











Construir um sistema de banco de dados é semelhante a construir a fundação de um arranha-céu. Se o projeto estiver defeituoso, a estrutura acabará rachando sob pressão. Um Diagrama de Relacionamento de Entidades (ERD) é esse projeto. Ele define como os dados se conectam, fluem e persistem em sua aplicação. À medida que sua base de usuários cresce e o volume de dados explode, um design estático frequentemente se torna um gargalo. Para garantir longevidade, você deve adotar princípios de design escaláveis de ERD desde o início. Este guia explora as estratégias técnicas necessárias para construir sistemas duradouros.
Compreendendo o Núcleo da Modelagem de Dados 🧱
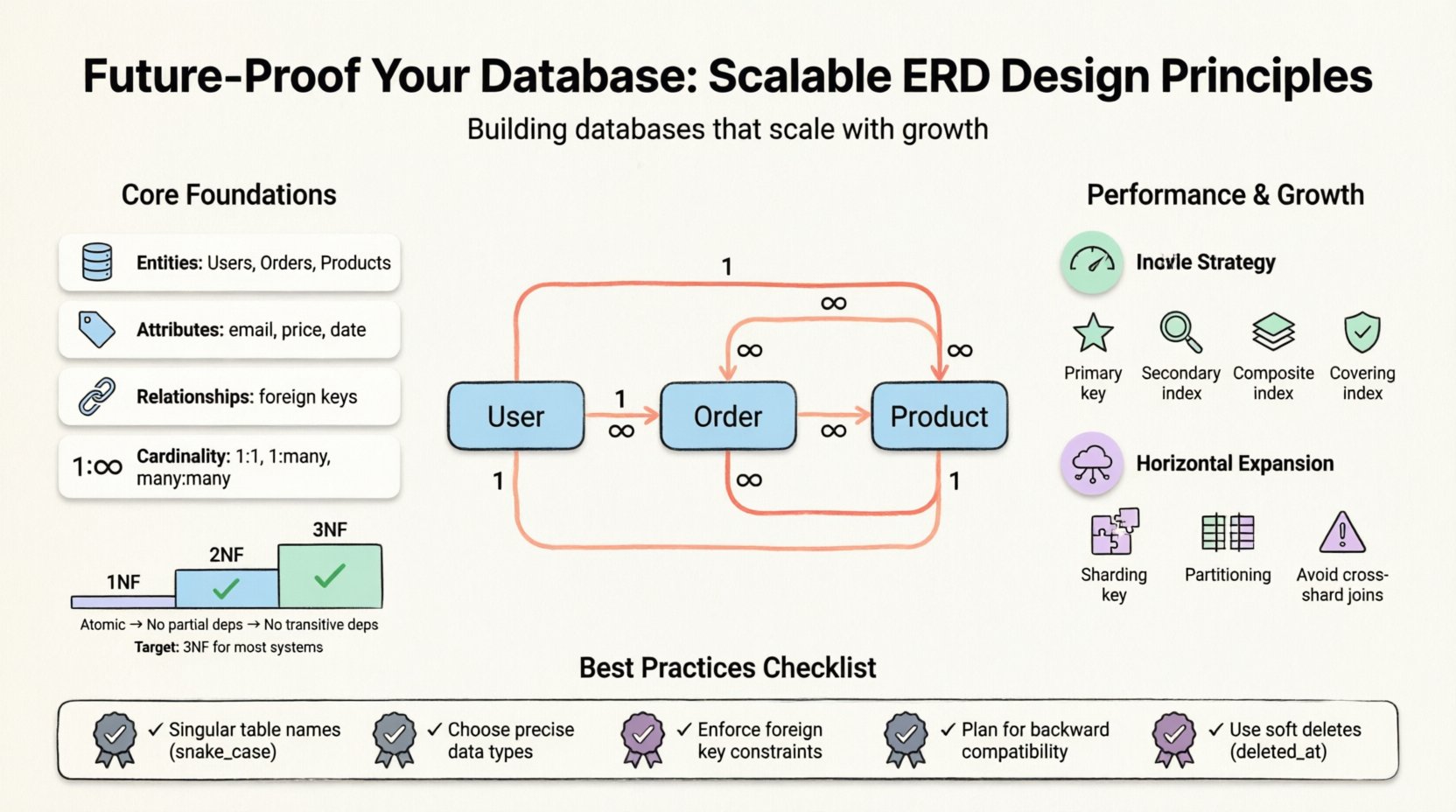
Antes de mergulhar em táticas específicas, é essencial compreender o que um ERD representa. Ele visualiza a estrutura lógica de um banco de dados. Ele mapeia entidades (tabelas), atributos (colunas) e relacionamentos (chaves). Um modelo bem elaborado equilibra a integridade dos dados com o desempenho. No entanto, a ‘melhor prática’ varia conforme a carga de trabalho. Uma aplicação com foco em leitura exige otimizações diferentes de um sistema transacional com foco em gravação.
Os principais componentes incluem:
- Entidades: Os objetos principais, como Usuários, Pedidos ou Produtos.
- Atributos: As propriedades que definem uma entidade, como endereços de e-mail ou preços.
- Relacionamentos: Como as entidades interagem, frequentemente definidas por chaves estrangeiras.
- Cardinalidade: A relação numérica entre entidades (um-para-um, um-para-muitos, muitos-para-muitos).
Normalização: O Equilíbrio Entre Redundância e Velocidade ⚖️
A normalização é o processo de organizar os dados para reduzir redundâncias e melhorar a integridade. Embora frequentemente tratada como uma regra rígida, é uma troca de valores. A alta normalização minimiza anomalias, mas pode aumentar a complexidade das consultas por meio de junções. A baixa normalização (denormalização) acelera as leituras, mas corre o risco de inconsistência nos dados.
Níveis de Normalização
Compreender as formas padrão ajuda você a decidir onde parar. Cada forma aborda anomalias específicas de dados.
- Primeira Forma Normal (1NF): Garante atomicidade. Cada coluna deve conter valores indivisíveis. Nenhum grupo repetido ou array dentro de uma única célula.
- Segunda Forma Normal (2NF): Baseia-se na 1NF. Todos os atributos não-chave devem depender da chave primária inteira, e não apenas de parte dela. Isso elimina dependências parciais.
- Terceira Forma Normal (3NF): Baseia-se na 2NF. Atributos não-chave não podem depender de outros atributos não-chave. Isso remove dependências transitivas.
- Forma Normal de Boyce-Codd (BCNF): Uma versão mais rigorosa da 3NF. Ela trata casos em que os determinantes não são chaves candidatas.
Para a maioria dos sistemas escaláveis, alcançar a 3NF é o objetivo padrão. Ir além frequentemente resulta em retornos decrescentes, ao mesmo tempo em que aumenta a sobrecarga de manutenção. No entanto, para sistemas com foco em análise, um retorno controlado à denormalização é comum.
Tabela de Trade-Offs da Normalização
| Nível de Normalização | Benefício Principal | Principal Desvantagem |
|---|---|---|
| 1FV | Armazenamento de dados atômicos | Nenhum |
| 2FV | Elimina dependências parciais | Mais junções necessárias |
| 3FV | Elimina dependências transitivas | Complexidade aumentada nas junções |
| Não normalizado | Consultas de leitura mais rápidas | Redundância de dados e anomalias de atualização |
Design de Esquema para Crescimento e Flexibilidade 📈
Projetar apenas para o presente é insuficiente. Você deve antecipar a evolução futura do esquema. Estruturas rígidas quebram quando a lógica de negócios muda. Um design flexível permite expansão sem exigir uma migração completa do sistema.
1. Convenções e Padrões de Nomeação
A consistência é vital para a manutenibilidade. Um esquema de nomeação caótico leva à confusão e erros. Estabeleça um padrão cedo e aplique-o em toda a equipe.
- Use nomes no singular:As tabelas devem representar uma única entidade (por exemplo,
usuário, nãousuários). - Delimitadores consistentes:Use snake_case para nomes de tabelas e colunas para garantir compatibilidade entre diferentes sistemas operacionais e ferramentas.
- Prefixos para especificidade:Use prefixos como
fk_para chaves estrangeiras ouidx_para índices, para tornar seu propósito claro. - Evite palavras reservadas: Nunca use palavras-chave como
order,group, ouselectcomo nomes de colunas.
2. Tipos de Dados e Precisão
Escolher o tipo de dado correto afeta o espaço de armazenamento e a velocidade das consultas. Tipos excessivamente genéricos desperdiçam espaço e retardam o processamento.
- Inteiros: Use
TINYINTpara flags (0-1) ou contagens pequenas. UseBIGINTapenas quando você antecipa uma escala massiva. - Strings: Evite
TEXTpara valores curtos. UseVARCHARcom um comprimento específico para economizar espaço e permitir indexação. - Datas: Use
TIMESTAMPpara momentos específicos eDATEapenas para datas do calendário. Sempre armazene em UTC para evitar confusão com fuso horário. - Decimais: Para dados financeiros, use decimais de ponto fixo em vez de números de ponto flutuante para evitar erros de arredondamento.
Relacionamentos e Gerenciamento de Cardinalidade 🔗
Como as entidades se relacionam define a integridade dos seus dados. Relacionamentos mal geridos levam a registros órfãos e perda de dados.
1. Restrições de Chave Estrangeira
Chaves estrangeiras garantem a integridade referencial. Elas garantem que um registro em uma tabela não possa referenciar um registro inexistente em outra. Embora alguns desenvolvedores desativem essas restrições por desempenho, motores de banco de dados modernos as gerenciam de forma eficiente. Depender de verificações em nível de aplicação é propenso a erros.
2. Gerenciamento de Relacionamentos Muitos para Muitos
Um relacionamento muitos para muitos (por exemplo, Alunos e Cursos) não pode ser representado diretamente em duas tabelas. Ele exige uma tabela de junção (entidade associativa).
- Crie uma nova tabela contendo as chaves primárias de ambas as tabelas relacionadas.
- Adicione uma chave primária composta composta por ambas as chaves estrangeiras.
- Use esta tabela para armazenar atributos adicionais específicos do relacionamento, como datas de matrícula.
3. Relacionamentos Opcionais vs. Obrigatórios
Defina claramente se um relacionamento é obrigatório. Um NULLvalor em uma coluna de chave estrangeira indica um relacionamento opcional. Essa decisão afeta a lógica de validação na camada de aplicação.
Estratégias de Indexação para Desempenho de Leitura 🏎️
Índices são o mecanismo principal para acelerar a recuperação de dados. No entanto, eles não são gratuitos. Cada índice consome espaço em disco e desacelera operações de escrita (inserções, atualizações, exclusões).
1. Índices Primários
Toda tabela precisa de uma chave primária. Isso geralmente é agrupado, o que significa que os dados físicos são armazenados na ordem da chave. Escolha uma chave estável e que nunca seja atualizada. Chaves de substituição (inteiros autoincrementáveis) geralmente são melhores que chaves naturais (como e-mails) em termos de desempenho.
2. Índices Secundários
Use índices secundários para otimizar consultas que filtram ou ordenam em colunas não primárias. Cenários comuns incluem:
- Pesquisa por endereço de e-mail.
- Filtragem por status ou categoria.
- Ordenação dos resultados por data.
3. Índices Compostos
Quando consultando por múltiplas colunas, um índice composto pode ser mais eficiente que índices separados por coluna única. A ordem das colunas no índice importa. Coloque a coluna mais seletiva primeiro.
4. Índices Cobertores
Um índice cobertor inclui todas as colunas necessárias para atender a uma consulta. Isso permite que o banco de dados recupere os dados diretamente do índice, sem acessar a tabela principal, reduzindo significativamente a I/O.
Projeto para Escalonamento Horizontal 🌐
O escalonamento vertical (adicionar mais poder a um único servidor) tem limites. Eventualmente, você precisará distribuir os dados entre múltiplos nós. O projeto do ERD deve levar em conta essa realidade.
1. Chaves de Shard
O shardinge envolve dividir os dados entre múltiplos bancos de dados. A escolha da chave de shard é crítica. Ela deve ser usada com frequência em consultas para garantir localidade de dados. Se você fizer o shard por “user_id, você pode facilmente consultar todos os dados desse usuário em um único nó.
- Chaves de Sharding Boas: Alta cardinalidade, frequentemente usada em consultas.
- Chaves de Sharding Ruins: Baixa cardinalidade (por exemplo,
country_code) ou raramente usada.
2. Evitando Joins entre Shard
Joins entre diferentes shard são caros e complexos. Projete seu esquema para minimizar a necessidade deles. Se você precisar de dados de duas entidades que podem estar em shard diferentes, considere denormalizar os dados. Armazene os dados de chave estrangeira necessários diretamente na tabela para evitar o join.
3. Particionamento
O particionamento divide uma tabela grande em pedaços menores e gerenciáveis. Isso pode ser feito por faixa (datas), lista (categorias) ou hash. Isso melhora a manutenção e o desempenho de consultas sem alterar significativamente a lógica do aplicativo.
Evolução e Migração de Esquemas 🔄
Requisitos mudam. Novas funcionalidades exigem novas colunas. Funcionalidades antigas são descontinuadas. Um ERD robusto acomoda mudanças sem quebrar a funcionalidade existente.
1. Compatibilidade com Versões Anteriores
Ao adicionar novas funcionalidades, certifique-se de que os clientes antigos ainda possam funcionar. Adicione novas colunas como nulas primeiro. Preencha-as gradualmente. Não remova colunas imediatamente; marque-as como obsoletas e mantenha-as durante uma janela de migração.
2. Versionamento de Modelos de Dados
Monitore as versões do esquema. Isso permite que você reverta mudanças se uma migração causar falhas críticas. Use scripts de migração idempotentes, ou seja, que podem ser executados múltiplas vezes sem causar erros.
3. Tratamento de Migração de Dados
Mover grandes volumes de dados exige planejamento cuidadoso. Grandes bloqueios podem bloquear o tráfego de produção. Realize as migrações durante períodos de baixo tráfego ou use estratégias de implantação azul-verde, quando possível.
Armadilhas Comuns para Evitar ⚠️
Mesmo arquitetos experientes cometem erros. O conhecimento sobre erros comuns ajuda você a evitá-los.
- Engenharia Excessiva: Projetar para uma escala que você ainda não possui. Se você está começando, mantenha simples. A complexidade adiciona custo e risco.
- Ignorar Exclusões Suaves: Nunca exclua permanentemente registros sensíveis imediatamente. Use um
deleted_attimestamp em vez disso. Isso preserva os rastros de auditoria e permite a recuperação. - Conflitos de Nomes: Usar o mesmo nome para uma tabela e uma coluna cria ambiguidade. Mantenha a regra de tabela no singular.
- Restrições Ausentes:Contar exclusivamente com a lógica da aplicação para impor regras de negócios leva à corrupção de dados. Aplicar restrições no nível do banco de dados.
- Ignorando Segurança:O design deve incluir campos para controle de acesso. Certifique-se de que o acesso baseado em funções seja suportado na fase de design do esquema.
Considerações Finais para Longevidade 🏁
Criar um banco de dados escalável é um processo contínuo. Exige monitoramento, análise e ajustes. Nenhum design é perfeito no lançamento. O objetivo é criar uma base que seja fácil de modificar.
Audite regularmente suas consultas. Identifique operações lentas e otimize o esquema subjacente. Use ferramentas de perfil para entender como seus dados são acessados. Esse ciclo de feedback garante que sua arquitetura permaneça eficiente à medida que seus dados crescem.
Lembre-se de que a tecnologia evolui. Novos motores de armazenamento e linguagens de consulta surgem. Um esquema flexível se adapta a essas mudanças melhor do que um rígido. Foque nas relações principais e na integridade dos dados. Esses aspectos permanecem constantes mesmo quando as ferramentas mudam.
Ao seguir esses princípios, você constrói sistemas resilientes. Eles lidam com o crescimento com elegância e mantêm o desempenho sob carga. Essa é a essência de tornar sua infraestrutura de banco de dados futurista.