











建立資料庫系統,就如同建造摩天大樓的地基。如果設計圖有缺陷,結構最終將在壓力下出現裂痕。實體關係圖(ERD)就是這張設計圖。它定義了資料在應用程式中如何連結、流動與儲存。隨著使用者人數增加與資料量爆炸式成長,靜態設計往往會成為瓶頸。為確保系統的長期穩定,您必須從一開始就採用可擴展的ERD設計原則。本指南探討了建立持久系統所需的技術策略。
理解資料模型的核心 🧱
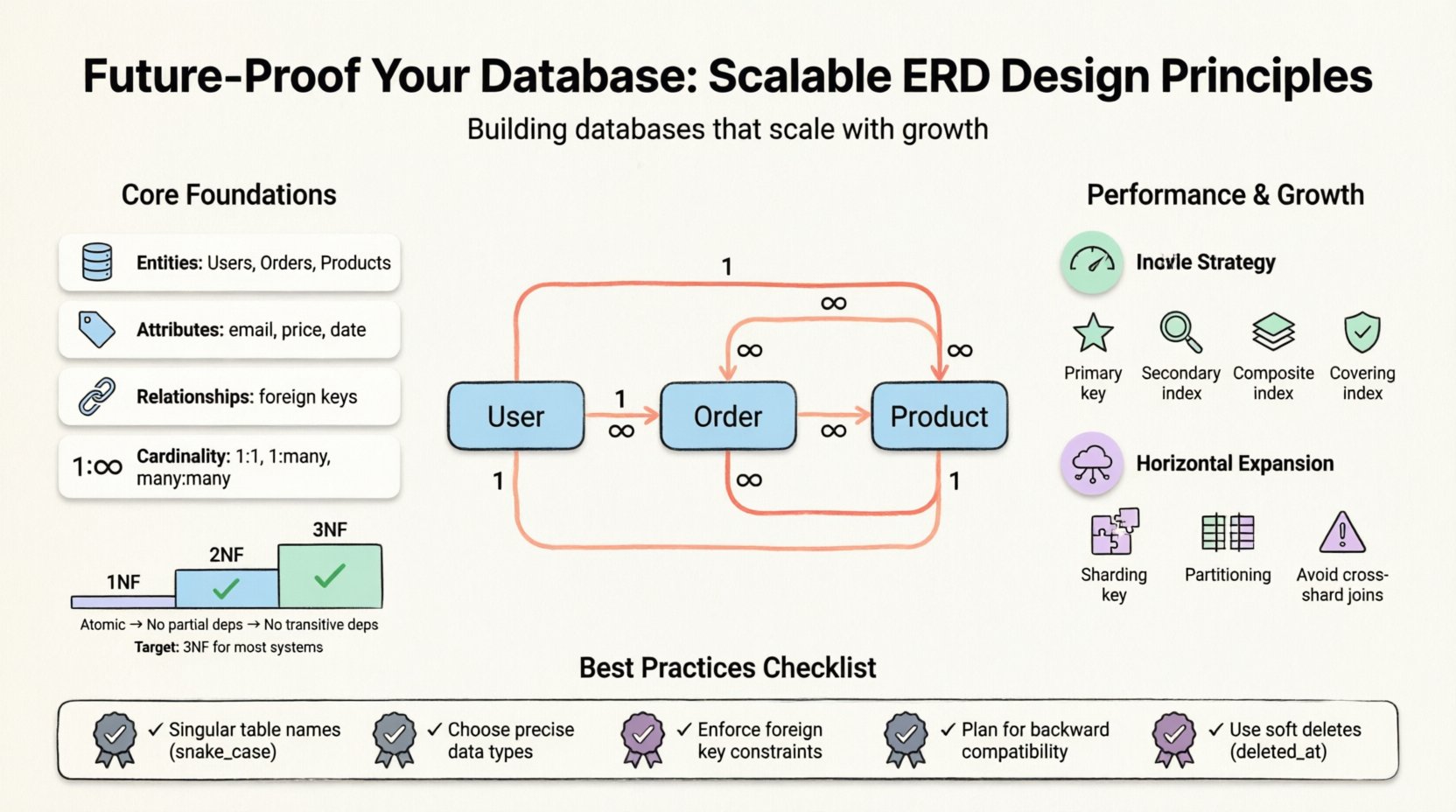
在深入探討具體策略之前,理解ERD所代表的意義至關重要。它能視覺化資料庫的邏輯結構,將實體(資料表)、屬性(欄位)與關係(索引)進行映射。一個精心設計的模型需在資料完整性與效能之間取得平衡。然而,「最佳實務」會因工作負載而異。讀多於寫的應用程式,其優化方式與寫多於讀的交易系統截然不同。
主要元件包括:
- 實體: 主要物件,例如使用者、訂單或產品。
- 屬性: 定義實體的屬性,例如電子郵件地址或價格。
- 關係: 實體之間的互動方式,通常由外鍵定義。
- 基數: 實體之間的數值關係(一對一、一對多、多對多)。
正規化:冗餘與速度之間的平衡 ⚖️
正規化是透過組織資料來減少冗餘並提升完整性的一種過程。雖然常被視為嚴格規則,但其實是一種權衡。高正規化可減少異常情況,但可能因連接操作而增加查詢複雜度。低正規化(反正規化)能加快讀取速度,但可能導致資料不一致。
正規化的層級
理解標準形式有助於您決定何時停止。每一種形式都針對特定的資料異常問題。
- 第一正規化形式(1NF): 確保原子性。每個欄位必須包含不可再分割的值。單元格內不得有重複群組或陣列。
- 第二正規化形式(2NF): 建立在1NF之上。所有非鍵屬性必須依賴整個主鍵,而非僅部分主鍵。這可消除部分依賴。
- 第三正規化形式(3NF): 建立在2NF之上。非鍵屬性不得依賴其他非鍵屬性。這可消除傳遞依賴。
- 博伊斯-科德正規化形式(BCNF): 3NF的更嚴格版本。用於處理決定因素非候選鍵的情況。
對於大多數可擴展系統而言,達到3NF是標準目標。進一步提升正規化層級往往帶來遞減回報,同時增加維護成本。然而,對於以分析為主的系統,適度地回歸反正規化是常見做法。
正規化權衡對照表
| 正規化層級 | 主要優點 | 主要缺點 |
|---|---|---|
| 第一範式 | 原子資料儲存 | 無 |
| 第二範式 | 消除部分相依性 | 需要更多的連接 |
| 第三範式 | 消除傳遞相依性 | 連接複雜度增加 |
| 非規範化 | 更快的讀取查詢 | 資料冗餘與更新異常 |
用於成長與彈性的資料結構設計 📈
僅為當下設計是不夠的。你必須預見未來的資料結構演變。當業務邏輯改變時,僵化的結構會崩潰。彈性設計允許擴展,而無需進行完整的系統遷移。
1. 命名慣例與標準
一致性對於可維護性至關重要。混亂的命名方式會導致混淆與錯誤。應盡早建立標準,並在整個團隊中強制執行。
- 使用單數名稱:資料表應代表單一實體(例如,
使用者,而非使用者們). - 一致的分隔符:使用蛇形命名法(snake_case)命名資料表與欄位,以確保在不同作業系統與工具之間的相容性。
- 使用前置詞以提高明確性:使用如
fk_作為外鍵,或使用idx_作為索引,以清楚表明其用途。 - 避免保留字: 永遠不要使用類似於
order,group,或select作為欄位名稱。
2. 資料類型與精確度
選擇正確的資料類型會影響儲存空間和查詢速度。過於通用的類型會浪費空間並降低處理速度。
- 整數: 使用
TINYINT來表示旗標(0-1)或小數量。僅在預期會有巨大規模時才使用BIGINT。 - 字串: 避免使用
TEXT來儲存短值。使用VARCHAR並指定長度以節省空間並支援索引。 - 日期: 使用
TIMESTAMP來儲存特定時刻,而使用DATE僅用於日曆日期。永遠以 UTC 儲存以避免時區混淆。 - 小數: 針對財務資料,應使用固定精度的小數而非浮點數,以避免四捨五入錯誤。
關係與基數管理 🔗
實體之間的關聯方式決定了資料的完整性。管理不當的關係會導致孤立記錄和資料遺失。
1. 外鍵約束
外鍵強制執行參考完整性。它確保一個表格中的記錄無法引用另一個表格中不存在的記錄。雖然有些開發人員為了性能而禁用這些約束,但現代資料庫引擎能高效處理它們。依賴應用層檢查容易出錯。
2. 處理多對多關係
多對多關係(例如:學生與課程)無法直接在兩個表格中表示,需要一個聯結表格(關聯實體)。
- 建立一個包含兩個相關表格主鍵的新表格。
- 加入一個由兩個外鍵組成的複合主鍵。
- 使用此表格儲存與關係相關的額外屬性,例如註冊日期。
3. 選擇性與必要性關係
明確定義關係是否為必要。一個 NULL外鍵欄位中的「NULL」值表示該關係為選擇性。此決定會影響應用層的驗證邏輯。
用於提升讀取效能的索引策略 🏎️
索引是加速資料檢索的主要機制。然而,它們並非免費的。每個索引都會消耗磁碟空間,並減慢寫入操作(插入、更新、刪除)。
1. 主索引
每個表格都需要主鍵。這通常為叢集索引,表示物理資料依鍵的順序儲存。應選擇穩定且從不更新的鍵。代理鍵(自動遞增的整數)通常比自然鍵(如電子郵件)在效能上更佳。
2. 次要索引
使用次要索引來優化在非主鍵欄位上進行過濾或排序的查詢。常見情境包括:
- 根據電子郵件地址搜尋。
- 根據狀態或分類過濾。
- 依日期排序結果。
3. 複合索引
當根據多個欄位查詢時,複合索引通常比單獨的單欄索引更有效率。索引中欄位的順序很重要,應將選擇性最高的欄位放在最前面。
4. 覆蓋索引
覆蓋索引包含滿足查詢所需的全部欄位。這使得資料庫可以直接從索引中取得資料,無需存取主表格,顯著降低 I/O。
設計以支援水平擴展 🌐
垂直擴展(為單一伺服器增加更多資源)有其限制。最終,您必須將資料分散到多個節點上。ERD 設計必須考慮到這一點現實。
1. 分片鍵
分片是指將資料分散到多個資料庫中。選擇分片鍵至關重要。它應經常出現在查詢中,以確保資料的局部性。如果您按 “user_id,您可以輕鬆地在單個節點上查詢該用戶的所有資料。
- 良好的分片鍵: 高基數,經常出現在查詢中。
- 不良的分片鍵: 低基數(例如,
country_code)或很少使用。
2. 避免跨分片連接
跨不同分片的連接成本高昂且複雜。設計您的資料結構以最小化對此類連接的需求。如果需要來自兩個可能位於不同分片的實體的資料,考慮資料非規範化。將必要的外鍵資料直接儲存在表格中,以避免連接操作。
3. 分區
分區將大型表格拆分為較小且易於管理的片段。可依範圍(日期)、清單(分類)或雜湊方式進行。這能在不顯著改變應用程式邏輯的情況下提升維護效率與查詢效能。
資料結構的演進與遷移 🔄
需求會變更。新功能需要新增欄位。舊功能會被棄用。一個穩健的實體關係圖能容納變更,而不會破壞現有功能。
1. 向後相容性
新增功能時,確保舊版客戶端仍可正常運作。首先將新欄位設為可為空值。逐步填入資料。不要立即刪除欄位;應標記為已棄用,並在遷移期間保留。
2. 資料模型版本控制
追蹤資料結構的版本。這樣可以在遷移導致嚴重失敗時進行回滾。使用冪等的遷移腳本,即可以多次執行而不會造成錯誤。
3. 資料遷移處理
移動大量資料需要仔細規劃。大型鎖定可能會阻擋生產流量。盡可能在流量較低的時段進行遷移,或使用藍綠部署策略。
常見陷阱,應避免 ⚠️
即使經驗豐富的架構師也會犯錯。了解常見錯誤能幫助您避開它們。
- 過度設計: 為尚未達到的規模進行設計。如果剛起步,請保持簡單。複雜性會增加成本與風險。
- 忽略軟刪除: 永遠不要立即永久刪除敏感記錄。使用一個
deleted_at時間戳記代替。這能保留審計追蹤並允許恢復。 - 命名衝突: 使用相同的名稱作為表格與欄位會造成歧義。請遵循單數表格命名規則。
- 缺少約束條件:僅依賴應用程式邏輯來強制執行業務規則會導致資料損壞。應在資料庫層級強制執行約束條件。
- 忽略安全性:設計必須包含存取控制的欄位。確保在資料結構設計階段就支援基於角色的存取控制。
永續性的最終考量 🏁
建立可擴展的資料庫是一個持續的過程。需要監控、分析與調整。沒有任何設計在啟動時是完美的。目標是建立一個容易修改的基礎架構。
定期審查您的查詢。識別執行緩慢的操作並優化底層資料結構。使用剖析工具來了解您的資料是如何被存取的。這個反饋迴圈可確保隨著資料量增加,您的架構仍保持高效。
請記住,技術是不斷演進的。新的儲存引擎與查詢語言不斷出現。彈性的資料結構比僵化的結構更能適應這些變動。專注於核心的關聯性與資料完整性,這些要素即使在工具變更時依然保持不變。
透過遵循這些原則,您將建立具備韌性的系統。它們能穩健應對成長,並在負載下維持性能。這正是為您的資料庫基礎設施做好未來防護的本質。