











Projektowanie bazy danych to nie tylko zapisywanie danych; chodzi o strukturyzowanie informacji w sposób zapewniający integralność, zmniejszający nadmiarowość i optymalizujący wydajność. Gdy mówimy o efektywnych strukturach baz danych, dwie kolumny wyróżniają się:Diagramy relacji encji (ERD) oraz Normalizacja. Te koncepcje to nie izolowane techniki, ale uzupełniające się narzędzia działające razem, aby stworzyć solidne fundamenty danych.
Ten przewodnik bada, jak połączyć widoczną przejrzystość ERD z strukturalną ścisłością normalizacji. Przejdziemy przez proces przekształcania modelu koncepcyjnego w praktyczną strukturę, która wytrzyma próbę czasu.
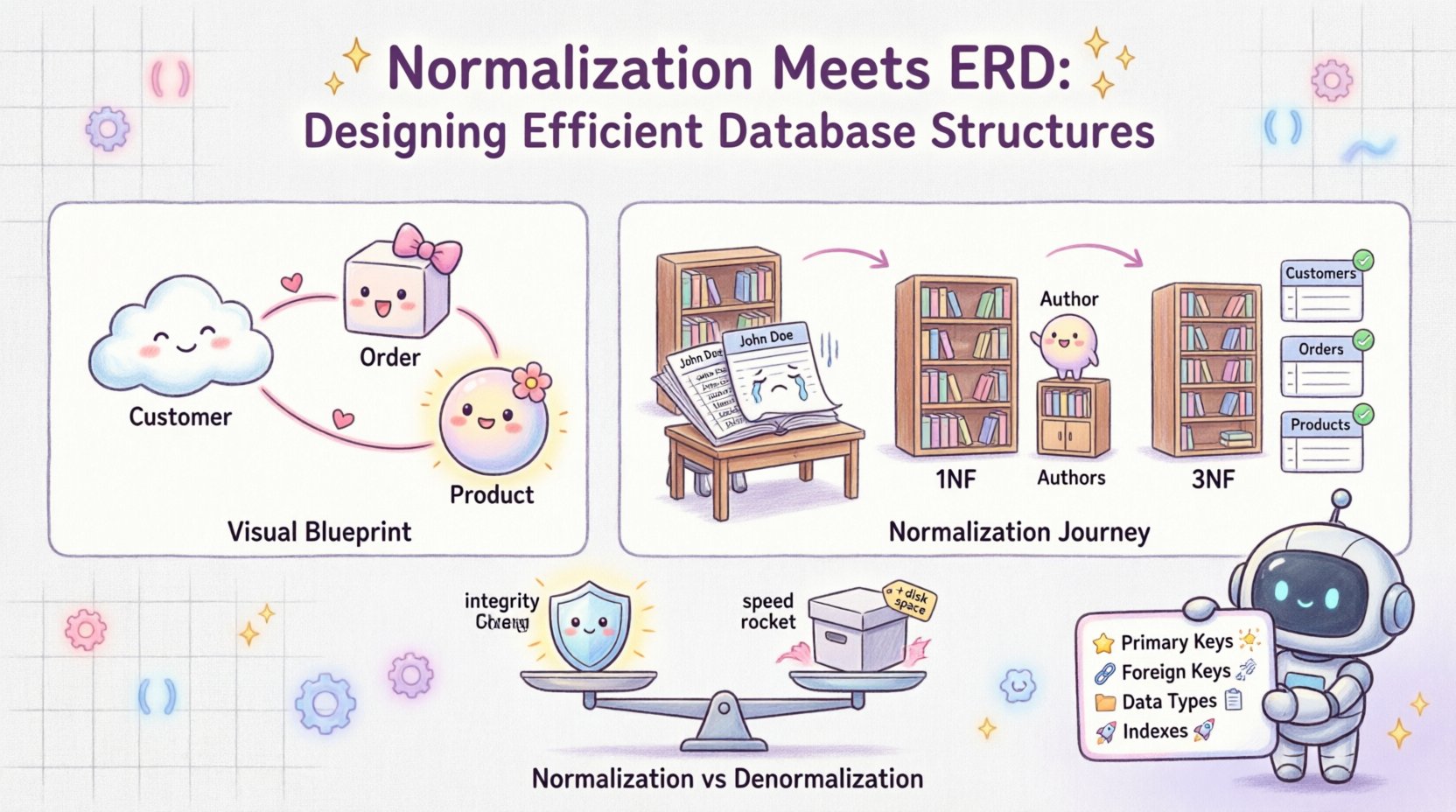
📐 Zrozumienie podstaw: ERD i normalizacja
Zanim przejdziemy do procesu projektowania, istotne jest zrozumienie różnych ról tych dwóch metodologii.
📊 Co to jest diagram relacji encji?
Diagram relacji encji pełni rolę wizualnego projektu bazy danych. Wskazuje encje (tabelki), atrybuty (kolumny) oraz relacje (połączenia) między nimi. Można go porównać do rysunku architektonicznego budynku. Odpowiada na pytania takie jak:
- Jakie są podstawowe obiekty w naszym systemie? (np.Klient, Zamówienie)
- Jak te obiekty się wzajemnie oddziałują? (np. Klient)Klient składa wiele Zamówień)
- Jakie dane musimy przechowywać dla każdego obiektu? (np.Klient potrzebujeImię oraz Adres e-mail)
Bez ERD projektowanie bazy danych staje się grą zgadówek. Zapewnia widok najwyższego poziomu, który może zrozumieć każdy zainteresowany, gwarantując, że wszyscy zgadzają się na wymagania danych, zanim zostanie napisany pierwszy wiersz kodu.
🧼 Co to jest normalizacja?
Normalizacja to proces organizowania danych w bazie danych w celu zmniejszenia nadmiarowości i poprawy integralności danych. Polega na dzieleniu dużych tabel na mniejsze, logiczne struktury oraz definiowaniu relacji między nimi. Celem jest zapewnienie, że każda część danych jest przechowywana dokładnie w jednym miejscu.
Dlaczego to ma znaczenie?
- Integralność danych: Jeśli adres klienta się zmienia, aktualizujesz go w jednym miejscu, a nie w dziesięciu.
- Efektywność przechowywania: Mniej danych powtarzających się oznacza mniejsze zużycie przestrzeni dyskowej.
- Utrzymanie: Łatwiejsze utrzymanie i aktualizacja schematu z biegiem czasu.
⚙️ Przecięcie: łączenie ERD z normalizacją
Projektowanie bazy danych często zaczyna się od ERD, ale surowy ERD rzadko jest gotowy do produkcji. Często zawiera nadmiarowości, które normalizacja rozwiązuje. Przepływ pracy obejmuje tworzenie koncepcyjnego ERD, analizę jego anomalii oraz stosowanie reguł normalizacji w celu wypolerowania schematu.
Oto typowy przepływ pracy:
- Projekt koncepcyjny: Narysuj początkowy ERD na podstawie wymagań.
- Projekt logiczny: Wyprowadź ERD do tabel i kolumn.
- Normalizacja: Zastosuj formy normalizacji (1NF, 2NF, 3NF), aby wyeliminować anomalie.
- Projekt fizyczny: Optymalizuj pod konkretny silnik bazy danych i potrzeby wydajności.
🔍 Krok po kroku: od ERD do schematu znormalizowanego
Przejdźmy przez praktyczny przykład, aby zobaczyć, jak to działa w praktyce. Wyobraź sobie, że budujemy system do zarządzania biblioteką.
1. Stan nieznormalizowany
Na początku możesz zaprojektować jedną tabelę do przechowywania całej informacji o książkach i autorach. Jest to tzw. tabela nieznormalizowana.
| ID_Książki | Tytuł | ImięAutora | TelefonAutora | Gatunek |
|---|---|---|---|---|
| 101 | Wielka powieść | John Doe | 555-0101 | Fikcja |
| 102 | Książka tajemnicy | John Doe | 555-0101 | Tajemnica |
| 103 | Inna książka | Jane Smith | 555-0102 | Fikcja |
Zwróć uwagę na problemy tu? John Doenumer telefonu jest powtarzany. Jeśli zmieni swój numer, musisz zaktualizować wiele wierszy. To jest Anomalie aktualizacji.
2. Pierwsza postać normalna (1NF)
Pierwsze zasady normalizacji to zapewnienie atomowości. Każda kolumna musi zawierać tylko jedną wartość, a nie powinny istnieć powtarzające się grupy.
- Zasada: Usuń powtarzające się grupy i zapewnij wartości atomowe.
- Zastosowanie: W przykładzie biblioteki początkowa tabela może już być atomowa, ale musimy upewnić się, że mamy klucz główny. Załóżmy, że BookID jest unikalny.
- Wynik: Teraz mamy tabelę, w której każda komórka zawiera jedną jednostkę danych.
3. Druga postać normalna (2NF)
Gdy tabela znajduje się w 1NF, sprawdzamy zależności częściowe. Tabela znajduje się w 2NF, jeśli jest w 1NF i każda cecha niekluczowa jest całkowicie zależna od klucza głównego.
- Scenariusz: Gdybyśmy mieli klucz złożony (np. BookID + AuthorID), sprawdzilibyśmy, czy AuthorPhone zależy od całego klucza czy tylko od części dotyczącej autora.
- Działanie: W naszym przykładzie AuthorPhone zależy od AuthorName, a nie BookID. Oznacza to, że powinniśmy rozdzielić dane autora od danych książki.
4. Trzecia postać normalna (3NF)
To tutaj dzieje się prawdziwa magia. 3NF eliminuje zależności przechodnie. Atrybuty niekluczowe nie powinny zależeć od innych atrybutów niekluczowych.
- Zasada: Żaden atrybut nie powinien zależeć od innego atrybutu niekluczowego.
- Zastosowanie: AuthorPhone zależy od AuthorName. Ponieważ AuthorName nie jest kluczem podstawowym tabeli książek, przenosimy informacje o autorze do osobnej tabeli Authors tabeli.
- Wynik: Teraz aktualizacja numeru telefonu autora wymaga zmiany tylko jednego rekordu w tabeli Autorzy tabeli, a nie wielu rekordów w tabeli Książki tabeli.
📋 Normalizacja vs. denormalizacja: Znajdowanie równowagi
Choć normalizacja jest kluczowa dla integralności, nie zawsze jest rozwiązaniem dla wydajności. Czasem odczytywanie danych jest częstsze niż zapisywanie. W takich przypadkach, denormalizacja może być korzystna.
📉 Kiedy denormalizować
Denormalizacja polega na dodawaniu danych nadmiarowych do normalizowanej bazy danych w celu poprawy wydajności odczytu. Jest to kompromis między pamięcią a szybkością.
- Wysokie obciążenie odczytami: Jeśli Twoja aplikacja pobiera dane tysiące razy na sekundę, łączenie tabel może spowolnić wydajność.
- Panel raportów: Dane agregowane mogą być wcześniej obliczane i przechowywane, aby uniknąć skomplikowanych zapytań.
- Strategie buforowania: Czasem widoki denormalizowane działają jak bufor dla często dostępnego danych.
Jednak to wiąże się z ryzykiem. Musisz ręcznie zarządzać synchronizacją danych nadmiarowych lub za pomocą wyzwalaczy. Jeśli nie zostanie to odpowiednio obsługiwane, cierpi integralność danych.
| Czynnik | Normalizacja | Denormalizacja |
|---|---|---|
| Integralność danych | Wysoka (jedno źródło prawdy) | Niższa (wymaga logiki synchronizacji) |
| Szybkość zapisu | Wolniejsza (wiele tabel) | Szybsza (mniej łączeń) |
| Szybkość odczytu | Wolniejsza (wiele łączeń) | Szybsza (mniej łączeń) |
| Przechowywanie | Efektywny | Zbędny |
🛠️ Powszechne pułapki w projektowaniu baz danych
Nawet doświadczeni projektanci popełniają błędy. Unikaj tych powszechnych pułapek, aby zapewnić, że struktura Twojej bazy danych pozostaje zdrowa.
❌ Ignorowanie typów danych
Wybór nieodpowiedniego typu danych może prowadzić do nadmiernego zużycia pamięci i problemów z wydajnością. Używanie pola tekstowego do dat lub liczb całkowitych do numerów telefonów marnuje przestrzeń i utrudnia weryfikację danych.
❌ Nadmierna normalizacja
Wymuszanie 5NF lub BCNF (Postać normalna Boyce’a-Codda) w każdej sytuacji może sprawić, że zapytania stają się niezwykle skomplikowane. Czasem wystarczy 3NF. Nie normalizuj tylko po to, by normalizować.
❌ Słabe klucze podstawowe
Używanie kluczy naturalnych (np. adresów e-mail) jako kluczy podstawowych może być ryzykowne, jeśli dane ulegną zmianie. Klucze zastępcze (liczby całkowite z automatycznym zwiększaniem lub UUID) są często bezpieczniejsze dla relacji wewnętrznych.
❌ Brakujące indeksy
Dobrze znormalizowana schemat może nadal działać słabo bez odpowiedniego indeksowania. Zidentyfikuj kolumny używane często w WHERE, JOIN, lub ORDER BYklauzulach i indeksuj je.
🔄 Iteracyjny proces projektowania
Projektowanie bazy danych rzadko jest liniowe. Jest to proces iteracyjny. Możesz zacząć od ERD, znormalizować go, zauważyć problemy z wydajnością, nieco zdenormalizować i ponownie przejrzeć ERD, aby upewnić się, że relacje nadal są poprawne.
🔄 Kroki doskonalenia
- Przejrzyj wymagania:Czy nowe funkcje wymagają nowych tabel?
- Analiza zapytań:Przyjrzyj się najwolniejszym zapytaniom i zidentyfikuj węzły zatkania.
- Sprawdzanie ograniczeń:Upewnij się, że klucze obce są poprawnie zdefiniowane, aby zapobiec powstawaniu zaniedbanych rekordów.
- Dokumentacja:Utrzymuj swój ERD aktualny. Ustareły schemat jest gorszy niż żaden schemat.
📈 Względy dotyczące wydajności
Normalizacja przede wszystkim rozwiązuje problemy z integralnością danych. Wydajność to osobna kwestia, która często wymaga dopasowania. Jednak obie są ze sobą powiązane.
🚀 Złożoność łączenia (JOIN)
Bazy danych o wysokiej normalizacji wymagają więcej ŁĄCZENIA (JOIN)operacji w celu pobrania powiązanych danych. Nowoczesne silniki baz danych bardzo dobrze optymalizują łączenia, ale nadmierne łączenia mogą nadal wpływać na opóźnienia.
📦 Silnik przechowywania danych
Różne silniki przechowywania danych obsługują dane inaczej. Niektóre preferują przechowywanie w formie wierszy, inne zaś w formie kolumn. Twoja strategia normalizacji może wymagać dostosowania w zależności od podstawowego silnika.
🔒 Ograniczenia i wyzwalacze (triggers)
Wzmacnianie reguł normalizacji za pomocą ograniczeń (takich jak klucze obce) zapewnia jakość danych. Jednak nadmierna liczba wyzwalaczy do weryfikacji może spowolnić operacje zapisu. Używaj ich rozważnie.
🧩 Przykład z rzeczywistego świata: system zamówień e-commerce
Spójrzmy na nieco bardziej złożony scenariusz: sklep internetowy.
Początkowy model ERD
Na początku możesz mieć tabelę Zamówienietabelę zawierającą nazwy produktów, ceny oraz dane klienta. Jest to klasyczny sposób „pliku płaskiego”.
Podejście znormalizowane
Aby to naprawić, podzieliliśmy dane:
- Tabela Klienci: Przechowuje dane klienta (Imię, Adres, Email).
- Tabela Produkty: Przechowuje dane produktu (Nazwa, Cena, Stan magazynowy).
- Tabela Zamówienia: Przechowuje transakcję (IDKlienta, DataZamówienia, Razem).
- Tabela PozycjeZamówień: Łączy Zamówienia i Produkty (IDZamówienia, IDProduktu, Ilość, CenaWChwili).
Ta struktura pozwala nam:
- Zaktualizować cenę produktu w jednym miejscu (w tabeli Produkty ).
- Śledź ceny historyczne w tabeli ElementyZamówienia tabela (przechwytywanie zrzutów).
- Upewnij się, że klient nie może zostać usunięty, jeśli ma otwarte zamówienia (przez klucze obce).
🎯 Lista najlepszych praktyk
Zanim wdrożysz swoją schemat, przejdź przez tę listę kontrolną, aby upewnić się, że jakość jest odpowiednia.
- ✅ Klucze podstawowe: Każda tabela ma unikalny identyfikator.
- ✅ Klucze obce: Relacje są jawnie zdefiniowane.
- ✅ Możliwość wartości NULL: Kolumny są oznaczone jako
NOT NULLtam, gdzie to odpowiednie. - ✅ Typy danych: Używaj możliwie najbardziej szczegółowego typu danych.
- ✅ Zasady nazewnictwa: Używaj spójnych, jasnych nazw dla tabel i kolumn.
- ✅ Dokumentacja: ERD odpowiada schematowi fizycznemu.
- ✅ Strategia kopii zapasowych: Zastanów się, jak schemat wpływa na czas tworzenia kopii zapasowych i przywracania.
🔮 Przyszłość projektowania baz danych
W miarę jak technologia się rozwija, podstawowe zasady normalizacji i schematów ERD pozostają aktualne. Choć bazy danych NoSQL oferują elastyczność, model relacyjny wciąż dominuje w systemach transakcyjnych. Zrozumienie podstaw pozwala dostosować się do nowych technologii bez utraty dyscypliny modelowania danych.
Bazy danych w chmurze wprowadzają nowe wymiary, takie jak fragmentacja i partycjonowanie. Jednak struktura logiczna, którą projektujesz przy użyciu schematów ERD i normalizacji, nadal stanowi projekt, według którego dane są dystrybuowane i dostępne.
📝 Podsumowanie kluczowych wniosków
Projektowanie efektywnych struktur baz danych to równowaga między strukturą a elastycznością. Oto co powinieneś pamiętać:
- Schematy ERD to wizualne przewodniki: Są one mapowaniem relacji jeszcze przed budową.
- Normalizacja to strukturalna: Organizuje dane w celu zmniejszenia nadmiarowości.
- 3NF to cel: Dąż do Trzeciej Postaci Normalnej w większości systemów transakcyjnych.
- Denormalizuj rozważnie: Dodawaj nadmiarowość tylko wtedy, gdy wymaga tego wydajność.
- Iteruj: Projekt nigdy nie jest gotowy; rozwija się razem z aplikacją.
Łącząc jasność wizualną schematów relacji encji z rygorystycznymi zasadami normalizacji, tworzysz podstawę danych, która jest zarówno wiarygodna, jak i skalowalna. Ten podejście zapewnia, że Twoja baza danych może rosnąć razem z aplikacją, radząc sobie z złożonością bez naruszenia integralności.
Zacznij od czystego schematu ERD. Stopniowo stosuj zasady normalizacji. Testuj swoje zapytania. Doskonal schemat. I zawsze w pierwszych etapach dawaj priorytet integralności danych przed szybkością.