











Создание системы базы данных похоже на строительство фундамента небоскреба. Если чертеж содержит ошибки, сооружение в конечном итоге треснет под давлением. Диаграмма сущностей и отношений (ERD) — это и есть чертеж. Она определяет, как данные соединяются, перемещаются и сохраняются в вашем приложении. По мере роста числа пользователей и объема данных статическая архитектура часто становится узким местом. Чтобы обеспечить долговечность, необходимо с самого начала применять принципы масштабируемого проектирования ERD. В этом руководстве рассматриваются технические стратегии, необходимые для создания систем, способных выдержать испытания временем.
Понимание основ моделирования данных 🧱
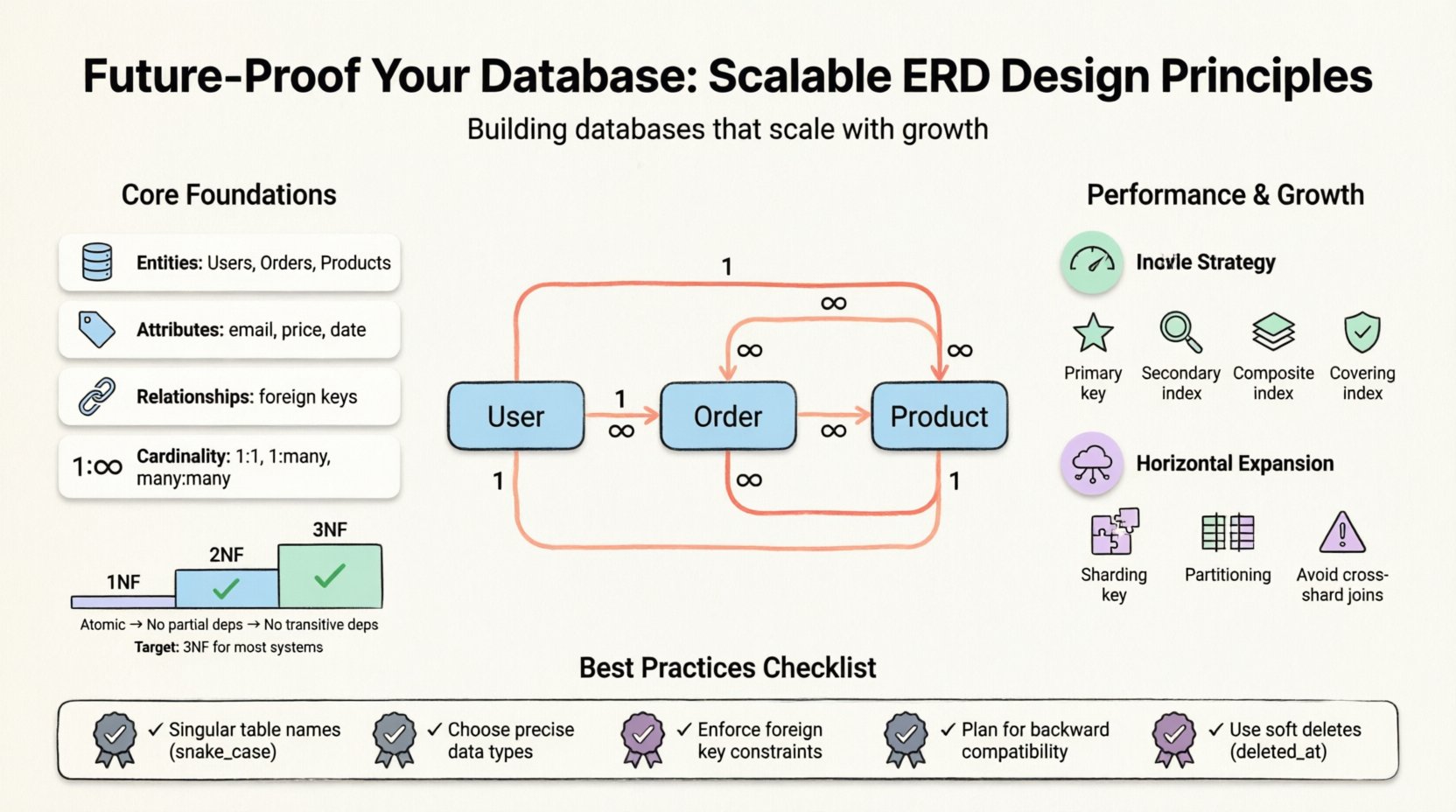
Прежде чем приступать к конкретным тактикам, необходимо понять, что представляет собой ERD. Он визуализирует логическую структуру базы данных. Он отображает сущности (таблицы), атрибуты (столбцы) и отношения (ключи). Хорошо продуманная модель обеспечивает баланс между целостностью данных и производительностью. Однако «наилучшая практика» зависит от характера нагрузки. Приложение, ориентированное на чтение, требует другой оптимизации, чем транзакционная система, ориентированная на запись.
Ключевые компоненты включают:
- Сущности: Основные объекты, такие как Пользователи, Заказы или Товары.
- Атрибуты: Свойства, определяющие сущность, например, электронные адреса или цены.
- Отношения: Как сущности взаимодействуют между собой, как правило, определяемые внешними ключами.
- Мощность: Числовое отношение между сущностями (один к одному, один ко многим, многие ко многим).
Нормализация: Баланс между избыточностью и скоростью ⚖️
Нормализация — это процесс организации данных для уменьшения избыточности и повышения целостности. Хотя её часто рассматривают как строгое правило, на самом деле это компромисс. Высокая нормализация минимизирует аномалии, но может увеличить сложность запросов за счёт соединений. Низкая нормализация (денормализация) ускоряет чтение, но повышает риск несогласованности данных.
Уровни нормализации
Понимание стандартных форм помогает определить, где остановиться. Каждая форма решает определённые аномалии данных.
- Первое нормальное состояние (1NF): Обеспечивает атомарность. Каждый столбец должен содержать неделимые значения. Нет повторяющихся групп или массивов в одной ячейке.
- Второе нормальное состояние (2NF): Опирается на 1NF. Все атрибуты, не являющиеся ключевыми, должны зависеть от всего первичного ключа, а не только от его части. Это устраняет частичные зависимости.
- Третье нормальное состояние (3NF): Опирается на 2NF. Атрибуты, не являющиеся ключевыми, не должны зависеть от других атрибутов, не являющихся ключевыми. Это устраняет транзитивные зависимости.
- Форма Бойса-Кодда (BCNF): Более строгая версия 3NF. Она решает случаи, когда определяющие элементы не являются кандидатскими ключами.
Для большинства масштабируемых систем достижение 3NF — это стандартная цель. Дальнейшее продвижение часто даёт убывающую отдачу при увеличении нагрузки на обслуживание. Однако для систем, ориентированных на анализ, контролируемый возврат к денормализации — распространённая практика.
Таблица компромиссов при нормализации
| Уровень нормализации | Основное преимущество | Основной недостаток |
|---|---|---|
| 1НФ | Атомарное хранение данных | Нет |
| 2НФ | Устраняет частичные зависимости | Требуется больше соединений |
| 3НФ | Устраняет транзитивные зависимости | Увеличение сложности соединений |
| Денормализовано | Быстрые запросы на чтение | Избыточность данных и аномалии обновления |
Проектирование схемы для роста и гибкости 📈
Проектирование только для настоящего недостаточно. Вам нужно предвидеть будущее развитие схемы. Жесткие структуры ломаются при изменении бизнес-логики. Гибкое проектирование позволяет расширять систему без необходимости полной миграции системы.
1. Правила именования и стандарты
Согласованность имеет решающее значение для поддержки. Хаотичная система именования приводит к путанице и ошибкам. Установите стандарт на раннем этапе и соблюдайте его в команде.
- Используйте единственное число:Таблицы должны представлять одно существо (например,
пользователь, а непользователи). - Согласованные разделители:Используйте snake_case для имен таблиц и столбцов, чтобы обеспечить совместимость с различными операционными системами и инструментами.
- Префиксы для конкретности:Используйте префиксы, такие как
fk_для внешних ключей илиidx_для индексов, чтобы их назначение было очевидным. - Избегайте зарезервированных слов: Никогда не используйте ключевые слова, такие как
order,group, илиselectв качестве имён столбцов.
2. Типы данных и точность
Выбор правильного типа данных влияет на объем хранилища и скорость запросов. Слишком общие типы данных тратят место и замедляют обработку.
- Целые числа: Используйте
TINYINTдля флагов (0-1) или небольших количеств. ИспользуйтеBIGINTтолько в том случае, если вы ожидаете огромных масштабов. - Строки: Избегайте
TEXTдля коротких значений. ИспользуйтеVARCHARс конкретной длиной, чтобы сэкономить место и позволить индексирование. - Дата и время: Используйте
TIMESTAMPдля конкретных моментов иDATEтолько для календарных дат. Всегда храните в формате UTC, чтобы избежать путаницы с часовым поясом. - Десятичные числа: Для финансовых данных используйте десятичные числа с фиксированной точкой вместо чисел с плавающей точкой, чтобы избежать ошибок округления.
Управление отношениями и кардинальностью 🔗
Как сущности связаны между собой, определяет целостность ваших данных. Неправильное управление отношениями приводит к несвязанным записям и потере данных.
1. Ограничения внешнего ключа
Внешние ключи обеспечивают целостность ссылок. Они гарантируют, что запись в одной таблице не может ссылаться на несуществующую запись в другой. Хотя некоторые разработчики отключают их для повышения производительности, современные базы данных эффективно справляются с ними. Опора на проверки на уровне приложения является ошибочной.
2. Обработка отношений «многие ко многим»
Отношение «многие ко многим» (например, Студенты и Курсы) не может быть напрямую представлено в двух таблицах. Для этого требуется промежуточная таблица (ассоциативная сущность).
- Создайте новую таблицу, содержащую первичные ключи обеих связанных таблиц.
- Добавьте составной первичный ключ, состоящий из обоих внешних ключей.
- Используйте эту таблицу для хранения дополнительных атрибутов, специфичных для отношения, таких как даты зачисления.
3. Опциональные и обязательные отношения
Четко определите, является ли отношение обязательным. Значение NULLв столбце внешнего ключа указывает на опциональное отношение. Это решение влияет на логику проверки на уровне приложения.
Стратегии индексации для производительности чтения 🏎️
Индексы — основной механизм ускорения извлечения данных. Однако они не бесплатны. Каждый индекс потребляет место на диске и замедляет операции записи (вставки, обновления, удаления).
1. Первичные индексы
Каждая таблица должна иметь первичный ключ. Обычно он кластеризованный, то есть физические данные хранятся в порядке ключа. Выберите ключ, который стабилен и никогда не изменяется. Суррогатные ключи (автоинкрементные целые числа) часто лучше естественных ключей (например, электронные адреса) с точки зрения производительности.
2. Вторичные индексы
Используйте вторичные индексы для оптимизации запросов, фильтрующих или сортирующих по столбцам, не являющимся первичными. Распространённые сценарии включают:
- Поиск по адресу электронной почты.
- Фильтрация по статусу или категории.
- Сортировка результатов по дате.
3. Составные индексы
При запросах по нескольким столбцам составной индекс может быть более эффективным, чем отдельные индексы по одному столбцу. Порядок столбцов в индексе имеет значение. Размещайте наиболее выборочный столбец первым.
4. Покрывающие индексы
Покрывающий индекс включает все столбцы, необходимые для выполнения запроса. Это позволяет базе данных извлекать данные непосредственно из индекса, не обращаясь к основной таблице, что значительно снижает объем ввода-вывода.
Проектирование для горизонтального масштабирования 🌐
Вертикальное масштабирование (добавление мощности к одному серверу) имеет ограничения. В конечном итоге вам необходимо распределить данные между несколькими узлами. Проектирование ERD должно учитывать эту реальность.
1. Ключи шардирования
Шардирование подразумевает разделение данных между несколькими базами данных. Выбор ключа шардирования критически важен. Он должен часто использоваться в запросах для обеспечения локальности данных. Если вы шардируете по “user_id, вы можете легко запросить все данные для этого пользователя на одном узле.
- Хорошие ключи шардирования: Высокая кардинальность, часто используемая в запросах.
- Плохие ключи шардирования: Низкая кардинальность (например,
country_code) или редко используемая.
2. Избегание соединений между шардами
Соединения между разными шардами дорогостоящие и сложные. Проектируйте свою схему так, чтобы минимизировать необходимость в них. Если вам нужны данные из двух сущностей, которые могут находиться на разных шардах, рассмотрите возможность денормализации данных. Храните необходимые данные внешних ключей непосредственно в таблице, чтобы избежать соединения.
3. Разделение
Разделение разделяет большую таблицу на более мелкие, управляемые части. Это можно сделать по диапазону (даты), списку (категории) или хэшу. Это улучшает обслуживание и производительность запросов без значительных изменений в логике приложения.
Эволюция и миграция схемы 🔄
Требования меняются. Новые функции требуют новых столбцов. Старые функции устаревают. Надежная ERD позволяет адаптироваться к изменениям, не нарушая существующей функциональности.
1. Обратная совместимость
При добавлении новых функций убедитесь, что старые клиенты по-прежнему могут работать. Сначала добавьте новые столбцы как разрешённые к NULL. Постепенно заполняйте их. Не удаляйте столбцы сразу; пометьте их как устаревшие и оставьте на время миграции.
2. Версионирование моделей данных
Ведите учёт версий схемы. Это позволяет откатить изменения, если миграция вызовет критические сбои. Используйте скрипты миграции, которые идемпотентны, то есть могут быть выполнены несколько раз без ошибок.
3. Обработка миграции данных
Перемещение больших объёмов данных требует тщательного планирования. Большие блокировки могут заблокировать производственный трафик. Выполняйте миграции в периоды низкой нагрузки или при возможности используйте стратегии развертывания «синий-зелёный».
Распространённые ошибки, которые следует избегать ⚠️
Даже опытные архитекторы допускают ошибки. Осведомлённость о распространённых ошибках помогает избежать их.
- Чрезмерная сложность: Проектирование для масштаба, которого у вас ещё нет. Если вы только начинаете, оставайтесь простыми. Сложность увеличивает стоимость и риски.
- Пренебрежение мягким удалением: Никогда не удаляйте чувствительные записи сразу и навсегда. Используйте метку
deleted_atвременной метки вместо этого. Это сохраняет журналы аудита и позволяет восстановить данные. - Конфликты имён: Использование одного и того же имени для таблицы и столбца создаёт неоднозначность. Придерживайтесь правила единственного числа для таблиц.
- Отсутствуют ограничения:Зависимость исключительно от логики приложения для соблюдения бизнес-правил приводит к повреждению данных. Ограничьте данные на уровне базы данных.
- Пренебрежение безопасностью:Проектирование должно включать поля для контроля доступа. Убедитесь, что управление доступом на основе ролей поддерживается на этапе проектирования схемы.
Окончательные соображения для долговечности 🏁
Создание масштабируемой базы данных — это непрерывный процесс. Требуется мониторинг, анализ и корректировка. Никакой дизайн не идеален при запуске. Цель — создать основу, которую легко модифицировать.
Регулярно проверяйте свои запросы. Выявляйте медленные операции и оптимизируйте лежащую в основе схему. Используйте инструменты профилирования, чтобы понять, как обращаются к вашим данным. Этот цикл обратной связи гарантирует, что ваша архитектура останется эффективной по мере роста данных.
Помните, что технологии развиваются. Появляются новые движки хранения и языки запросов. Гибкая схема лучше адаптируется к этим изменениям, чем жесткая. Сосредоточьтесь на основных отношениях и целостности данных. Они остаются неизменными, даже когда меняются инструменты.
Соблюдая эти принципы, вы создаете устойчивые системы. Они справляются с ростом без проблем и сохраняют производительность при нагрузке. Именно это и есть суть будущего для вашей базы данных.