











Tworzenie systemu bazy danych to coś w rodzaju budowy fundamentu dla wieżowca. Jeśli projekt jest błędny, konstrukcja w końcu pęka pod ciśnieniem. Diagram relacji encji (ERD) to właśnie ten projekt. Określa, jak dane są połączone, przepływają i utrwalają się w Twojej aplikacji. Gdy liczba użytkowników rośnie, a objętość danych eksploduje, statyczny projekt często staje się wąskim gardłem. Aby zapewnić długowieczność, należy od samego początku stosować zasady projektowania skalowalnych diagramów ERD. Ten przewodnik omawia strategie techniczne potrzebne do budowy systemów, które wytrzymają.
Zrozumienie podstaw modelowania danych 🧱
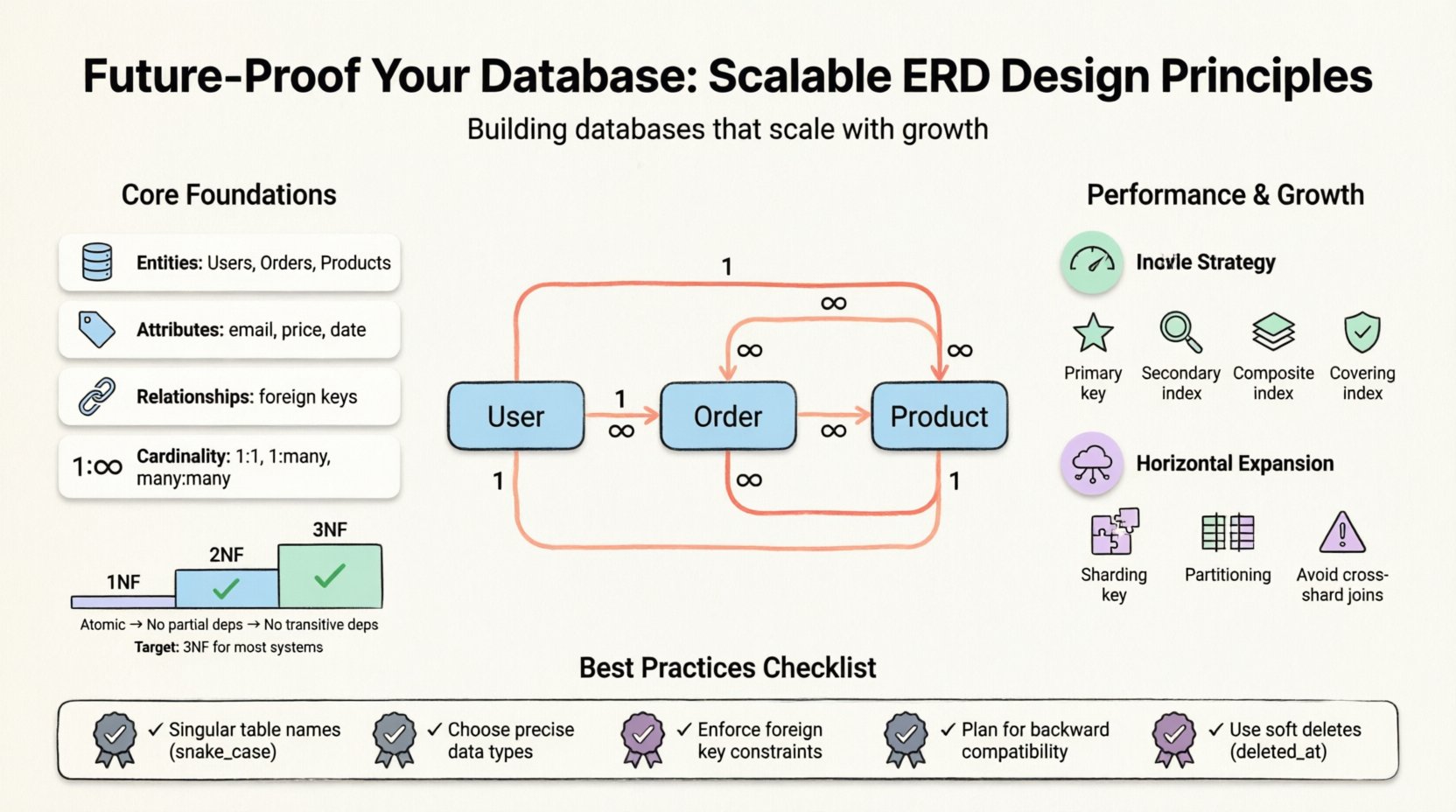
Zanim przejdziesz do konkretnych strategii, koniecznie musisz zrozumieć, co reprezentuje diagram ERD. Wizualizuje on strukturę logiczną bazy danych. Mapuje encje (tabelki), atrybuty (kolumny) oraz relacje (klucze). Dobrze zaprojektowany model równoważy integralność danych z wydajnością. Jednak „najlepsze praktyki” różnią się w zależności od obciążenia. Aplikacja z dużym obciążeniem odczytu wymaga innej optymalizacji niż system transakcyjny z dużym obciążeniem zapisu.
Główne składniki to:
- Encje: Podstawowe obiekty, takie jak Użytkownicy, Zamówienia lub Produkty.
- Atrybuty: Właściwości definiujące encję, takie jak adresy e-mail lub ceny.
- Relacje: Jak encje się ze sobą współdziałają, często definiowane za pomocą kluczy obcych.
- Moc zbioru (cardinality): Relacja liczbowo między encjami (jeden do jednego, jeden do wielu, wiele do wielu).
Normalizacja: Równowaga między nadmiarowością a szybkością ⚖️
Normalizacja to proces organizowania danych w celu zmniejszenia nadmiarowości i poprawy integralności. Choć często traktowana jest jako ścisła zasada, to jednak kompromis. Wysoka normalizacja minimalizuje anomalie, ale może zwiększać złożoność zapytań dzięki łączeniom. Niska normalizacja (denormalizacja) przyspiesza odczyty, ale zwiększa ryzyko niezgodności danych.
Poziomy normalizacji
Zrozumienie standardowych form pomaga Ci zdecydować, gdzie się zatrzymać. Każda forma rozwiązuje konkretne anomalie danych.
- Pierwsza forma normalna (1NF): Zapewnia atomowość. Każda kolumna musi zawierać niepodzielne wartości. Brak powtarzających się grup lub tablic w jednym polu.
- Druga forma normalna (2NF): Buduje na 1NF. Wszystkie atrybuty niekluczowe muszą zależeć od całego klucza głównego, a nie tylko jego części. Usuwa zależności częściowe.
- Trzecia forma normalna (3NF): Buduje na 2NF. Atrybuty niekluczowe nie mogą zależeć od innych atrybutów niekluczowych. Usuwa zależności przechodnie.
- Forma normalna Boyce’a-Codda (BCNF): Bardziej rygorystyczna wersja 3NF. Rozwiązuje przypadki, gdy determinaty nie są kluczami kandydującymi.
Dla większości skalowalnych systemów osiągnięcie 3NF jest standardowym celem. Idąc dalej, często uzyskuje się malejące zyski przy jednoczesnym zwiększeniu obciążenia utrzymania. Jednak w systemach skupionych na analizie często stosuje się kontrolowaną denormalizację.
Tabela kompromisów przy normalizacji
| Poziom normalizacji | Główna zaleta | Główna wada |
|---|---|---|
| 1NF | Zapis danych atomowych | Brak |
| 2NF | Usunięcie zależności częściowych | Wymagane więcej łączeń |
| 3NF | Usunięcie zależności przechodnich | Zwiększona złożoność łączeń |
| Nienormalizowane | Szybsze zapytania odczytowe | Zmieszanie danych i anomalie aktualizacji |
Projektowanie schematu z myślą o rozwoju i elastyczności 📈
Projektowanie tylko na teraźniejszość jest niewystarczające. Musisz przewidywać przyszłą ewolucję schematu. Sztywne struktury ulegają uszkodzeniu, gdy zmienia się logika biznesowa. Elastyczny projekt pozwala na rozwój bez konieczności pełnej migracji systemu.
1. Zasady i standardy nazewnictwa
Spójność jest kluczowa dla utrzymywalności. Chaotyczny schemat nazewnictwa prowadzi do zamieszania i błędów. Ustal standard na wczesnym etapie i stosuj go we wszystkich zespołach.
- Używaj nazw liczby pojedynczej:Tabele powinny reprezentować pojedynczy obiekt (np.
użytkownik, a nieużytkownicy). - Spójne znaczniki:Używaj snake_case dla nazw tabel i kolumn, aby zapewnić zgodność między różnymi systemami operacyjnymi i narzędziami.
- Przedrostki dla precyzji:Używaj przedrostków takich jak
fk_dla kluczy obcych lubidx_dla indeksów, aby ich cel był jasny. - Unikaj słów kluczowych: Nigdy nie używaj słów kluczowych takich jak
order,group, lubselectjako nazwy kolumn.
2. Typy danych i precyzja
Wybór poprawnego typu danych wpływa na przestrzeń magazynowania i szybkość zapytań. Zbyt ogólne typy zużywają przestrzeń i spowalniają przetwarzanie.
- Liczby całkowite: Użyj
TINYINTdo flag (0-1) lub małych liczb. UżyjBIGINTtylko wtedy, gdy przewidujesz ogromny zakres danych. - Ciągi znaków: Unikaj
TEXTdla krótkich wartości. UżyjVARCHARz określoną długością, aby zaoszczędzić miejsce i umożliwić indeksowanie. - Daty: Użyj
TIMESTAMPdo konkretnych chwil iDATEtylko do dat kalendarzowych. Zawsze przechowuj w formacie UTC, aby uniknąć zamieszania z strefami czasowymi. - Liczby dziesiętne: Dla danych finansowych używaj liczb dziesiętnych o stałej liczbie miejsc po przecinku zamiast liczb zmiennoprzecinkowych, aby uniknąć błędów zaokrąglenia.
Zarządzanie relacjami i licznością 🔗
Sposób, w jaki encje są ze sobą powiązane, określa integralność danych. Źle zarządzane relacje prowadzą do pozostawionych bez opieki rekordów i utraty danych.
1. Ograniczenia kluczy obcych
Klucze obce zapewniają integralność referencyjną. Gwarantują, że rekord w jednej tabeli nie może odwoływać się do nieistniejącego rekordu w innej. Choć niektórzy deweloperzy wyłączają te ograniczenia dla wydajności, nowoczesne silniki baz danych obsługują je efektywnie. Opieranie się na sprawdzaniu na poziomie aplikacji jest podatne na błędy.
2. Obsługa relacji wiele do wielu
Relacja wiele do wielu (np. Studenci i Kursy) nie może być bezpośrednio przedstawiona w dwóch tabelach. Wymaga tabeli pośredniej (encji asocjacyjnej).
- Utwórz nową tabelę zawierającą klucze główne obu powiązanych tabel.
- Dodaj złożony klucz główny składający się z obu kluczy obcych.
- Użyj tej tabeli do przechowywania dodatkowych atrybutów specyficznych dla relacji, takich jak daty zapisu.
3. Relacje opcjonalne vs. wymagane
Jasno określ, czy relacja jest wymagana. Wartość NULLw kolumnie klucza obcego wskazuje na relację opcjonalną. Ta decyzja wpływa na logikę walidacji na poziomie warstwy aplikacji.
Strategie indeksowania dla wydajności odczytu 🏎️
Indeksy są podstawowym mechanizmem przyspieszania pobierania danych. Jednak nie są darmowe. Każdy indeks zużywa przestrzeń dyskową i spowalnia operacje zapisu (wstawianie, aktualizacja, usuwanie).
1. Indeksy główne
Każda tabela musi mieć klucz główny. Często jest to indeks zgrupowany, co oznacza, że dane fizyczne są przechowywane w kolejności klucza. Wybierz klucz stabilny i nigdy nie aktualizowany. Klucze zastępcze (liczby całkowite zwiększane automatycznie) są często lepsze niż klucze naturalne (np. adresy e-mail) pod względem wydajności.
2. Indeksy pomocnicze
Używaj indeksów pomocniczych do optymalizacji zapytań, które filtrowane lub sortowane na kolumnach niegłównych. Typowe scenariusze to:
- Wyszukiwanie według adresu e-mail.
- Filtrowanie według statusu lub kategorii.
- Sortowanie wyników według daty.
3. Indeksy złożone
Gdy wykonywane są zapytania na wielu kolumnach, indeks złożony może być bardziej wydajny niż osobne indeksy jednokolumnowe. Kolejność kolumn w indeksie ma znaczenie. Umieść najbardziej selektywną kolumnę na początku.
4. Indeksy pokrywające
Indeks pokrywający zawiera wszystkie kolumny potrzebne do spełnienia zapytania. Pozwala bazie danych pobrać dane bezpośrednio z indeksu, nie odwadzając się do głównej tabeli, znacznie zmniejszając I/O.
Projektowanie z myślą o skalowaniu poziomym 🌐
Skalowanie pionowe (dodawanie mocy do jednego serwera) ma ograniczenia. W końcu musisz rozdzielić dane między wiele węzłów. Projektowanie ERD musi uwzględniać tę rzeczywistość.
1. Klucze shardingowe
Sharding polega na podziale danych między wiele baz danych. Wybór klucza shardingowego jest kluczowy. Powinien być często używany w zapytaniach, aby zapewnić lokalizację danych. Jeśli shardujesz według “user_id, możesz łatwo zapytać o wszystkie dane dla tego użytkownika na jednym węźle.
- Dobre klucze shardingowe: Wysoka liczba unikalnych wartości, często używane w zapytaniach.
- Złe klucze shardingowe: Niska liczba unikalnych wartości (np.
country_code) lub rzadko używane.
2. Unikanie łączeń między shardami
Łączenia między różnymi shardami są kosztowne i skomplikowane. Projektuj swoją strukturę danych tak, aby minimalizować potrzebę ich stosowania. Jeśli potrzebujesz danych z dwóch encji, które mogą znajdować się na różnych shardach, rozważ znormalizowanie danych. Przechowuj niezbędne dane klucza obcego bezpośrednio w tabeli, aby uniknąć łączenia.
3. Partycjonowanie
Partycjonowanie dzieli dużą tabelę na mniejsze, łatwiejsze w zarządzaniu części. Można to zrobić według zakresu (daty), listy (kategorie) lub haszowania. Poprawia ono utrzymanie i wydajność zapytań bez znaczącej zmiany logiki aplikacji.
Ewolucja schematu i migracja 🔄
Wymagania się zmieniają. Nowe funkcje wymagają nowych kolumn. Stare funkcje są wycofywane. Solidny ERD pozwala na zmiany bez naruszania istniejącej funkcjonalności.
1. Zgodność wsteczna
Podczas dodawania nowych funkcji upewnij się, że stare klienty nadal działają. Najpierw dodaj nowe kolumny jako nullowalne. Wypełniaj je stopniowo. Nie usuwaj kolumn od razu; oznacz je jako przestarzałe i zachowaj je przez okres migracji.
2. Wersjonowanie modeli danych
Śledź wersje schematu. Pozwala to na cofnięcie zmian, jeśli migracja spowoduje krytyczne błędy. Używaj skryptów migracji, które są idempotentne, czyli mogą być uruchamiane wielokrotnie bez powodowania błędów.
3. Obsługa migracji danych
Przenoszenie dużych objętości danych wymaga dokładnego planowania. Duże blokady mogą zablokować ruch produkcyjny. Wykonuj migracje w okresach niskiego ruchu lub, jeśli to możliwe, stosuj strategie wdrażania typu blue-green.
Typowe pułapki do uniknięcia ⚠️
Nawet doświadczeni architekci popełniają błędy. Znajomość typowych błędów pomaga im uniknąć.
- Zbyt duża złożoność projektowa: Projektowanie pod skalę, której jeszcze nie masz. Jeśli zaczynasz, zachowaj prostotę. Złożoność zwiększa koszty i ryzyko.
- Ignorowanie miękkich usuwań: Zawsze unikaj natychmiastowego trwałego usuwania wrażliwych rekordów. Użyj pola
deleted_atzamiast tego. Zapewnia to zachowanie śladów audytu i możliwość odzyskania danych. - Konflikty nazw: Używanie tej samej nazwy dla tabeli i kolumny powoduje niejednoznaczność. Przestrzegaj zasady pojedynczej formy tabeli.
- Brak ograniczeń: Opieranie się wyłącznie na logice aplikacji w celu zapewnienia reguł biznesowych prowadzi do zanieczyszczenia danych. Zastosuj ograniczenia na poziomie bazy danych.
- Ignorowanie bezpieczeństwa: Projekt musi zawierać pola do kontroli dostępu. Upewnij się, że dostęp oparty na rolach jest wspierany w fazie projektowania schematu.
Ostateczne rozważania dotyczące trwałości 🏁
Tworzenie skalowalnej bazy danych to ciągły proces. Wymaga on monitorowania, analizy i dostosowywania. Żaden projekt nie jest idealny od razu. Celem jest stworzenie fundamentu, który łatwo można modyfikować.
Regularnie audytuj swoje zapytania. Identyfikuj powolne operacje i optymalizuj podstawowy schemat. Używaj narzędzi profilowania, aby zrozumieć, jak dostęp do danych. Ten cykl zwrotny zapewnia, że architektura pozostaje efektywna w miarę wzrostu danych.
Pamiętaj, że technologia się rozwija. Pojawiają się nowe silniki przechowywania danych i języki zapytań. Elastyczny schemat lepiej dopasowuje się do tych zmian niż sztywny. Skup się na podstawowych relacjach i integralności danych. Te pozostają stałe, nawet gdy zmieniają się narzędzia.
Przestrzegając tych zasad, budujesz systemy odpornościowe. Szybko radzą sobie z rozwojem i utrzymują wydajność pod obciążeniem. To właśnie jest esencja przyszłościowego projektowania infrastruktury bazy danych.