tabela pośrednicząca łącząca zamówienia z produktami. Ta tabela zapisuje konkretną wersję, ilość oraz cenę w momencie zakupu.
- Adres wysyłki: Przechowywanie adresu w momencie zamówienia jest bezpieczniejsze niż łączenie z aktualnym profilem adresowym użytkownika.
Zarządzanie stanem
Zamówienia przechodzą przez różne stany. Dobrze zaprojektowane pole stanu pozwala systemowi śledzić postęp bez konieczności złożonych połączeń. Powszechne stany to:
- Oczekujące:Zamówienie utworzone, ale jeszcze nie opłacone.
- Opłacone:Płatność potwierdzona.
- W trakcie przetwarzania:Zapasy zarezerwowane i przygotowywane.
- Wysłane:Przedmiot wysłany z danymi śledzenia.
- Dostarczone:Klient otrzymał przedmiot.
- Zwrócone:Pieniądze zwrócone klientowi.
Używanie typu wyliczeniowego dla stanu zapewnia spójność danych. Zapobiega błędom literów, które mogłyby uszkodzić skrypty automatyzacji oparte na konkretnych wartościach stanu.
Płatności i rekordy finansowe 💳
Dane finansowe wymagają najwyższej dokładności. Nie możesz polegać wyłącznie na standardowej logice aplikacji w kwestii pieniędzy. Baza danych musi zapisywać transakcję finansową jako odrębne zdarzenie.
- Transakcje płatności: Każda próba płatności powinna tworzyć rekord. Obejmuje to odpowiedź bramki, użyty sposób oraz ostateczny wynik.
- Zwroty:Zwrot to osobna transakcja powiązana z oryginalną płatnością. Nie powinien po prostu zerować oryginalnego rekordu.
- Obliczanie podatków:Stawki podatków różnią się w zależności od lokalizacji. Przechowywanie kwoty naliczonego podatku na każdy element zamówienia zapewnia audytowalność.
Rejestrowanie audytowe jest tu kluczowe. Każda zmiana w rekordzie finansowym powinna być zapisywana z znacznikiem czasu i identyfikatorem użytkownika wykonującego działanie. Zapewnia to ślad do rozwiązywania sporów i audytu wewnętrznych.
Strategie skalowania dla dużych objętości 📈
Wraz ze wzrostem ruchu baza danych staje się węzłem zatkania. Standardowe skalowanie obejmuje skalowanie pionowe (dodawanie mocy do jednego serwera), ale ma swoje limity. Skalowanie poziome (dodawanie więcej serwerów) wymaga dokładnego planowania dystrybucji danych.
1. Normalizacja wobec denormalizacji
Normalizacja zmniejsza powielanie danych. Jest standardem dla integralności transakcyjnej. Jednak złożone zapytania łączące wiele tabel mogą stać się wolne wraz ze wzrostem objętości danych.
| Strategia | Zalety | Wady |
|---|---|---|
| Normalizacja | Spójność danych, mniejsze zużycie pamięci | Złożone zapytania, wolniejsze odczyty |
| Denormalizacja | Szybsze odczyty, prostsze zapytania | Zmiana danych, złożoność aktualizacji |
W e-commerce często najlepszym rozwiązaniem jest hybrydowy podejście. Zachowaj podstawowe tabele transakcyjne w formie normalnej, aby zapewnić integralność. Twórz tabele denormalizowane lub osobne widoki do celów raportowania i wyszukiwania. Pozwala to na szybkie przeglądanie produktów bez kompromitowania dokładności przetwarzania zamówień.
2. Strategie indeksowania
Indeksy są kluczowe dla wydajności. Pozwalają bazie danych znajdować wiersze bez przeszukiwania całej tabeli. Jednak zbyt wiele indeksów spowalnia operacje zapisu.
- Klucze główne: Zawsze indeksowane. Używane do bezpośrednich wyszukiwań po ID.
- Klucze obce: Często indeksowane, aby przyspieszyć łączenie powiązanych tabel.
- Indeksy złożone: Użyteczne dla zapytań filtrowanych według wielu kolumn, takich jak stan i data.
- Indeksy pełnotekstowe: niezbędne dla funkcjonalności wyszukiwania produktów.
Regularnie przeglądaj plany wykonania zapytań. Jeśli zapytanie nie wykorzystuje indeksu, baza danych może wykonywać pełne skanowanie tabeli, co pogarsza wydajność wraz ze wzrostem rozmiaru zestawu danych.
3. Partycjonowanie i rozmieszczanie danych
Gdy pojedyncza tabela staje się zbyt duża, partycjonowanie dzieli ją na mniejsze, łatwiejsze w zarządzaniu fragmenty. Często odbywa się to według daty lub zakresu ID.
- Partycjonowanie zakresowe: Podział zamówień według roku lub miesiąca. Pozwala to przechowywać najnowsze dane na szybszym nośniku, a stare dane archiwizować.
- Partycjonowanie haszowe: Rozdzielanie danych między wiele serwerów na podstawie hasza ID. Pozwala to równomiernie rozłożyć obciążenie.
Rozmieszczanie danych (sharding) dalszy krok w rozdzielaniu danych między wiele fizycznych serwerów. Wymaga to, by aplikacja znała, który fragment zawiera dane. Jest to skomplikowane decyzje architektoniczne, które najlepiej zrealizować po wyczerpaniu możliwości skalowania pionowego.
Integralność danych i ograniczenia 🔒
Bazy danych relacyjnych oferują potężne ograniczenia do utrzymania jakości danych. Opieranie się na kodzie aplikacji do wymuszania reguł jest ryzykowne, ponieważ kod może zawierać błędy. Ograniczenia bazy danych zapewniają zabezpieczenie.
1. Integralność referencyjna
Ograniczenia kluczy obcych zapewniają, że zamówienie zawsze odnosi się do ważnego użytkownika i produktu. Jeśli produkt zostanie usunięty, bazę danych można skonfigurować tak, aby zapobiegać usuwaniu lub propagować działanie do zależnych rekordów. W e-commerce zapobieganie usuwaniu produktów z istniejącymi zamówieniami zwykle jest bezpieczniejszym rozwiązaniem.
2. Atomowość transakcji
Transakcja grupuje wiele operacji w jedną jednostkę. Albo wszystkie operacje powiodą się, albo żadna nie powiedzie się. Jest to kluczowe dla aktualizacji zapasów. Gdy zostanie złożone zamówienie, zapasy muszą się zmniejszyć. Jeśli aktualizacja zapasów nie powiedzie się, rekord zamówienia nie powinien zostać utworzony.
- Rozpocznij transakcję: Zablokowuje odpowiednie zasoby.
- Wykonaj aktualizacje: Wykonaj niezbędne zapisy.
- Zatwierdź: Robi zmiany trwałe.
- Wycofaj: Cofa zmiany w przypadku wystąpienia błędu.
3. Ograniczenia unikalności
Ograniczenia unikalności zapobiegają powtórzonym wpisom. Jest to przydatne dla adresów e-mail w tabeli użytkowników lub kodów SKU w tabeli produktów. Zapobiega to przypadkowemu tworzeniu duplikatów kont lub konfliktujących pozycji w zapasach.
Obsługa wysokiej konkurencji ⚡
Wyprzedaże flash i wydarzenia o wysokim ruchu tworzą warunki wyścigu. Wiele użytkowników może spróbować kupić ten sam przedmiot w dokładnie tym samym milisekundzie.
Blokada optymistyczna
Blokada optymistyczna zakłada, że konflikty są rzadkie. Polega na dodaniu numeru wersji do wiersza. Podczas aktualizacji baza danych sprawdza, czy numer wersji się zgadza. Jeśli się zmienił, aktualizacja jest odrzucana, a aplikacja musi spróbować ponownie.
Blokada pesymistyczna
Blokada pesymistyczna blokuje wiersz od razu po odczytaniu. Inne transakcje muszą czekać, aż blokada zostanie zwolniona. Gwarantuje to spójność danych, ale może zmniejszyć przepustowość podczas wysokiej konkurencji.
Rezerwacja zapasów
Aby zapobiec nadmiarowemu sprzedawaniu, rezerwuj zapasy, gdy użytkownik dodaje przedmiot do koszyka. Ustaw limit czasu dla tej rezerwacji. Jeśli użytkownik nie zakończy procesu zakupu w ciągu limitu czasu, zapasy zostaną zwolnione do dostępnej puli.
Zagadnienia związane z wyszukiwaniem i analizą 📊
Bazy danych transakcyjne nie są przeznaczone do złożonych zapytań analitycznych ani wyszukiwania pełnotekstowego. Wykonywanie ciężkich zapytań wyszukiwania na głównych tabelach zamówień lub produktów może pogorszyć wydajność dla zwykłych użytkowników.
- Silniki wyszukiwania:Użyj dedykowanego silnika wyszukiwania do odkrywania produktów. Synchronizuj dane produktów z głównej bazy danych do silnika wyszukiwania asynchronicznie.
- Magazyny analityczne:Przenieś dane historyczne do osobistego magazynu analitycznego do raportowania. Dzięki temu baza danych transakcyjna pozostaje lekka.
- Replicy odczytu:Kieruj ruch tylko do odczytu do serwerów replik. Pozwala to oddzielić obciążenie od głównego serwera zapisu.
Oddzielając operacje intensywne zapisu od operacji intensywnych odczytu, zapewnicasz, że proces zakupów pozostaje szybki, nawet gdy użytkownicy przeglądają strony lub generują raporty.
Utrzymanie i wzrost na długie lata 🔄
Projekt bazy danych nie jest statyczny. Musi ewoluować wraz z działalnością firmy. Gdy dodawane są nowe funkcje, schemat może wymagać dostosowań.
- Wersjonowanie:Śledź wersje schematu. Pozwala to na bezpieczne cofnięcie, jeśli migracja nie powiedzie się.
- Archiwizacja:Przenieś stare zamówienia do chłodnego magazynu. Dzięki temu rozmiar aktywnej tabeli pozostaje kontrolowany.
- Monitorowanie:Skonfiguruj ostrzeżenia dla wolnych zapytań, oczekiwania na blokady i zużycia przestrzeni dyskowej. Proaktywne monitorowanie zapobiega awariom.
Regularnie przeglądaj diagram ERD pod kątem rzeczywistych wzorców użytkowania. Niektóre relacje, które wydawały się dobre na papierze, mogą okazać się nieefektywne w środowisku produkcyjnym. Przygotuj się na przepisanie kodu, gdy wzorce danych znacznie się zmienią.
Podsumowanie najlepszych praktyk ✅
Projektowanie skalowalnej bazy danych e-commerce wymaga równowagi między strukturą a elastycznością. Poniższe punkty podsumowują kluczowe wnioski dotyczące budowy odpornego systemu.
- Oddzielenie odpowiedzialności:Utrzymuj dane uwierzytelniania, katalogu i transakcji osobno.
- Dane w postaci zrzutu:Przechowuj szczegóły zamówienia w momencie zakupu, a nie tylko odwołania do nich.
- Kontrola współbieżności:Używaj transakcji i blokad, aby zapobiec nadmiarowemu sprzedawaniu.
- Indeksowanie:Optymalizuj pod kątem najczęściej występujących wzorców odczytu i zapisu.
- Skalowalność: Zaprojektuj podział i rozmieszczenie danych w wczesnym etapie architektury.
- Bezpieczeństwo: Szyfruj poufne dane i stosuj surowe kontrole dostępu.
Przestrzegając tych wzorców, tworzysz fundament wspierający rozwój. Baza danych staje się stabilnym silnikiem, który napędza działalność bez potrzeby ciągłych napraw awaryjnych. Najpierw skup się na integralności danych, a następnie optymalizuj pod kątem szybkości. Powolny system jest lepszy niż niepoprawny.