











Проектирование базы данных — это не просто хранение данных; это структурирование информации таким образом, чтобы обеспечить целостность, сократить избыточность и оптимизировать производительность. Когда речь заходит об эффективных структурах баз данных, выделяются два основных принципа: Диаграммы сущность-связь (ERD) и Нормализация. Эти концепции не являются изолированными методами, а взаимодополняющими инструментами, которые работают вместе для создания надежной основы данных.
В этом руководстве рассматривается, как объединить визуальную ясность ERD с структурной строгостью нормализации. Мы пройдем процесс преобразования концептуальной модели в практическую схему, способную выдержать испытание временем.
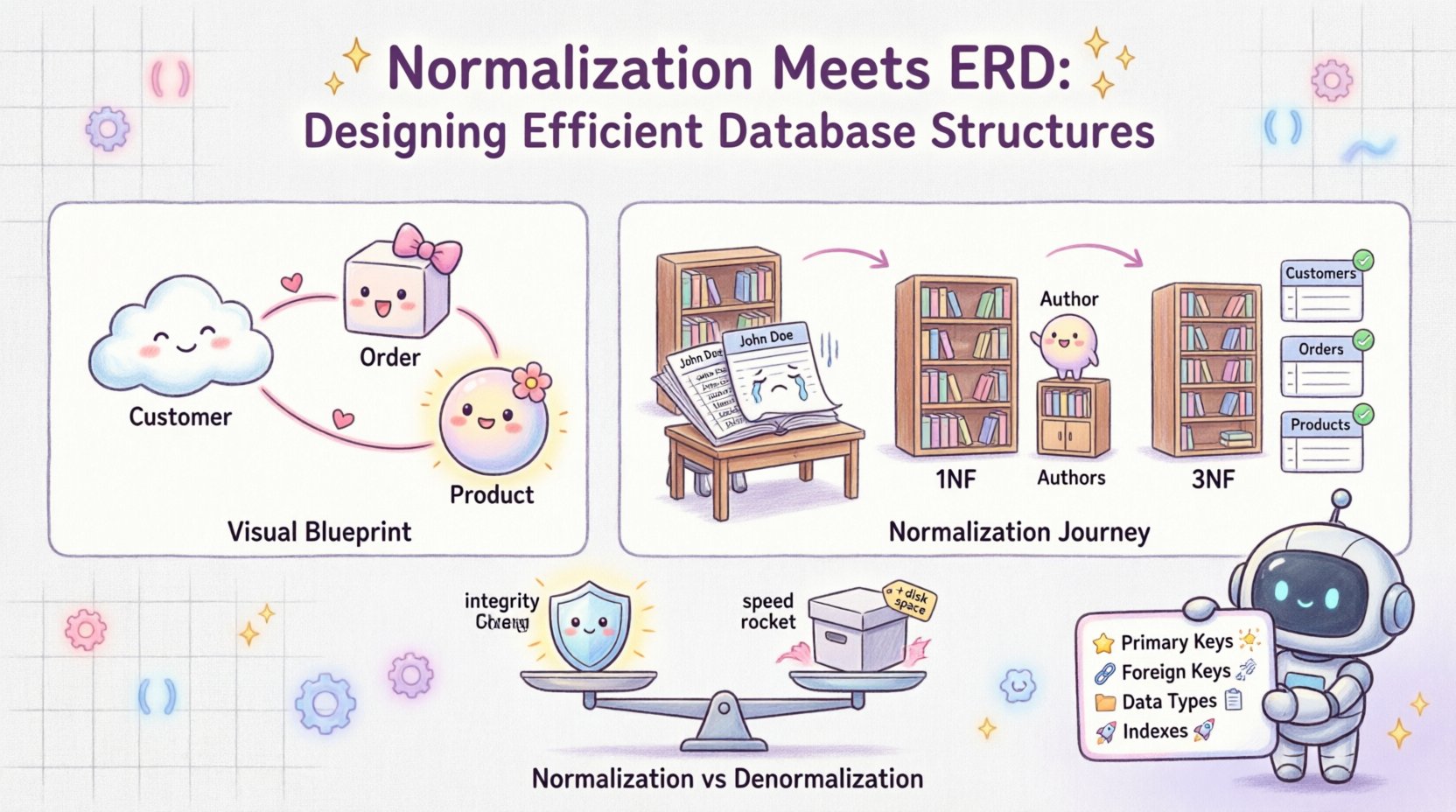
📐 Понимание основы: ERD и нормализация
Прежде чем приступать к процессу проектирования, необходимо понимать различную роль этих двух методологий.
📊 Что такое диаграмма сущность-связь?
Диаграмма сущность-связь служит визуальным чертежом базы данных. Она отображает сущности (таблицы), атрибуты (столбцы) и отношения (связи) между ними. Представьте её как архитектурный чертеж здания. Она отвечает на вопросы, такие как:
- Каковы основные объекты в нашей системе? (например, Клиент, Заказ)
- Как эти объекты взаимодействуют? (например, один Клиент делает множество Заказов)
- Какие данные нам нужно хранить для каждого объекта? (например, Клиент должен иметь Имя и Электронную почту)
Без ERD проектирование базы данных превращается в угадывание. Она предоставляет общий взгляд, который могут понять заинтересованные стороны, обеспечивая согласие всех сторон по требованиям к данным до написания первого фрагмента кода.
🧼 Что такое нормализация?
Нормализация — это процесс организации данных в базе данных для уменьшения избыточности и повышения целостности данных. Она включает разделение больших таблиц на более мелкие логические структуры и определение отношений между ними. Цель заключается в том, чтобы каждый фрагмент данных хранился в одном и только одном месте.
Почему это важно?
- Целостность данных: Если адрес клиента изменится, вы обновите его в одном месте, а не в десяти.
- Эффективность хранения: Меньше дублирующих данных означает меньшее использование дискового пространства.
- Обслуживание: Легче поддерживать и обновлять схему с течением времени.
⚙️ Пересечение: объединение ERD с нормализацией
Проектирование базы данных часто начинается с ERD, но исходный ERD редко готов к производству. Он часто содержит избыточность, которую устраняет нормализация. Процесс включает создание концептуального ERD, анализ его на наличие аномалий и применение правил нормализации для уточнения схемы.
Вот типичный рабочий процесс:
- Концептуальное проектирование: Нарисуйте начальный ERD на основе требований.
- Логическое проектирование: Уточните ERD, превратив его в таблицы и столбцы.
- Нормализация: Примените формы нормализации (1НФ, 2НФ, 3НФ) для устранения аномалий.
- Физическое проектирование: Оптимизируйте под конкретную СУБД и потребности в производительности.
🔍 Пошагово: от ERD к нормализованной схеме
Рассмотрим практический сценарий, чтобы увидеть, как это работает на практике. Представьте, что мы создаем систему для управления библиотекой.
1. Состояние без нормализации
Сначала вы можете спроектировать одну таблицу для хранения всей информации о книгах и авторах. Это называется таблицей без нормализации.
| BookID | Название | Имя автора | Телефон автора | Жанр |
|---|---|---|---|---|
| 101 | Великий роман | Джон Доу | 555-0101 | Художественная литература |
| 102 | Книга загадок | Джон Доу | 555-0101 | Загадка |
| 103 | Еще одна книга | Джейн Смит | 555-0102 | Художественная литература |
Обратите внимание на проблемы здесь? Джон Доуномер телефона повторяется. Если он изменит свой номер, вам нужно будет обновить несколько строк. Это Аномалия обновления.
2. Первая нормальная форма (1NF)
Первое правило нормализации — обеспечить атомарность. Каждый столбец должен содержать только одно значение, и не должно быть повторяющихся групп.
- Правило: Устраните повторяющиеся группы и обеспечьте атомарные значения.
- Применение: В нашем примере библиотеки начальная таблица может уже быть атомарной, но мы должны убедиться, что у нас есть первичный ключ. Допустим, что BookID является уникальным.
- Результат: У нас теперь есть таблица, в которой каждая ячейка содержит одно значение данных.
3. Вторая нормальная форма (2NF)
Как только таблица находится в 1NF, мы проверяем наличие частичных зависимостей. Таблица находится во 2NF, если она находится в 1NF и каждая атрибут, не являющийся ключом, полностью зависит от первичного ключа.
- Сценарий: Если бы у нас был составной ключ (например, BookID + AuthorID), мы проверили бы, зависит ли AuthorPhone зависит от всего ключа или только от части, связанной с автором.
- Действие: В нашем примере AuthorPhone зависит от AuthorName, а не от BookID. Это означает, что мы должны разделить данные об авторе и данных о книге.
4. Третья нормальная форма (3NF)
Вот где происходит настоящее волшебство. 3NF устраняет транзитивные зависимости. Атрибуты, не являющиеся ключевыми, не должны зависеть от других атрибутов, не являющихся ключевыми.
- Правило: Ни один атрибут не должен зависеть от другого атрибута, не являющегося ключевым.
- Применение: AuthorPhone зависит от AuthorName. Поскольку AuthorName не является первичным ключом таблицы книг, мы переносим информацию об авторе в отдельную Authors таблицу.
- Результат: Теперь изменение номера телефона автора требует изменения только одной записи в таблице Авторы таблице, а не нескольких записей в таблице Книги таблице.
📋 Нормализация против денормализации: поиск баланса
Хотя нормализация критически важна для целостности данных, она не всегда является решением для производительности. Иногда чтение данных происходит чаще, чем запись. В таких случаях денормализация может быть полезной.
📉 Когда следует денормализовать
Денормализация предполагает добавление избыточных данных в нормализованную базу данных для улучшения производительности чтения. Это компромисс между объемом хранилища и скоростью.
- Высокий объем чтения: Если ваше приложение выполняет запросы к данным тысячи раз в секунду, объединение таблиц может замедлить производительность.
- Панели отчетов: Агрегированные данные могут быть заранее рассчитаны и сохранены, чтобы избежать сложных запросов.
- Стратегии кэширования: Иногда денормализованные представления выступают в качестве кэша для часто используемых данных.
Однако это сопряжено с рисками. Вам необходимо вручную или с помощью триггеров управлять синхронизацией избыточных данных. Если это не будет сделано аккуратно, страдает целостность данных.
| Фактор | Нормализация | Денормализация |
|---|---|---|
| Целостность данных | Высокая (единственный источник истины) | Ниже (требуется логика синхронизации) |
| Скорость записи | Медленнее (множество таблиц) | Быстрее (меньше соединений) |
| Скорость чтения | Медленнее (множество соединений) | Быстрее (меньше соединений) |
| Хранение | Эффективный | Избыточный |
🛠️ Распространённые ошибки при проектировании баз данных
Даже опытные дизайнеры допускают ошибки. Избегайте этих распространённых ловушек, чтобы обеспечить здоровое состояние структуры вашей базы данных.
❌ Пренебрежение типами данных
Выбор неправильного типа данных может привести к избыточному использованию памяти и проблемам производительности. Использование текстового поля для дат или целых чисел для номеров телефонов приводит к потере памяти и усложнению проверки данных.
❌ Избыточная нормализация
Стремление к 5НФ или БКНФ (форма Бойса-Кодда) во всех случаях может сделать запросы невероятно сложными. Иногда достаточно 3НФ. Не нормализуйте просто ради нормализации.
❌ Слабые первичные ключи
Использование естественных ключей (например, адресов электронной почты) в качестве первичных ключей может быть рискованным при изменении данных. Внешние ключи (автоинкрементные целые числа или UUID) часто безопаснее для внутренних связей.
❌ Отсутствие индексов
Хорошо нормализованная схема может по-прежнему работать медленно без правильного индексирования. Определите столбцы, которые часто используются в WHERE, JOIN, или ORDER BYусловиях и проиндексируйте их.
🔄 Итеративный процесс проектирования
Проектирование базы данных редко бывает линейным. Это итеративный процесс. Вы можете начать с диаграммы «сущность-связь», нормализовать её, понять, что возникли проблемы с производительностью, немного денормализовать и затем снова вернуться к диаграмме «сущность-связь», чтобы убедиться, что связи остаются корректными.
🔄 Этапы уточнения
- Проверка требований:Требуются ли новые таблицы для новых функций?
- Анализ запросов: Посмотрите на самые медленные запросы и определите узкие места.
- Проверка ограничений: Убедитесь, что внешние ключи правильно определены, чтобы избежать появления «сиротских» записей.
- Документирование: Держите свою диаграмму «сущность-связь» в актуальном состоянии. Устаревшая диаграмма хуже, чем отсутствие диаграммы.
📈 Соображения по производительности
Нормализация в первую очередь решает вопросы целостности данных. Производительность — это отдельный вопрос, который часто требует настройки. Однако эти два аспекта взаимосвязаны.
🚀 Сложность JOIN-операций
Высоко нормализованные базы данных требуют больше JOINопераций для получения связанных данных. Современные движки баз данных очень хорошо оптимизируют JOIN-операции, но чрезмерное количество JOIN-операций всё ещё может повлиять на задержку.
📦 Движок хранения
Разные движки хранения обрабатывают данные по-разному. Некоторые предпочитают хранение по строкам, другие — по столбцам. Ваша стратегия нормализации может потребовать адаптации в зависимости от используемого движка.
🔒 Ограничения и триггеры
Применение правил нормализации через ограничения (например, внешние ключи) обеспечивает качество данных. Однако чрезмерное использование триггеров для проверки может замедлить операции записи. Используйте их с умом.
🧩 Реальный пример: система заказов электронной коммерции
Рассмотрим чуть более сложный сценарий: интернет-магазин.
Исходная концепция ERD
Сначала у вас может быть таблица Orderтаблица, включающая названия продуктов, цены и данные о клиентах. Это классический подход «плоского файла».
Подход с нормализацией
Чтобы исправить это, мы разделим данные:
- Таблица клиентов: Хранит данные о клиентах (Имя, Адрес, Электронная почта).
- Таблица продуктов: Хранит данные о продуктах (Название, Цена, Остаток).
- Таблица заказов: Хранит информацию о транзакции (CustomerID, Дата заказа, Сумма).
- Таблица элементов заказа: Связывает заказы и продукты (OrderID, ProductID, Количество, Цена на момент заказа).
Эта структура позволяет нам:
- Обновлять цену продукта в одном месте (в таблице Products таблице).
- Отслеживание исторических цен в таблице OrderItems таблица (снимок).
- Убедитесь, что клиент не может быть удален, если у него есть открытые заказы (через внешние ключи).
🎯 Чек-лист лучших практик
Перед развертыванием вашей схемы пройдитесь по этому чек-листу, чтобы обеспечить качество.
- ✅ Первичные ключи: У каждой таблицы есть уникальный идентификатор.
- ✅ Внешние ключи: Связи явно определены.
- ✅ Допустимость NULL: Столбцы помечены как
НЕ NULLгде это уместно. - ✅ Типы данных: Используйте наиболее конкретный тип данных, который возможно.
- ✅ Соглашения об именовании: Используйте последовательные, понятные имена для таблиц и столбцов.
- ✅ Документация: ERD соответствует физической схеме.
- ✅ Стратегия резервного копирования: Учитывайте, как схема влияет на время резервного копирования и восстановления.
🔮 Будущее проектирования баз данных
По мере развития технологий основные принципы нормализации и диаграмм сущность-связь остаются актуальными. Несмотря на то, что базы данных NoSQL предлагают гибкость, реляционная модель по-прежнему доминирует в транзакционных системах. Понимание основ позволяет адаптироваться к новым технологиям, не теряя дисциплины моделирования данных.
Облачные базы данных вводят новые измерения, такие как шардирование и партиционирование. Однако логическая структура, которую вы проектируете с использованием диаграмм сущность-связь и нормализации, остаётся чертежом, по которому распределяется и доступ к данным.
📝 Краткое резюме ключевых выводов
Проектирование эффективных структур баз данных — это баланс между структурой и гибкостью. Вот что следует помнить:
- Диаграммы сущность-связь — это визуальные руководства: Они отображают связи до начала построения.
- Нормализация — это структурный процесс: Она организует данные для уменьшения избыточности.
- 3НФ — это цель:Стремитесь к третьей нормальной форме для большинства транзакционных систем.
- Денормализуйте с умом: Добавляйте избыточность только тогда, когда это требует производительность.
- Итерируйте: Проектирование никогда не заканчивается; оно развивается вместе с приложением.
Объединяя визуальную ясность диаграмм сущность-связь с строгими правилами нормализации, вы создаете основу данных, которая одновременно надежна и масштабируема. Такой подход гарантирует, что ваша база данных сможет расти вместе с приложением, справляясь со сложностью без нарушения целостности.
Начните с чистой диаграммы сущность-связь. Пошагово применяйте правила нормализации. Тестируйте свои запросы. Уточняйте схему. И всегда ставьте целостность данных выше скорости на ранних этапах.