











Projetar um banco de dados não é meramente armazenar dados; é estruturar informações de forma a garantir integridade, reduzir redundâncias e otimizar o desempenho. Quando falamos em estruturas de banco de dados eficientes, dois pilares se destacam: Diagramas de Entidade-Relacionamento (ERD) e Normalização. Esses conceitos não são técnicas isoladas, mas ferramentas complementares que trabalham juntas para criar uma base de dados sólida.
Este guia explora como combinar a clareza visual dos ERDs com o rigor estrutural da normalização. Vamos percorrer o processo de transformar um modelo conceitual em um esquema prático que resista ao teste do tempo.
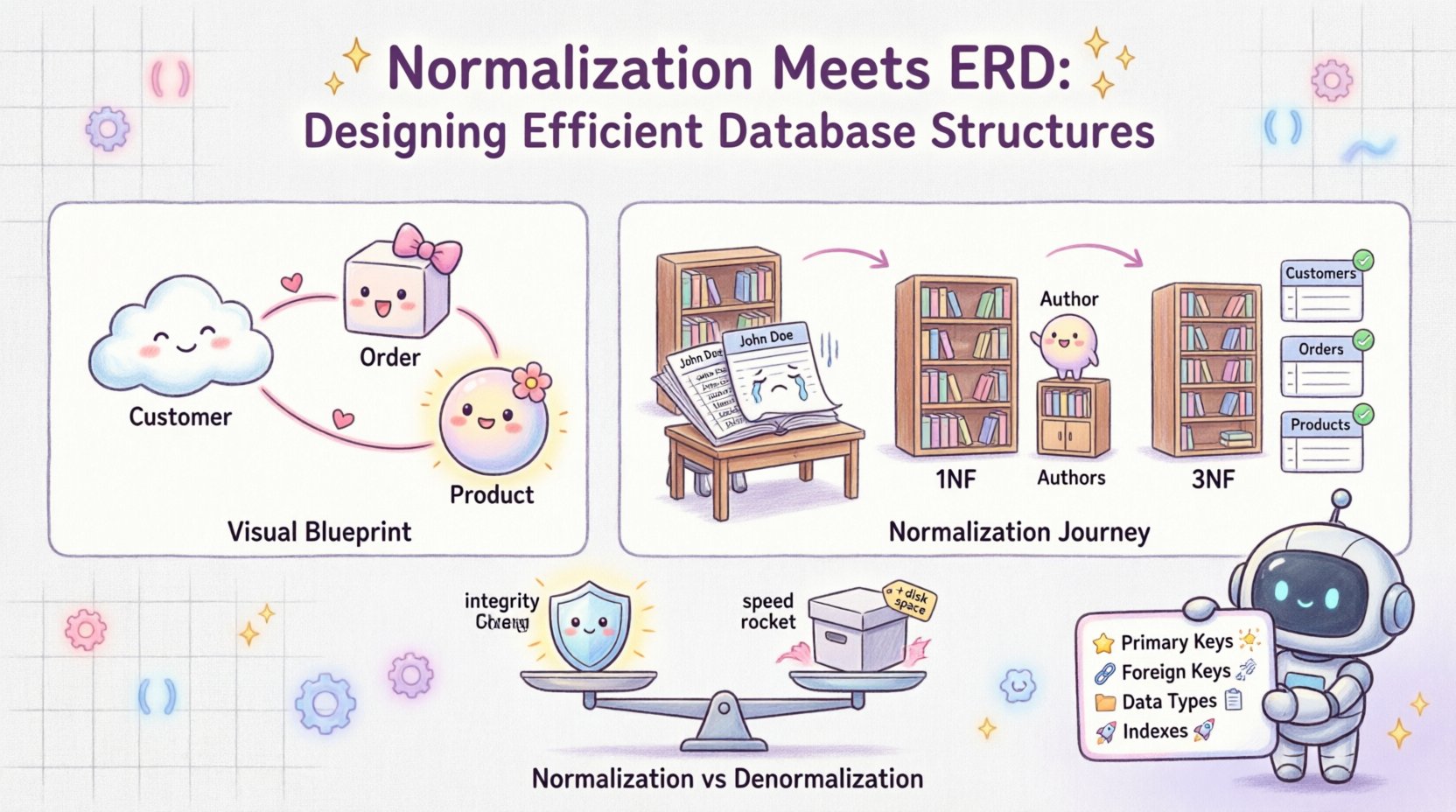
📐 Compreendendo a Fundação: ERDs e Normalização
Antes de mergulhar no processo de design, é essencial compreender as funções distintas dessas duas metodologias.
📊 O que é um Diagrama de Entidade-Relacionamento?
Um Diagrama de Entidade-Relacionamento serve como o plano visual de um banco de dados. Ele mapeia entidades (tabelas), atributos (colunas) e relacionamentos (links) entre elas. Pense nele como o desenho arquitetônico de um edifício. Ele responde perguntas como:
- Quais são os objetos principais do nosso sistema? (por exemplo, Cliente, Pedido)
- Como esses objetos interagem? (por exemplo, um Cliente faz muitos Pedidos)
- Que dados precisamos armazenar para cada objeto? (por exemplo, Cliente precisa de um Nome e E-mail)
Sem um ERD, o projeto de banco de dados torna-se um jogo de adivinhação. Ele fornece uma visão de alto nível que os interessados podem compreender, garantindo que todos estejam de acordo com os requisitos de dados antes de escrever uma única linha de código.
🧼 O que é Normalização?
A normalização é o processo de organizar dados em um banco de dados para reduzir a redundância e melhorar a integridade dos dados. Envolve dividir tabelas grandes em estruturas menores e lógicas e definir relacionamentos entre elas. O objetivo é garantir que cada peça de dados seja armazenada em exatamente um local.
Por que isso importa?
- Integridade dos Dados:Se o endereço de um cliente mudar, você o atualiza em um único local, e não em dez.
- Eficiência de Armazenamento:Menos dados duplicados significam menor uso de espaço em disco.
- Manutenção:Mais fácil de manter e atualizar o esquema ao longo do tempo.
⚙️ A Interseção: Mesclando ERD com Normalização
O projeto de um banco de dados geralmente começa com um ERD, mas um ERD bruto raramente está pronto para produção. Ele frequentemente contém redundâncias que a normalização resolve. O fluxo de trabalho envolve criar um ERD conceitual, analisá-lo quanto a anomalias e aplicar regras de normalização para aprimorar o esquema.
Aqui está o fluxo de trabalho típico:
- Projeto Conceitual: Desenhe o ERD inicial com base nos requisitos.
- Projeto Lógico: Aperfeiçoe o ERD em tabelas e colunas.
- Normalização: Aplique formas de normalização (1FN, 2FN, 3FN) para eliminar anomalias.
- Projeto Físico: Otimize para o motor de banco de dados específico e as necessidades de desempenho.
🔍 Passo a Passo: Do ERD ao Esquema Normalizado
Vamos percorrer um cenário prático para ver como isso funciona na prática. Imagine que estamos construindo um sistema para gerenciar uma biblioteca.
1. O Estado Não Normalizado
Inicialmente, você pode projetar uma única tabela para armazenar todas as informações sobre livros e autores. Isso é conhecido como uma tabela não normalizada.
| ID do Livro | Título | Nome do Autor | Telefone do Autor | Gênero |
|---|---|---|---|---|
| 101 | O Grande Romance | John Doe | 555-0101 | Ficção |
| 102 | O Livro do Mistério | John Doe | 555-0101 | Mistério |
| 103 | Outro Livro | Jane Smith | 555-0102 | Ficção |
Perceba os problemas aqui? John Doeo número de telefone é repetido. Se ele mudar o número, você precisará atualizar várias linhas. Isso é um Anomalia de Atualização.
2. Primeira Forma Normal (1FN)
A primeira regra da normalização é garantir a atomicidade. Cada coluna deve conter apenas um único valor, e não deve haver grupos repetidos.
- Regra: Elimine grupos repetidos e garanta valores atômicos.
- Aplicação: No nosso exemplo de biblioteca, a tabela inicial já pode ser atômica, mas devemos garantir que tenhamos uma Chave Primária. Vamos supor que BookID é único.
- Resultado: Agora temos uma tabela em que cada célula contém uma única peça de dados.
3. Segunda Forma Normal (2FN)
Uma vez que uma tabela está na 1FN, verificamos as dependências parciais. Uma tabela está na 2FN se estiver na 1FN e cada atributo não-chave depender totalmente da chave primária.
- Cenário: Se tivéssemos uma chave composta (por exemplo, BookID + AuthorID), verificaríamos se AuthorPhone depende da chave inteira ou apenas da parte do autor.
- Ação: Em nosso exemplo, AuthorPhone depende de AuthorName, e não o BookID. Isso sugere que devemos separar os dados do autor dos dados do livro.
4. Terceira Forma Normal (3FN)
É aqui que acontece a verdadeira mágica. A 3FN elimina as dependências transitivas. Atributos não-chave não devem depender de outros atributos não-chave.
- Regra: Nenhum atributo deve depender de outro atributo não-chave.
- Aplicação: AuthorPhone depende de AuthorName. Como AuthorName não é a chave primária da tabela de livros, movemos as informações do autor para uma tabela separada Authors tabela.
- Resultado: Agora, atualizar o número de telefone de um autor exige alterar apenas um registro na Autores tabela, não múltiplos registros na Livros tabela.
📋 Normalização vs. Denormalização: Encontrando o Equilíbrio
Embora a normalização seja crucial para a integridade, nem sempre é a solução para o desempenho. Às vezes, a leitura de dados é mais frequente do que a escrita. Nestes casos, denormalização pode ser benéfica.
📉 Quando denormalizar
A denormalização envolve adicionar dados redundantes a um banco de dados normalizado para melhorar o desempenho de leitura. É um equilíbrio entre armazenamento e velocidade.
- Alto volume de leituras: Se seu aplicativo consulta dados milhares de vezes por segundo, unir tabelas pode reduzir o desempenho.
- Painéis de relatórios: Dados agregados podem ser previamente calculados e armazenados para evitar consultas complexas.
- Estratégias de cache: Às vezes, visualizações denormalizadas atuam como cache para dados frequentemente acessados.
No entanto, isso traz riscos. Você deve gerenciar a sincronização dos dados redundantes manualmente ou por meio de gatilhos. Se não for feito com cuidado, a integridade dos dados sofre.
| Fator | Normalização | Denormalização |
|---|---|---|
| Integridade dos dados | Alta (fonte única de verdade) | Menor (requer lógica de sincronização) |
| Velocidade de escrita | Mais lenta (várias tabelas) | Mais rápida (menos junções) |
| Velocidade de leitura | Mais lenta (várias junções) | Mais rápida (menos junções) |
| Armazenamento | Eficiente | Redundante |
🛠️ Armadilhas Comuns no Design de Banco de Dados
Mesmo designers experientes cometem erros. Evite essas armadilhas comuns para garantir que a estrutura do seu banco de dados permaneça saudável.
❌ Ignorar Tipos de Dados
Escolher o tipo de dado errado pode levar a aumento de armazenamento e problemas de desempenho. Usar um campo de texto para datas ou inteiros para números de telefone desperdiça espaço e complica a validação.
❌ Sobrenormalização
Insistir na 5NF ou na BCNF (Forma Normal de Boyce-Codd) em todas as situações pode tornar as consultas incrivelmente complexas. Às vezes, a 3NF é suficiente. Não normalize apenas por conveniência.
❌ Chaves Primárias Fracas
Usar chaves naturais (como endereços de e-mail) como chaves primárias pode ser arriscado se os dados mudarem. Chaves surrogate (inteiros autoincrementáveis ou UUIDs) são geralmente mais seguras para relacionamentos internos.
❌ Índices Ausentes
Um esquema bem normalizado ainda pode apresentar desempenho ruim sem indexação adequada. Identifique as colunas usadas com frequência em WHERE, JOIN, ou ORDER BYcláusulas e os indexe.
🔄 O Processo Iterativo de Design
O design de banco de dados raramente é linear. É um processo iterativo. Você pode começar com um DER, normalizá-lo, perceber que o desempenho é um problema, desnormalizar levemente e depois revisitar o DER para garantir que os relacionamentos ainda sejam precisos.
🔄 Etapas de Aperfeiçoamento
- Revisão de Requisitos:Novos recursos exigem novas tabelas?
- Análise de Consultas:Analise as consultas mais lentas e identifique gargalos.
- Verificação de Restrições:Garanta que as chaves estrangeiras estejam corretamente definidas para evitar registros órfãos.
- Documentação:Mantenha seu DER atualizado. Um diagrama desatualizado é pior do que nenhum diagrama.
📈 Considerações de Desempenho
A normalização trata principalmente da integridade dos dados. O desempenho é uma preocupação separada que frequentemente exige ajustes. No entanto, os dois estão relacionados.
🚀 Complexidade de Junção
Bancos de dados altamente normalizados exigem mais JUNÇÃOoperações para recuperar dados relacionados. Motores de banco de dados modernos são muito bons em otimizar junções, mas junções excessivas ainda podem afetar a latência.
📦 Motor de Armazenamento
Motores de armazenamento diferentes lidam com os dados de maneiras diferentes. Alguns favorecem o armazenamento baseado em linhas, enquanto outros favorecem o armazenamento baseado em colunas. A sua estratégia de normalização pode precisar se adaptar com base no motor subjacente.
🔒 Restrições e Gatilhos
Garantir as regras de normalização por meio de restrições (como chaves estrangeiras) assegura a qualidade dos dados. No entanto, o uso excessivo de gatilhos para validação pode retardar as operações de gravação. Use-os com sabedoria.
🧩 Exemplo do Mundo Real: Sistema de Pedidos de Comércio Eletrônico
Vamos analisar um cenário ligeiramente mais complexo: uma loja online.
Conceito Inicial de ERD
No início, você pode ter uma Pedidotabela que inclui nomes de produtos, preços e detalhes do cliente. Este é o método clássico de “arquivo plano”.
Abordagem Normalizada
Para corrigir isso, dividimos os dados:
- Tabela de Clientes: Armazena os detalhes do cliente (Nome, Endereço, E-mail).
- Tabela de Produtos: Armazena os detalhes do produto (Nome, Preço, Estoque).
- Tabela de Pedidos: Armazena a transação (ID do Cliente, Data do Pedido, Total).
- Tabela de Itens do Pedido: Liga Pedidos e Produtos (ID do Pedido, ID do Produto, Quantidade, Preço na Hora).
Essa estrutura nos permite:
- Atualizar o preço de um produto em um único local (a Produtostabela).
- Rastreie os preços históricos na ItensDoPedido tabela (captura de instantâneo).
- Garanta que um cliente não possa ser excluído se tiver pedidos abertos (por meio de chaves estrangeiras).
🎯 Lista de Verificação de Melhores Práticas
Antes de implantar seu esquema, percorra esta lista de verificação para garantir a qualidade.
- ✅ Chaves Primárias: Cada tabela tem um identificador exclusivo.
- ✅ Chaves Estrangeiras: As relações são definidas explicitamente.
- ✅ Nulidade: As colunas são marcadas como
NÃO NULOquando apropriado. - ✅ Tipos de Dados: Use o tipo de dado mais específico possível.
- ✅ Convenções de Nomeação: Use nomes consistentes e claros para tabelas e colunas.
- ✅ Documentação: O diagrama ERD corresponde ao esquema físico.
- ✅ Estratégia de Backup: Considere como o esquema afeta os tempos de backup e restauração.
🔮 O Futuro do Design de Banco de Dados
À medida que a tecnologia evolui, os princípios fundamentais de normalização e ERDs permanecem relevantes. Embora os bancos de dados NoSQL ofereçam flexibilidade, o modelo relacional ainda domina os sistemas transacionais. Compreender os fundamentos permite adaptar-se a novas tecnologias sem perder a disciplina da modelagem de dados.
Bancos de dados em nuvem introduzem novas dimensões, como sharding e particionamento. No entanto, a estrutura lógica que você projeta usando ERDs e normalização continua sendo o plano mestre para como os dados são distribuídos e acessados.
📝 Resumo dos Principais Pontos
Projetar estruturas de banco de dados eficientes é um equilíbrio entre estrutura e flexibilidade. Aqui está o que você deve lembrar:
- ERDs são Guias Visuais: Eles mapeiam as relações antes de você construir.
- Normalização é Estrutural: Organiza os dados para reduzir a redundância.
- 3FN é o Objetivo:Busque a Terceira Forma Normal na maioria dos sistemas transacionais.
- Denormalize com Sabedoria: Adicione redundância apenas quando o desempenho exigir.
- Itere: O design nunca está terminado; evolui com o aplicativo.
Ao combinar a clareza visual dos Diagramas de Relacionamento de Entidades com as regras rigorosas de Normalização, você cria uma base de dados confiável e escalável. Essa abordagem garante que seu banco de dados possa crescer com seu aplicativo, lidando com a complexidade sem comprometer a integridade.
Comece com um ERD limpo. Aplique as regras de normalização passo a passo. Teste suas consultas. Aperfeiçoe seu esquema. E sempre priorize a integridade dos dados sobre a velocidade nas fases iniciais.