










設計穩健的資料庫結構需要的不僅僅是列出表格和欄位。它要求對實體之間的關係有深入的理解。在實體-關係圖(ERD)中,最強大但也最複雜的概念之一就是繼承。這種機制使我們能夠模擬現實世界中的層級結構,其中物件共享共同特徵,同時也具有獨特屬性。在資料庫設計的背景下,這轉化為超類型與子類型。🧩
當我們建模繼承時,其實本質上是在捕捉「是一種」的關係。例如,一個車輛是一種產品,而一個汽車是一種車輛。這種層級結構允許我們在較高層級重複使用屬性,同時在較低層級定義特定行為或資料。理解如何在關係型資料庫中實現此結構,對於資料完整性與查詢效能至關重要。🗄️
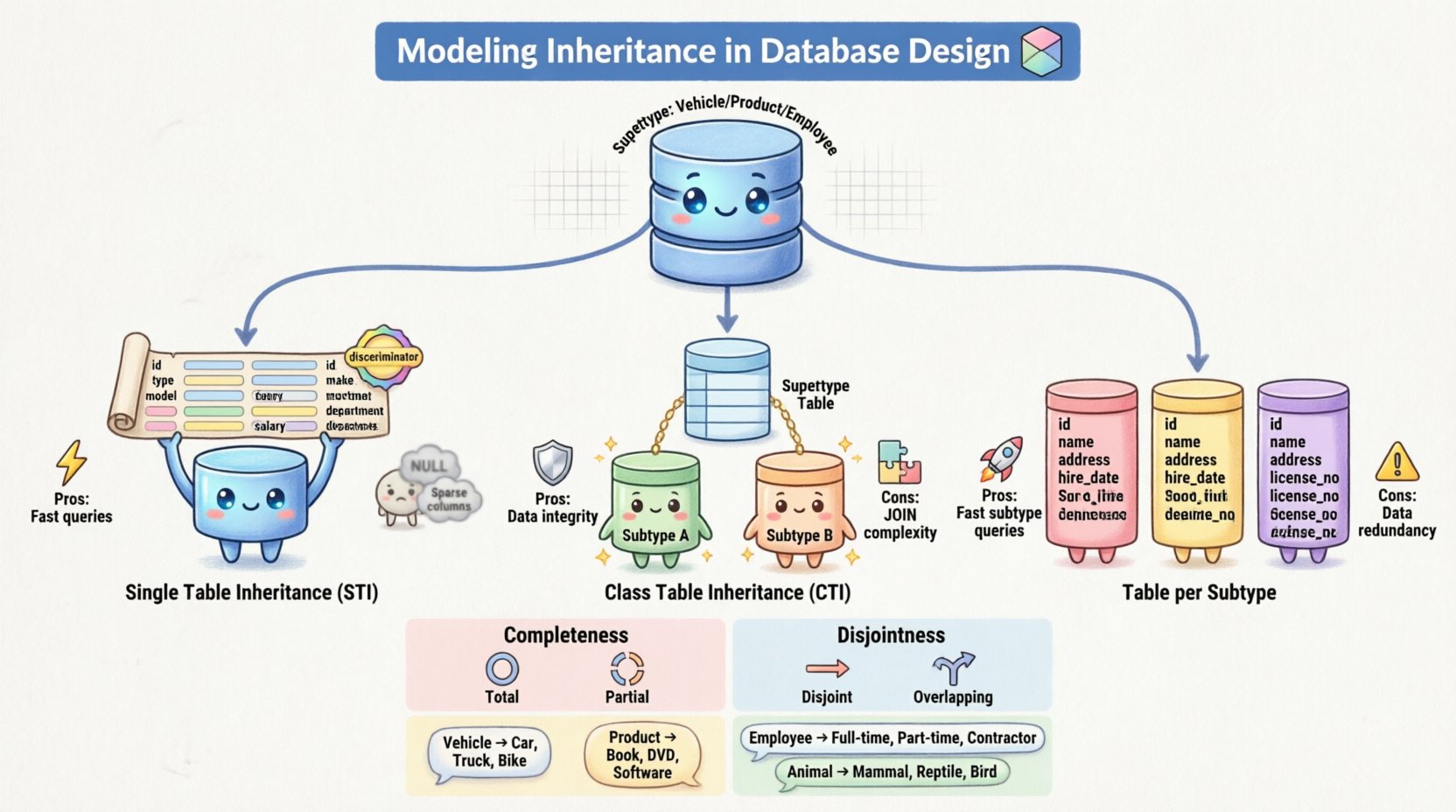
🔑 核心概念:超類型與子類型
在深入實現之前,我們必須明確定義術語。資料庫建模中的繼承不僅僅是關於程式碼;它涉及資料的結構化表示。
- 超類型: 這是父實體。它包含所有相關實體共有的屬性。它代表一般類別。例如,員工可能是一個超類型。
- 子類型: 這些是子實體。它們繼承自超類型的屬性,但也可能擁有自己獨特的屬性。範例包括經理或開發人員.
- 實體類別:超類型有時被稱為實體類別,將子類型歸為一組。
- 鑑別器: 超類型中的一個特定屬性,用於識別某個實例屬於哪個子類型。這在物理實現中經常使用。
超類型與子類型之間的關係是嚴格的。子類型的每個實例也必須是超類型的實例。然而,並非超類型的每個實例都必須是特定子類型的實例。這種區別對於資料建模的準確性至關重要。✅
📊 實現策略
將邏輯ERD模型轉換為物理資料庫結構,需要特定的映射策略。在關係系統中表示繼承有三種主要方法。每種方法在儲存空間、檢索速度和資料完整性之間都有其權衡。🛠️
1. 單一表格繼承(STI)
在此方法中,超類別和所有子類別的所有屬性都合併到單一表格中。該表格包含整個層次結構中定義的每個屬性的欄位。為了區分屬於不同子類別的資料列,會新增一個鑑別欄位。
- 優點: 讀取資料時極其高效。一個簡單的
SELECT就能取得所有資訊,無需複雜的連接操作。 - 缺點: 該表格可能變得非常寬闊,包含許多
NULL對於不適用於特定子類別的屬性,會出現許多 NULL 值。如果子類別的特定約束條件發生變更,更新也可能變得困難。
2. 類別表格繼承(CTI)
在此方法中,超類別和每個子類別都被映射到各自獨立的表格中。超類別表格包含共用屬性和主鍵。每個子類別表格包含獨特的屬性以及一個外鍵,用以連結回超類別的主鍵。
- 優點: 高度規範化。對於不適用的屬性,不會出現
NULL值。嚴格強制執行參考完整性。 - 缺點: 取得資料需要多次
JOIN操作,這可能對大型資料集的效能造成影響。同時也使INSERT操作變得複雜,因為資料必須寫入多個表格。
3. 每個子類別一個表格(具體表格繼承)
此策略為每個子類別(包括超類別)建立一個表格。然而,每個子類別表格都包含超類別屬性的複本。並沒有直接連結回中央的超類別表格。
- 優點: 查詢特定子類別時非常快速,因為所有資料都位於同一位置。它避免了 STI 的
NULL問題。 - 缺點: 資料重複。如果超類別中的共用屬性發生變更,則必須在每個子類別表格中更新。這增加了資料不一致的風險。
⚖️ 繼承上的約束
並非所有的繼承關係都相同。我們必須定義約束條件,以規範實例與其類型之間的關係。這些約束確保資料保持邏輯性和一致性。📝
完整性約束
此約束決定了每個超類型實例是否必須屬於某個子類型。
- 完整: 超類型的每個實例都必須屬於至少一個子類型。不存在「通用」的實例。例如,每個動物必須是哺乳動物或鳥類.
- 部分: 超類型的實例不一定屬於任何子類型。它可以作為一個通用實體存在。當層次結構用於分類而非嚴格分類時,這種情況很常見。
互斥性約束
此約束決定一個實例是否可以同時屬於多個子類型。
- 互斥: 實例只能屬於一個子類型。它不能在同一模型中同時是經理和開發人員兩者。
- 重疊: 實例可以屬於多個子類型。這允許複雜的角色,例如一名員工可以同時擔任多個職位或分類。
結合這些約束會產生四種不同的建模情境。在建立資料結構之前,理解哪種情境符合您的商業邏輯至關重要。🧠
| 約束類型 | 定義 | 範例情境 |
|---|---|---|
| 互斥 + 完整 | 僅允許一個子類型,無通用實例 | 訂單狀態:待處理、已發貨、已送達 |
| 互斥 + 部分 | 僅允許一個子類型,子類型可選 | 客戶:VIP 或 普通客戶(部分客戶兩者皆非) |
| 重疊 + 完整 | 允許多個子類型,但必須屬於其中一個 | 使用者角色:管理員與編輯者(至少需具備其中之一) |
| 重疊 + 部分 | 允許多個子類型,可選 | 產品:可售、促銷(可同時具備,或皆無) |
🔍 查詢與資料檢索
映射策略的選擇會顯著影響您撰寫查詢的方式。在規範化環境中,您通常需要遍歷層次結構,才能完整掌握實體的資訊。🔍
- 檢索子類型資料: 如果您需要存取特定於子類型的屬性,則必須連接子類型資料表。這在類別表繼承中是標準做法。
- 檢索超類型資料: 如果您需要共用屬性,可直接查詢超類型資料表。
- 多型查詢: 當查詢所有實例而不考慮子類型時,單一資料表方法最快。然而,若使用多個資料表,則必須使用
UNION運算或複雜的連接。
請考慮效能影響。一個需要連接五個資料表來取得單筆記錄的查詢,可能比在非規範化單一資料表上的查詢更慢。然而,非規範化資料表可能違反規範化原則,導致更新異常。平衡這些因素是資料庫結構設計的關鍵。⚖️
🛠️ 維護與演進
資料結構並非靜態不變。業務需求會變更,資料庫結構也必須隨之調整。繼承模型提供了彈性,但在維護過程中也引入了複雜性。🔄
新增子類型
新增子類型通常相當直接。您可建立新的資料表(在CTI中)或在鑑別欄位中新增一個值(在STI中)。然而,您必須確保現有的查詢與應用程式邏輯能支援新類型。若未更新程式碼,可能導致執行時期錯誤。
修改超類型屬性
若您向超類型新增屬性,在使用CTI或每子類型一表時,必須反映在每個子類型資料表中。在STI中,您只需在單一資料表中新增一次。這使得STI在處理常見變更時較易維護,但在處理特定變更時則較難維護。
資料遷移
重構繼承模型是一項重大任務。從單一資料表轉換為正常化結構,需要將資料跨多個資料表進行遷移。此過程必須謹慎管理,以避免資料遺失或損壞。 🚧
📈 正規化與繼承
繼承模型與資料庫正規化密切相關。正規化的目標是減少冗餘並提升資料完整性。若處理不當,繼承有時會與這些目標產生衝突。
- 第一正規化形式(1NF): 繼承模型通常符合 1NF,因為屬性是原子的。
- 第二正規化形式(2NF): 在 STI 中,若鑑別欄位未包含在主鍵中,資料表可能包含與主鍵未完全依賴的屬性。這需要仔細設計鍵結構。
- 第三正規化形式(3NF): 在 CTI 中,將屬性分離至子類別資料表,通常有助於達成 3NF,因為可消除傳遞依賴。
設計超類別時,請確保共用屬性確實是共用的。若某屬性僅被一個子類別使用,則應考慮不將其置於超類別中。這可避免超類別變成難以查詢的「萬能表」。 👁️
🎯 資料結構設計的最佳實務
為確保您的繼承模型保持可維護且具效能,請遵循以下指引。
- 限制層級深度: 避免過深的層級結構。通常建議繼承層級不超過三層。超過此範圍後,查詢與維護的複雜度將超過其帶來的好處。
- 使用明確命名: 名稱應反映層級結構。車輛, 汽車, 卡車 是清晰的。實體1, 實體2 則不然。
- 規劃成長空間: 預期未來的子類別。若預期會有許多新子類別,單一資料表可能變得難以管理;若預期子類別數量較少,CTI 可能更適合。
- 記錄約束條件: 清楚記錄互斥性與完整性約束。未來的開發人員需要知道一個實例是否可同時屬於多個子類別。
- 索引策略: 如果使用 CTI,請在子類型表的外鍵欄位上建立索引,以加快連接速度。如果使用 STI,請為鑑別欄位建立索引以利過濾。
🧪 實際應用場景
讓我們看看這如何應用於實際的資料模型挑戰。
場景 1:人力資源
在人力資源系統中,您有人員作為超類型。子類型包括員工, 合約人員,以及實習生。每個子類型都有獨特的資料:員工有薪資編號,合約人員有計費率。一個人員資料表儲存姓名和地址。這非常適合類別表繼承模型。
場景 2:庫存管理
考慮一個產品目錄。產品是超類型。子類型包括電子產品, 家具,以及服裝. 電子產品 有 保固期限. 服裝 有 尺寸 和 顏色。如果您查詢所有具有保固的產品,則必須加入電子產品表格。這突顯了查詢效能的權衡。🔍
情境 3:金融交易
在銀行系統中,帳戶 是超類型。子類型包括 儲蓄, 支票,以及 貸款。一個 儲蓄帳戶具有利率。一個 貸款帳戶有到期日。此情境通常受益於單一表格方法,以簡化所有帳戶類型之間的餘額計算。
🚀 性能考量
性能通常是選擇映射策略時的決定性因素。大型資料集會放大不同方法之間的差異。
- 寫入效能: STI 在插入時最快,因為它僅需單一
INSERT陳述式。CTI 則需要多個插入語句,這會增加交易開銷。 - 讀取效能: 如果您經常查詢特定的子類型,CTI 比 STI 更快,因為您只需讀取相關欄位。如果您查詢所有實例,STI 則更快。
- 儲存空間: STI 因為
NULL填補。CTI 因重複的主鍵和外鍵而使用更多儲存空間,但因缺乏NULL填補而使用較少。
分析您的應用程式至關重要。理論上的效能並不一定符合實際使用模式。唯有使用實際的資料量進行測試,才能確認您的選擇。📊
🛡️ 資料完整性與驗證
在繼承模型中維持資料完整性需要嚴格的驗證規則。您必須確保輸入子類型表格的資料符合超類型的約束條件。
- 外鍵約束: 確保子類型的資料行始終連結到有效的超類型資料行。這可防止孤立資料的產生。
- 檢查約束: 使用檢查約束來強制執行業務規則。例如,確保 利率 在 儲蓄 子類型中永遠不會為負數。
- 觸發器: 在某些複雜情境中,資料庫觸發器可能需要在更新時維持跨表格的一致性。
自動化測試應涵蓋繼承情境。確認建立新的子類型實例時,能正確更新超類型。確認若為預期行為,刪除超類型實例時,會正確地級聯刪除子類型。🧪
📝 最後的考量
建模繼承是在彈性與複雜性之間取得平衡的過程。並沒有單一的「正確」做法。最佳選擇取決於您特定的資料存取模式、業務規則與效能需求。
- 從對領域的清晰理解開始。在擔心表格之前,先繪製實體。
- 選擇與您最常見查詢相符的對應策略。
- 記錄您的決策。未來的維護將依賴於這些文件。
- 定期檢視資料結構。隨著業務的演進,模型可能需要調整。
透過精心設計超類型和子類型,您可以建立一個穩健、可擴展且易於理解的資料庫。此基礎支援依賴它的應用程式,確保長期的穩定性和效率。 🏗️