










Проектирование надежных схем баз данных требует больше, чем просто перечисление таблиц и столбцов. Это требует глубокого понимания того, как сущности связаны между собой. Одной из самых мощных, но сложных концепций в диаграммах сущность-связь (ERD) является наследование. Этот механизм позволяет моделировать иерархии реального мира, где объекты делят общие характеристики, но также обладают уникальными атрибутами. В контексте проектирования баз данных это означает супертипы и подтипы. 🧩
Когда мы моделируем наследование, мы фактически фиксируем отношение «является-видом». Например, Транспортное средство является типом Продукт, а Автомобиль является типом Транспортное средство. Эта иерархия позволяет повторно использовать атрибуты на более высоких уровнях, одновременно определяя специфическое поведение или данные на более низких уровнях. Понимание того, как реализовать это в реляционной базе данных, критически важно для целостности данных и производительности запросов. 🗄️
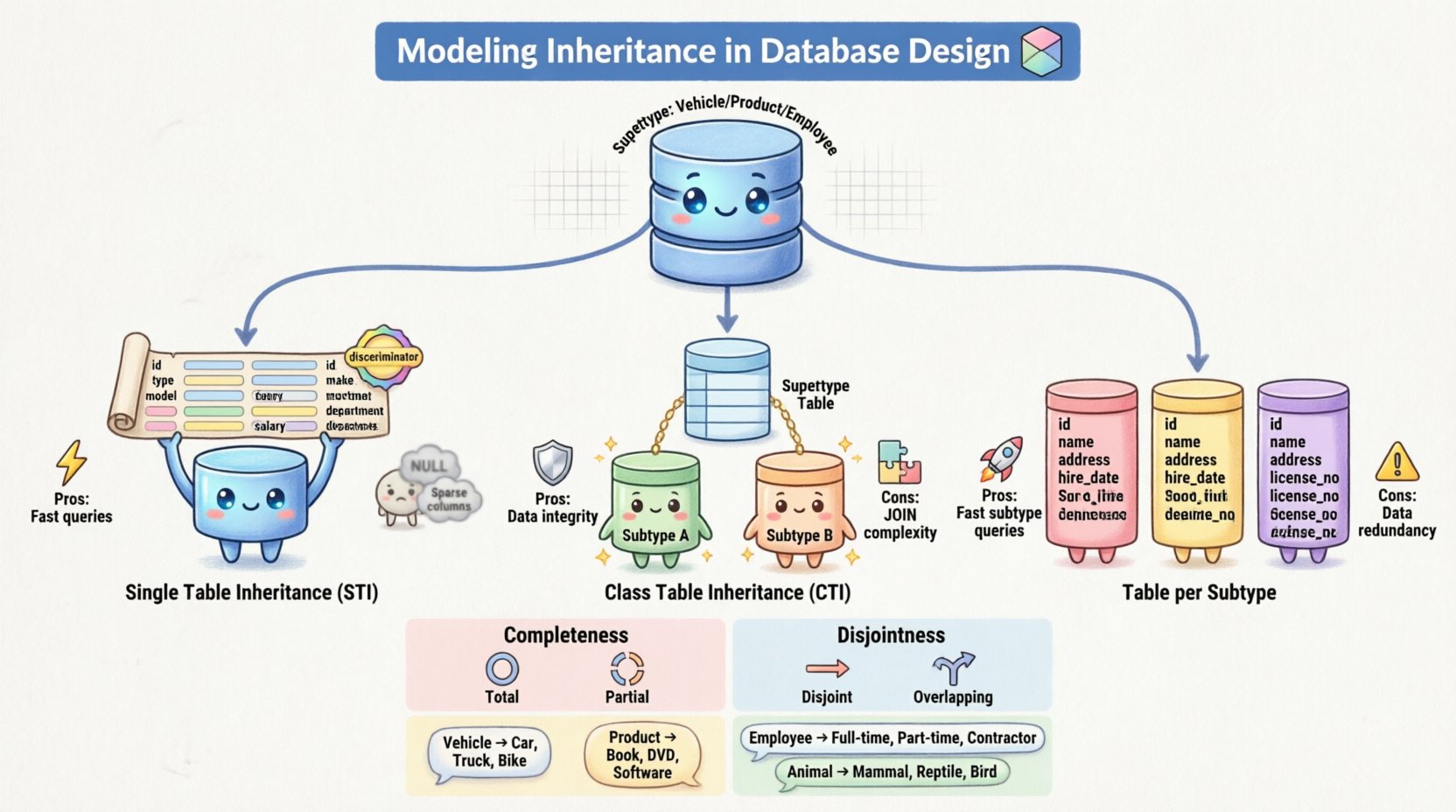
🔑 Основные понятия: супертипы и подтипы
Прежде чем приступать к реализации, мы должны четко определить терминологию. Наследование в моделировании баз данных — это не просто код; это структурное представление данных.
- Супертип: Это родительская сущность. Она содержит атрибуты, общие для всех связанных сущностей. Она представляет общую категорию. Например, Сотрудник может быть супертипом.
- Подтип: Это дочерние сущности. Они наследуют атрибуты от супертипа, но также могут иметь собственные уникальные атрибуты. Примеры включают Менеджер или Разработчик.
- Категория сущности: Супертип иногда называют категорией сущности, объединяя подтипы вместе.
- Дискриминатор: Конкретный атрибут в супертипе, который определяет, к какому подтипу принадлежит экземпляр. Часто используется при физической реализации.
Связь между супертипом и подтипом строгая. Каждый экземпляр подтипа также должен быть экземпляром супертипа. Однако не каждый экземпляр супертипа должен быть экземпляром конкретного подтипа. Это различие критически важно для точности моделирования данных. ✅
📊 Стратегии реализации
Преобразование логической модели ERD в физическую схему базы данных включает в себя конкретные стратегии сопоставления. Существует три основных подхода к представлению наследования в реляционных системах. У каждого из них есть компромиссы в отношении хранения, скорости извлечения и целостности данных. 🛠️
1. Наследование единственной таблицы (STI)
В этом подходе все атрибуты супертипа и всех подтипов объединяются в одной таблице. В таблице содержатся столбцы для каждого атрибута, определенного во всей иерархии. Чтобы различать строки, относящиеся к разным подтипам, добавляется столбец-дискриминатор.
- Плюсы: Очень эффективно для чтения данных. Простой
SELECTизвлекает всю информацию без сложных соединений. - Минусы: Таблица может стать очень широкой с множеством
NULLзначений для атрибутов, которые не относятся к конкретным подтипам. Это также может затруднить обновления, если изменятся ограничения, специфичные для подтипа.
2. Наследование таблиц классов (CTI)
Здесь супертип и каждый подтип отображаются в своих собственных отдельных таблицах. Таблица супертипа содержит общие атрибуты и первичный ключ. Каждая таблица подтипа содержит уникальные атрибуты и внешний ключ, ведущий обратно к первичному ключу супертипа.
- Плюсы: Высокая нормализация. Нет
NULLзначений для неприменимых атрибутов. Строго обеспечивает целостность ссылок. - Минусы: Получение данных требует нескольких операций
JOINопераций, что может повлиять на производительность при работе с большими наборами данных. Это также усложняет операцииINSERTпоскольку данные должны быть записаны в несколько таблиц.
3. Таблица на подтип (наследование конкретных таблиц)
Этот подход создает таблицу для каждого подтипа, включая супертип. Однако каждая таблица подтипа содержит копию атрибутов супертипа. Прямой связи с центральной таблицей супертипа нет.
- Плюсы: Выполнение запросов к конкретному подтипу очень быстрое, так как вся информация находится в одном месте. Это избегает проблемы с
NULLпроблемой STI. - Минусы: Избыточность данных. Если общий атрибут изменяется в супертипе, его необходимо обновить во всех таблицах подтипов. Это увеличивает риск несогласованности данных.
⚖️ Ограничения на наследование
Не все отношения наследования одинаковы. Мы должны определить ограничения, регулирующие, как экземпляры связаны со своими типами. Эти ограничения обеспечивают логичность и согласованность данных. 📝
Ограничение полноты
Это ограничение определяет, должен ли каждый экземпляр супертипа принадлежать к подтипу.
- Полное: Каждый экземпляр супертипа должен быть членом хотя бы одного подтипа. Не существует «общих» экземпляров. Например, каждый Животное должен быть либо Млекопитающим либо Птицей.
- Частичное: Экземпляр супертипа не обязательно должен принадлежать к какому-либо подтипу. Он может существовать как общая сущность. Это часто встречается, когда иерархия используется для категоризации, а не строгой классификации.
Ограничение непересечения
Это ограничение определяет, может ли экземпляр одновременно принадлежать нескольким подтипам.
- Непересекающееся: Экземпляр может принадлежать только к одному подтипу. Он не может быть одновременно Менеджером и Разработчиком одновременно в рамках этой модели.
- Пересечение: Экземпляр может принадлежать более чем одному подтипу. Это позволяет создавать сложные роли, при которых Сотрудник может занимать несколько должностей или классификаций.
Сочетание этих ограничений приводит к четырем различным сценариям моделирования. Понимание того, какой сценарий соответствует вашей бизнес-логике, критически важно перед созданием схемы. 🧠
| Тип ограничения | Определение | Пример сценария |
|---|---|---|
| Непересекающиеся + полные | Только одна подтип, без универсальных экземпляров | Статус заказа: ожидает, отправлен, доставлен |
| Непересекающиеся + частичные | Только один подтип, необязательный подтип | Клиент: VIP или обычный (некоторые — ни то, ни другое) |
| Пересекающиеся + полные | Разрешено несколько подтипов, должен принадлежать только одному | Роль пользователя: администратор и редактор (должен иметь хотя бы одну) |
| Пересекающиеся + частичные | Разрешено несколько подтипов, необязательно | Товар: продаваемый, рекламный (может быть и тем, и другим, или ни тем, ни другим) |
🔍 Поиск и извлечение данных
Выбор стратегии сопоставления значительно влияет на то, как вы пишете запросы. В нормализованной среде вам часто нужно проходить по иерархии, чтобы получить полную картину сущности. 🔎
- Извлечение данных подтипа: Если вам нужно получить доступ к атрибутам, специфичным для подтипа, вы должны выполнить соединение с таблицей подтипа. Это стандартно для наследования по таблице классов.
- Извлечение данных надтипа: Если вам нужны общие атрибуты, вы можете напрямую запросить таблицу надтипа.
- Полиморфные запросы: При запросе всех экземпляров независимо от подтипа самый быстрый подход — использование одной таблицы. Однако при использовании нескольких таблиц вам нужно использовать
ОБЪЕДИНЕНИЕоперации или сложные соединения.
Учитывайте последствия производительности. Запрос, который соединяет пять таблиц для получения одного записей, может быть медленнее, чем запрос к одной денормализованной таблице. Однако денормализованная таблица может нарушать правила нормализации, что приводит к аномалиям обновления. Сбалансированное рассмотрение этих факторов — важная часть проектирования схемы. ⚖️
🛠️ Обслуживание и эволюция
Схемы не являются статичными. Требования бизнеса меняются, и структура базы данных должна меняться вместе с ними. Моделирование наследования обеспечивает гибкость, но также вводит сложность при обслуживании. 🔄
Добавление новых подтипов
Добавление нового подтипа обычно несложно. Вы создаете новую таблицу (в CTI) или новое значение в столбце-дискриминаторе (в STI). Однако вы должны убедиться, что существующие запросы и логика приложения учитывают новый тип. Несвоевременное обновление кода может привести к ошибкам во время выполнения.
Изменение атрибутов надтипа
Если вы добавляете атрибут к надтипу, он должен быть отражен во всех таблицах подтипов при использовании CTI или таблицы на подтип. В STI вы добавляете его один раз в единственную таблицу. Это делает STI проще для обслуживания при общих изменениях, но сложнее — при специфических изменениях.
Миграция данных
Переработка модели наследования — это серьезное мероприятие. Переход от одной таблицы к нормализованной структуре требует переноса данных между несколькими таблицами. Этот процесс должен быть тщательно контролируем, чтобы избежать потери или повреждения данных. 🚧
📈 Нормализация и наследование
Моделирование наследования тесно взаимодействует с нормализацией базы данных. Цель нормализации — сократить избыточность и улучшить целостность данных. Наследование иногда может противоречить этим целям, если не обрабатываться правильно.
- Первое нормальное состояние (1NF): Модели наследования, как правило, соответствуют 1NF, поскольку атрибуты атомарны.
- Второе нормальное состояние (2NF): В STI таблица может содержать атрибуты, которые не полностью зависят от первичного ключа, если дискриминатор не входит в ключ. Это требует тщательного проектирования ключа.
- Третье нормальное состояние (3NF): В CTI разделение атрибутов на таблицы подтипов часто помогает достичь 3NF за счёт устранения транзитивных зависимостей.
При проектировании супертипов убедитесь, что общие атрибуты действительно являются общими. Если атрибут используется только одним подтипом, он, скорее всего, не должен находиться в супертипе. Это предотвращает превращение супертипа в «божественную таблицу», которую сложно использовать в запросах. 👁️
🎯 Лучшие практики проектирования схемы
Чтобы убедиться, что ваша модель наследования останется поддерживаемой и производительной, следуйте этим рекомендациям.
- Ограничьте глубину: Избегайте глубоких иерархий. Обычно рекомендуется не более трёх уровней наследования. За этим пределом сложность запросов и обслуживания превышает выгоды.
- Используйте понятные имена: Имена должны отражать иерархию. Транспортное средство, Автомобиль, Грузовик — это понятно. Сущность1, Сущность2 — нет.
- Планируйте рост: Учитывайте будущие подтипы. Если вы ожидаете много новых подтипов, одна таблица может стать неподъёмной. Если ожидается мало — CTI может быть лучше.
- Документируйте ограничения: Чётко документируйте ограничения на непересечение и полноту. Будущие разработчики должны знать, может ли экземпляр принадлежать нескольким подтипам.
- Стратегия индексации: Если используется CTI, индексируйте столбцы внешних ключей в таблицах подтипов, чтобы ускорить соединения. Если используется STI, индексируйте столбец-дискриминатор для фильтрации.
🧪 Реальные сценарии
Рассмотрим, как это применяется к реальным задачам моделирования данных.
Сценарий 1: Человеческие ресурсы
В системе управления персоналом у вас есть Человек как супертип. Подтипы включают Сотрудник, Подрядчик, и Стажер. У каждого подтипа есть уникальные данные: Сотрудник имеет идентификатор зарплатной ведомости, Подрядчик имеет ставку оплаты. Таблица Человек хранит имя и адрес. Это хорошо соответствует модели наследования классов таблиц.
Сценарий 2: Управление запасами
Рассмотрим каталог товаров. Товар является супертипом. Подтипы — это Электроника, Мебель, и Одежда. Электроника имеет Срок гарантии. Одежда имеет Размер и Цвет. Если вы запрашиваете все товары с гарантией, необходимо выполнить соединение таблицы Electronics. Это подчеркивает компромисс производительности запросов. 🔍
Сценарий 3: Финансовые операции
В банковской системе Счет является супертипом. Подтипы — это Сбережения, Текущий, и Заем. Счет Сбережения имеет процентную ставку. Счет Заем имеет дату погашения. В этом сценарии часто выгодно использовать подход единой таблицы для упрощения расчетов баланса по всем типам счетов.
🚀 Соображения производительности
Производительность часто является определяющим фактором при выборе стратегии сопоставления. Большие наборы данных усиливают различия между подходами.
- Производительность записи: STI самая быстрая для вставок, потому что это одна операция
ВСТАВИТЬоператора. CTI требует несколькихВСТАВИТЬоператоры, что увеличивает накладные расходы транзакции. - Производительность чтения: Если вы часто запрашиваете конкретные подтипы, CTI быстрее, чем STI, потому что вы читаете только соответствующие столбцы. Если вы запрашиваете все экземпляры, STI быстрее.
- Хранение: STI использует больше места из-за
NULLзаполнения. CTI использует больше места из-за дублирования первичных и внешних ключей, но меньше из-за отсутствияNULLзаполнения.
Необходимо профилировать ваше приложение. Теоретическая производительность не всегда соответствует реальным паттернам использования. Только тестирование с реалистичными объемами данных позволит подтвердить ваш выбор. 📊
🛡️ Целостность данных и проверка
Поддержание целостности данных в модели наследования требует строгих правил проверки. Вам необходимо убедиться, что данные, вводимые в таблицу подтипа, соответствуют ограничениям супертипа.
- Ограничения внешнего ключа: Убедитесь, что строки подтипа всегда связаны с действительными строками супертипа. Это предотвращает появление «сиротских» данных.
- Ограничения проверки: Используйте ограничения проверки для соблюдения бизнес-правил. Например, убедитесь, что Процентная ставка в подтипе Сбережения никогда не бывает отрицательной.
- Триггеры: В некоторых сложных сценариях базовые триггеры могут быть необходимы для поддержания согласованности между таблицами во время обновлений.
Автоматическое тестирование должно охватывать сценарии наследования. Убедитесь, что создание нового экземпляра подтипа правильно обновляет супертип. Убедитесь, что удаление экземпляра супертипа корректно каскадируется на подтипы, если это предполагаемое поведение. 🧪
📝 Заключительные соображения
Моделирование наследования — это баланс между гибкостью и сложностью. Не существует единственно правильного способа сделать это. Лучший выбор зависит от ваших конкретных паттернов доступа к данным, бизнес-правил и требований к производительности.
- Начните с четкого понимания домена. Сначала определите сущности, прежде чем беспокоиться о таблицах.
- Выберите стратегию сопоставления, которая соответствует вашим наиболее частым запросам.
- Документируйте свои решения. Будущее обслуживание будет зависеть от этой документации.
- Периодически пересматривайте схему. По мере развития бизнеса модель может потребовать изменений.
Тщательно проектируя супертипы и подтипы, вы создаете базу данных, которая является надежной, масштабируемой и легко понятной. Эта основа поддерживает приложения, которые на нее полагаются, обеспечивая долгосрочную стабильность и эффективность. 🏗️