










Projektowanie wytrzymały schematów baz danych wymaga więcej niż tylko wymieniania tabel i kolumn. Wymaga głębokiego zrozumienia, jak istoty są ze sobą powiązane. Jednym z najpotężniejszych, a zarazem złożonych pojęć w diagramach związków encji (ERD) jest dziedziczenie. Ten mechanizm pozwala nam modelować hierarchie świata rzeczywistego, w których obiekty dzielą wspólne cechy, ale mają również unikalne atrybuty. W kontekście projektowania baz danych oznacza to nadtypy i podtypy. 🧩
Gdy modelujemy dziedziczenie, w istocie zapisujemy relację „jest rodzajem”. Na przykład, Pojezdzia jest rodzajem Produktu, a Samochód jest rodzajem Pojezdzia. Ta hierarchia pozwala nam ponownie wykorzystywać atrybuty na wyższych poziomach, jednocześnie definiując konkretne zachowania lub dane na niższych poziomach. Zrozumienie sposobu implementacji tego w bazie danych relacyjnej jest kluczowe dla integralności danych i wydajności zapytań. 🗄️
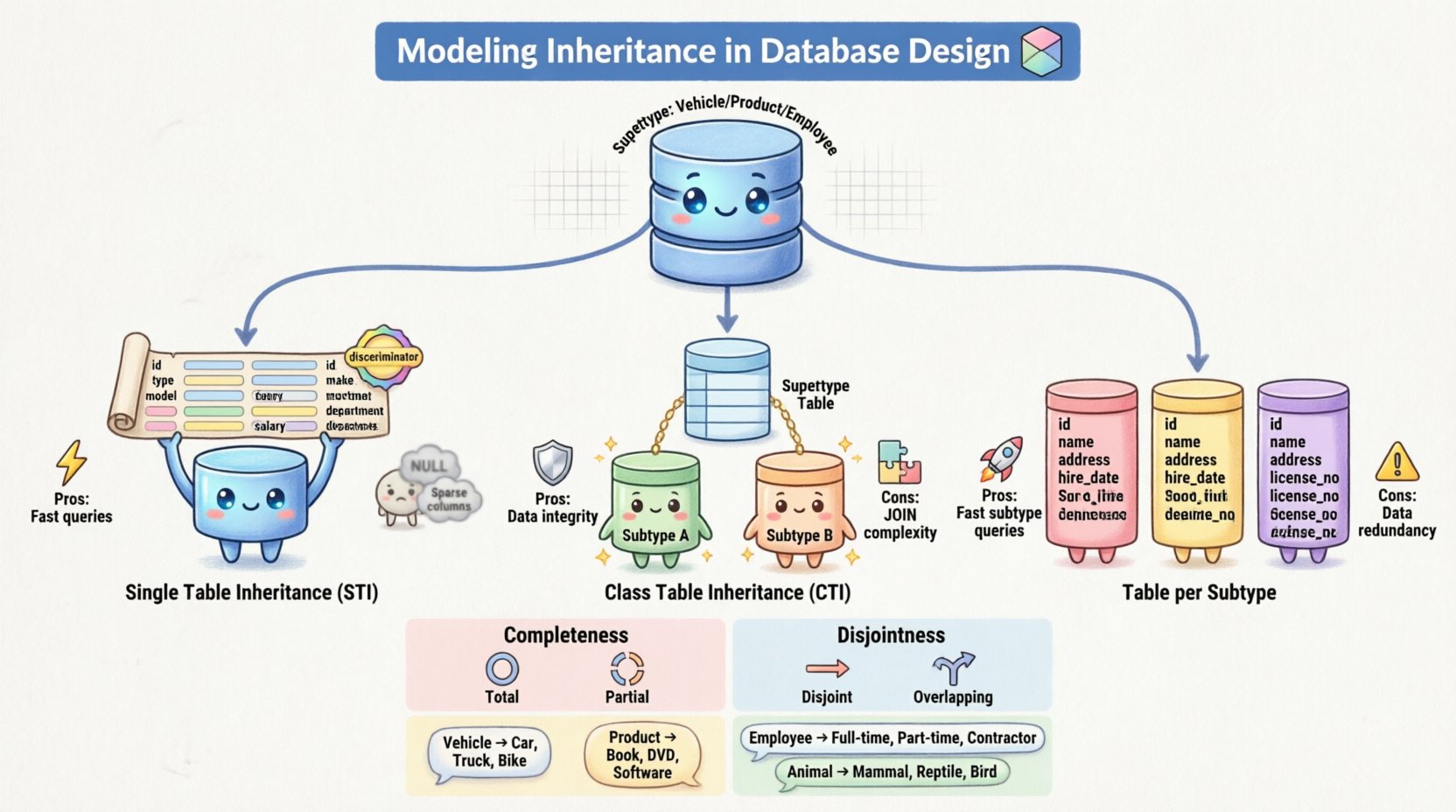
🔑 Kluczowe pojęcia: nadtypy i podtypy
Zanim przejdziemy do implementacji, musimy jasno zdefiniować terminologię. Dziedziczenie w modelowaniu baz danych nie dotyczy wyłącznie kodu; dotyczy reprezentacji strukturalnej danych.
- Nadtyp: Jest to encja nadrzędna. Zawiera atrybuty wspólne dla wszystkich powiązanych encji. Reprezentuje ogólną kategorię. Na przykład, Pracownik może być nadtypem.
- Podtyp: Są to encje potomne. Dziedziczą atrybuty z nadtypu, ale mogą również mieć własne unikalne atrybuty. Przykłady to Menadżer lub Programista.
- Kategoria encji: Nadtyp czasem nazywany jest kategorią encji, łącząc podtypy razem.
- Rozróżnienie: Pewien atrybut wewnątrz nadtypu, który identyfikuje, do którego podtypu należy dany egzemplarz. Często stosowany w implementacjach fizycznych.
Relacja między nadtypem a podtypem jest ściśle określona. Każdy egzemplarz podtypu musi również być egzemplarzem nadtypu. Jednak nie każdy egzemplarz nadtypu musi być egzemplarzem konkretnego podtypu. Ta różnica jest kluczowa dla dokładności modelowania danych. ✅
📊 Strategie implementacji
Przekształcanie modelu logicznego ERD w fizyczny schemat bazy danych wymaga określonych strategii mapowania. Istnieją trzy główne podejścia stosowane do reprezentowania dziedziczenia w systemach relacyjnych. Każde z nich ma kompromisy dotyczące przechowywania danych, szybkości pobierania oraz integralności danych. 🛠️
1. Dziedziczenie jednej tabeli (STI)
W tym podejściu wszystkie atrybuty typu nadrzędnego i wszystkie typy pochodne są łączone w jedną tabelę. Tabela zawiera kolumny dla każdego atrybutu zdefiniowanego w całej hierarchii. Aby odróżnić wiersze należące do różnych typów pochodnych, dodawana jest kolumna rozróżnieniowa.
- Zalety: Bardzo skuteczne przy odczytywaniu danych. Prosta
SELECTpobiera wszystkie informacje bez skomplikowanych połączeń. - Wady: Tabela może stać się bardzo szeroka z wieloma
NULLwartościami dla atrybutów, które nie mają zastosowania w konkretnych typach pochodnych. Może również utrudniać aktualizacje, jeśli zmienią się ograniczenia specyficzne dla typu pochodnego.
2. Dziedziczenie tabeli klasy (CTI)
W tym przypadku typ nadrzędny i każdy typ pochodny są mapowane na osobne tabele. Tabela typu nadrzędnego zawiera wspólne atrybuty oraz klucz główny. Każda tabela typu pochodnego zawiera unikalne atrybuty oraz klucz obcy łączący się z kluczem głównym typu nadrzędnego.
- Zalety: Wysoka normalizacja. Brak
NULLwartości dla atrybutów nieodnoszących się do danej sytuacji. Silnie zapewnia integralność referencyjną. - Wady: Pobieranie danych wymaga wielu operacji
JOINoperacji, co może wpływać na wydajność na dużych zestawach danych. Zwiększa również złożoność operacjiINSERTponieważ dane muszą być zapisane w wielu tabelach.
3. Tabela na typ pochodny (dziedziczenie tabel konkretnej postaci)
To podejście tworzy tabelę dla każdego typu pochodnego, w tym typu nadrzędnego. Jednak każda tabela typu pochodnego zawiera kopię atrybutów typu nadrzędnego. Nie ma bezpośredniego połączenia z centralną tabelą typu nadrzędnego.
- Zalety: Dostęp do konkretnego typu pochodnego jest bardzo szybki, ponieważ wszystkie dane znajdują się w jednym miejscu. Unika problemu
NULLproblemu STI. - Wady: Nadmiarowość danych. Jeśli atrybut wspólny zmieni się w typie nadrzędnym, musi zostać zaktualizowany w każdej tabeli typu pochodnego. Zwiększa to ryzyko niezgodności danych.
⚖️ Ograniczenia dziedziczenia
Nie wszystkie relacje dziedziczenia są takie same. Musimy zdefiniować ograniczenia regulujące sposób, w jaki instancje są powiązane z ich typami. Te ograniczenia zapewniają, że dane pozostają logiczne i spójne. 📝
Ograniczenie zupełności
To ograniczenie określa, czy każda instancja typu nadrzędnego musi należeć do jakiegoś typu pochodnego.
- Pełne: Każda instancja typu nadrzędnego musi należeć do co najmniej jednego typu pochodnego. Nie ma „ogólnych” instancji. Na przykład każdaZwierzę musi być alboMłode alboPtak.
- Częściowe: Instancja typu nadrzędnego nie musi koniecznie należeć do żadnego typu pochodnego. Może istnieć jako ogólna jednostka. Jest to częste, gdy hierarchia służy kategoryzacji, a nie ściślej klasyfikacji.
Ograniczenie rozłączności
To ograniczenie określa, czy instancja może jednocześnie należeć do wielu typów pochodnych.
- Rozłączne: Instancja może należeć tylko do jednego typu pochodnego. Nie może być jednocześnieMenadżer iProgramista w tym samym modelu.
- Nakładanie się: Instancja może należeć do więcej niż jednego typu pochodnego. Pozwala to na złożone role, w którychPracownik może mieć wiele stanowisk lub kategorii.
Połączenie tych ograniczeń prowadzi do czterech różnych scenariuszy modelowania. Zrozumienie, który scenariusz pasuje do logiki biznesowej, jest kluczowe przed tworzeniem schematu. 🧠
| Typ ograniczenia | Definicja | Przykładowy scenariusz |
|---|---|---|
| Rozłączne + Pełne | Tylko jedna podtyp, brak ogólnych wystąpień | Status zamówienia: Oczekujące, Wysłane, Dostarczone |
| Rozłączne + Częściowe | Tylko jedna podtyp, opcjonalna podtyp | Klient: VIP lub Zwykły (niektórzy nie są żadnym z nich) |
| Przecięcie + Pełne | Dopuszczalne wiele podtypów, musi należeć do jednego | Rola użytkownika: Administrator i Redaktor (musi mieć co najmniej jedną) |
| Przecięcie + Częściowe | Dopuszczalne wiele podtypów, opcjonalne | Produkt: Sprzedawalny, Promocyjny (może być oba lub żaden) |
🔍 Wyszukiwanie i pobieranie danych
Wybór strategii mapowania znacząco wpływa na sposób pisania zapytań. W środowisku znormalizowanym często musisz przemierzać hierarchię, aby uzyskać kompletny obraz encji. 🔎
- Pobieranie danych podtypu: Jeśli chcesz uzyskać dostęp do atrybutów specyficznych dla podtypu, musisz połączyć tabelę podtypu. Jest to standard w dziedziczeniu typu tabela klasy.
- Pobieranie danych nadtypu: Jeśli potrzebujesz wspólnych atrybutów, możesz bezpośrednio zapytać tabelę nadtypu.
- Zapytania polimorficzne: Podczas wyszukiwania wszystkich wystąpień niezależnie od podtypu, podejście jednej tabeli jest najprędkie. Jednak jeśli używasz wielu tabel, musisz użyć
UNIONoperacji lub złożonych połączeń.
Zastanów się nad skutkami wydajności. Zapytanie, które łączy pięć tabel, aby pobrać pojedynczy rekord, może być wolniejsze niż zapytanie na jednej tabeli nieznormalizowanej. Jednak tabela nieznormalizowana może naruszać zasady normalizacji, co prowadzi do anomalii aktualizacji. Zrównoważenie tych czynników jest kluczowym elementem projektowania schematu. ⚖️
🛠️ Konserwacja i ewolucja
Schematy nie są statyczne. Wymagania biznesowe się zmieniają, a zatem musi zmienić się struktura bazy danych. Modelowanie dziedziczenia oferuje elastyczność, ale wprowadza również złożoność podczas konserwacji. 🔄
Dodawanie nowych podtypów
Dodawanie nowego podtypu jest zazwyczaj proste. Tworzysz nową tabelę (w CTI) lub nową wartość w kolumnie rozróżnieniowej (w STI). Jednak musisz upewnić się, że istniejące zapytania i logika aplikacji dopasowują się do nowego typu. Nieaktualizacja kodu może prowadzić do błędów czasu wykonywania.
Modyfikowanie atrybutów nadtypu
Jeśli dodasz atrybut do nadtypu, musi on zostać odzwierciedlony we wszystkich tabelach podtypów, jeśli używasz CTI lub tabeli na podtyp. W STI dodajesz go tylko raz do jednej tabeli. Dzięki temu STI jest łatwiejsze do utrzymania przy zmianach ogólnych, ale trudniejsze przy zmianach specyficznych.
Migracja danych
Przepisywanie modelu dziedziczenia to znaczące przedsięwzięcie. Przejście od jednej tabeli do struktury znormalizowanej wymaga przeniesienia danych między wieloma tabelami. Ten proces musi być starannie zarządzany, aby uniknąć utraty danych lub ich uszkodzenia. 🚧
📈 Normalizacja i dziedziczenie
Modelowanie dziedziczenia ściśle współpracuje z normalizacją bazy danych. Celem normalizacji jest zmniejszenie nadmiarowości i poprawa integralności danych. Dziedziczenie czasem może wchodzić w konflikt z tymi celami, jeśli nie zostanie odpowiednio obsługiwane.
- Pierwsza postać normalna (1NF): Modele dziedziczenia zazwyczaj spełniają 1NF, ponieważ atrybuty są atomowe.
- Druga postać normalna (2NF): W STI tabela może zawierać atrybuty, które nie są całkowicie zależne od klucza głównego, jeśli rozpoznawacz nie jest częścią klucza. Wymaga to starannego projektowania kluczy.
- Trzecia postać normalna (3NF): W CTI rozdzielenie atrybutów na tabele podtypów często pomaga osiągnąć 3NF przez usunięcie zależności przechodnich.
Podczas projektowania nadtypów upewnij się, że wspólne atrybuty są naprawdę wspólne. Jeśli atrybut jest używany tylko przez jeden podtyp, to najprawdopodobniej nie powinien znajdować się w nadtypie. To zapobiega stworzeniu „bogatej tabeli”, która jest trudna do zapytania. 👁️
🎯 Najlepsze praktyki projektowania schematu
Aby zapewnić, że model dziedziczenia pozostaje łatwy do utrzymania i wydajny, postępuj zgodnie z tymi wskazówkami.
- Ogranicz głębokość: Unikaj głębokich hierarchii. Zazwyczaj maksymalna zalecana liczba poziomów dziedziczenia to trzy. Poza tym złożoność zapytań i utrzymania przeważa nad korzyściami.
- Używaj jasnych nazw: Nazwy powinny odzwierciedlać hierarchię.Pojazd, Samochód, Ciężarówka jest jasne.Obiekt1, Obiekt2 nie jest.
- Planuj rozwój: Przewiduj przyszłe podtypy. Jeśli oczekujesz wielu nowych podtypów, jedna tabela może stać się trudna do obsługi. Jeśli oczekujesz małej liczby, CTI może być lepsze.
- Dokumentuj ograniczenia: Jasno dokumentuj ograniczenia rozłączności i zupełności. Przyszli programiści muszą wiedzieć, czy wystąpienie może należeć do wielu podtypów.
- Strategia indeksowania: Jeśli używasz CTI, indeksuj kolumny kluczy obcych w tabelach podtypów, aby przyspieszyć łączenia. Jeśli używasz STI, indeksuj kolumnę rozróżnieniową do filtrowania.
🧪 Przypadki z życia wzięte
Spójrzmy, jak to dotyczy rzeczywistych wyzwań modelowania danych.
Przypadek 1: Zarządzanie zasobami ludzkimi
W systemie HR maszOsoba jako typ nadklasy. Podtypy toPracownik, Podwykonawca, orazStażysta. Każdy podtyp ma unikalne dane:Pracownik ma identyfikator płacowy,Podwykonawca ma stawkę rozliczeniową. TabelaOsoba przechowuje imię i adres. To dobrze pasuje do modelu dziedziczenia tabel klas.
Przypadek 2: Zarządzanie zapasami
Rozważ katalog produktów.Produkt jest typem nadklasowym. Podtypy toElektronika, Meble, orazOdzież. Elektronika ma Okres gwarancji. Odzież ma Rozmiar i Kolor. Jeśli zapytasz o wszystkie produkty z gwarancją, musisz połączyć tabelę Elektronika. To pokazuje kompromis wydajności zapytań. 🔍
Scenariusz 3: Operacje finansowe
W systemie bankowym Konto jest nadtypem. Podtypy to Osobiste, Rachunku, a Kredyt. Konto Osobiste ma stopę procentową. Konto Kredyt ma datę spłaty. Ten scenariusz często korzysta z podejścia Single Table, aby uprościć obliczanie sald dla wszystkich typów kont.
🚀 Zdjęcie wydajności
Wydajność często decyduje o wyborze strategii mapowania. Duże zbiory danych zwiększają różnice między podejściami.
- Wydajność zapisu: STI jest najszybsze przy wstawianiu, ponieważ jest jednym
WSTAWzapytaniem. CTI wymaga wieluWSTAWinstrukcji, co zwiększa obciążenie transakcji. - Wydajność odczytu: Jeśli często wykonywane są zapytania dotyczące określonych podtypów, CTI jest szybszy niż STI, ponieważ odczytujesz tylko istotne kolumny. Jeśli zapytania dotyczą wszystkich instancji, STI jest szybszy.
- Przechowywanie: STI zużywa więcej pamięci z powodu
NULLwypełnienia. CTI zużywa więcej pamięci z powodu powielonych kluczy głównych i kluczy obcych, ale mniej z powodu brakuNULLwypełnienia.
Ważne jest profilowanie aplikacji. Teoretyczna wydajność nie zawsze odpowiada rzeczywistym wzorców użycia. Testowanie przy użyciu realistycznych objętości danych to jedyna droga potwierdzenia Twojego wyboru. 📊
🛡️ Integralność danych i weryfikacja
Zachowanie integralności danych w modelu dziedziczenia wymaga ścisłych reguł weryfikacji. Musisz upewnić się, że dane wprowadzone do tabeli podtypu spełniają ograniczenia typu nadrzędnego.
- Ograniczenia kluczy obcych: Upewnij się, że wiersze podtypu zawsze są powiązane z ważnymi wierszami typu nadrzędnego. Zapobiega to powstawaniu danych bez rodzica.
- Ograniczenia sprawdzające: Używaj ograniczeń sprawdzających do przestrzegania reguł biznesowych. Na przykład upewnij się, że Stopa procentowa w podtypie Oszczędności podtypu nigdy nie jest ujemna.
- Wyzwalacze: W niektórych złożonych scenariuszach mogą być potrzebne wyzwalacze bazy danych, aby zapewnić spójność między tabelami podczas aktualizacji.
Testy automatyczne powinny obejmować scenariusze dziedziczenia. Sprawdź, czy tworzenie nowej instancji podtypu poprawnie aktualizuje typ nadrzędny. Sprawdź, czy usunięcie instancji typu nadrzędnego poprawnie kaskadowo usuwa podtypy, jeśli tak jest zamierzone. 🧪
📝 Ostateczne rozważania
Modelowanie dziedziczenia to balans między elastycznością a złożonością. Nie ma jednej „poprawnej” metody. Najlepszy wybór zależy od Twoich konkretnych wzorców dostępu do danych, reguł biznesowych i wymagań dotyczących wydajności.
- Zacznij od jasnego zrozumienia domeny. Zmapuj encje, zanim zaczniesz się martwić o tabele.
- Wybierz strategię mapowania, która odpowiada Twoim najczęściej wykonywanym zapytaniom.
- Dokumentuj swoje decyzje. Przyszła konserwacja będzie opierać się na tej dokumentacji.
- Okresowo przeglądaj schemat. W miarę rozwoju działalności model może wymagać zmian.
Czyniąc staranną projektowanie nadtypów i podtypów, tworzysz bazę danych, która jest wytrzymała, skalowalna i łatwa do zrozumienia. Ta podstawa wspiera aplikacje, które na niej opierają się, zapewniając długoterminową stabilność i wydajność. 🏗️