











Thiết kế cơ sở dữ liệu không chỉ đơn thuần là lưu trữ dữ liệu; đó là việc cấu trúc thông tin theo cách đảm bảo tính toàn vẹn, giảm thiểu trùng lặp và tối ưu hiệu suất. Khi nói đến các cấu trúc cơ sở dữ liệu hiệu quả, hai trụ cột nổi bật lên: Sơ đồ Quan hệ Thực thể (ERD) và Chuẩn hóa. Những khái niệm này không phải là các kỹ thuật tách biệt mà là những công cụ bổ trợ, hoạt động cùng nhau để tạo nên một nền tảng dữ liệu vững chắc.
Hướng dẫn này khám phá cách kết hợp sự rõ ràng trực quan của ERD với tính chặt chẽ về cấu trúc của chuẩn hóa. Chúng ta sẽ đi qua quy trình chuyển đổi một mô hình khái niệm thành một lược đồ thực tế, có thể vượt qua thử thách của thời gian.
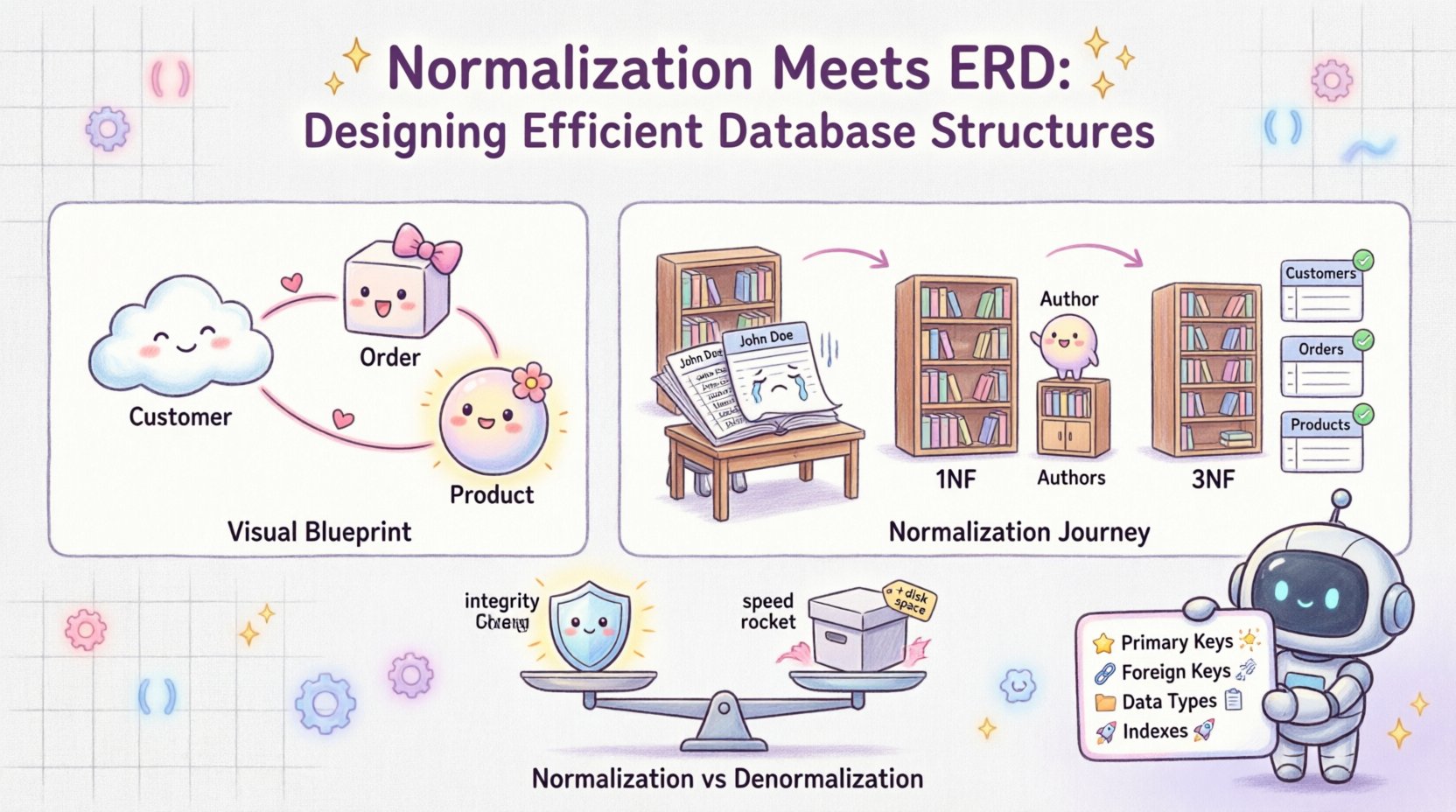
📐 Hiểu Rõ Nền Tảng: ERD và Chuẩn Hóa
Trước khi bước vào quá trình thiết kế, điều quan trọng là phải hiểu rõ vai trò riêng biệt của hai phương pháp này.
📊 Sơ đồ Thực thể – Quan hệ là gì?
Sơ đồ Thực thể – Quan hệ đóng vai trò là bản vẽ trực quan cho cơ sở dữ liệu. Nó xác định các thực thể (bảng), thuộc tính (cột) và mối quan hệ (liên kết) giữa chúng. Hãy hình dung nó như bản vẽ kiến trúc cho một tòa nhà. Nó trả lời những câu hỏi như:
- Những đối tượng cốt lõi trong hệ thống của chúng ta là gì? (ví dụ như: Khách hàng, Đơn hàng)
- Các đối tượng này tương tác với nhau như thế nào? (ví dụ như: Một Khách hàng đặt nhiều Đơn hàng)
- Chúng ta cần lưu trữ dữ liệu gì cho mỗi đối tượng? (ví dụ như: Khách hàng cần một Tên và Email)
Không có ERD, việc thiết kế cơ sở dữ liệu trở thành một trò chơi đoán mò. Nó cung cấp cái nhìn tổng quan cao cấp mà các bên liên quan có thể hiểu được, đảm bảo mọi người đều đồng thuận về yêu cầu dữ liệu trước khi viết bất kỳ dòng mã nào.
🧼 Chuẩn hóa là gì?
Chuẩn hóa là quá trình tổ chức dữ liệu trong cơ sở dữ liệu nhằm giảm thiểu sự trùng lặp và cải thiện tính toàn vẹn dữ liệu. Nó bao gồm việc chia các bảng lớn thành các cấu trúc logic nhỏ hơn và thiết lập các mối quan hệ giữa chúng. Mục tiêu là đảm bảo rằng mỗi phần dữ liệu được lưu trữ ở đúng một vị trí.
Tại sao điều này lại quan trọng?
- Toàn vẹn dữ liệu: Nếu địa chỉ khách hàng thay đổi, bạn chỉ cần cập nhật ở một nơi, chứ không phải mười nơi.
- Hiệu quả lưu trữ: Ít dữ liệu trùng lặp hơn nghĩa là sử dụng ít không gian đĩa hơn.
- Bảo trì: Dễ dàng hơn để bảo trì và cập nhật lược đồ theo thời gian.
⚙️ Giao điểm: Kết hợp ERD với Chuẩn hóa
Thiết kế cơ sở dữ liệu thường bắt đầu bằng ERD, nhưng một ERD thô thường hiếm khi sẵn sàng cho sản xuất. Nó thường chứa các sự trùng lặp mà chuẩn hóa giải quyết. Quy trình làm việc bao gồm việc tạo ERD khái niệm, phân tích nó để tìm các bất thường, và áp dụng các quy tắc chuẩn hóa để tinh chỉnh lược đồ.
Dưới đây là quy trình làm việc thông thường:
- Thiết kế khái niệm: Vẽ ERD ban đầu dựa trên các yêu cầu.
- Thiết kế logic: Tinh chỉnh ERD thành các bảng và cột.
- Chuẩn hóa: Áp dụng các dạng chuẩn hóa (1NF, 2NF, 3NF) để loại bỏ các bất thường.
- Thiết kế vật lý: Tối ưu hóa cho bộ động cơ cơ sở dữ liệu cụ thể và nhu cầu hiệu suất.
🔍 Bước từng bước: Từ ERD đến lược đồ đã được chuẩn hóa
Hãy cùng đi qua một tình huống thực tế để xem cách thức này hoạt động trong thực tế. Hãy tưởng tượng chúng ta đang xây dựng một hệ thống để quản lý một thư viện.
1. Trạng thái chưa được chuẩn hóa
Ban đầu, bạn có thể thiết kế một bảng duy nhất để lưu trữ tất cả thông tin về sách và tác giả. Điều này được gọi là bảng chưa được chuẩn hóa.
| BookID | Tiêu đề | Tên tác giả | Số điện thoại tác giả | Thể loại |
|---|---|---|---|---|
| 101 | Tác phẩm vĩ đại | John Doe | 555-0101 | Truyện giả tưởng |
| 102 | Cuốn sách bí ẩn | John Doe | 555-0101 | Bí ẩn |
| 103 | Một cuốn sách khác | Jane Smith | 555-0102 | Truyện giả tưởng |
Nhận thấy các vấn đề ở đây chứ?John Doesố điện thoại bị lặp lại. Nếu anh ấy đổi số, bạn phải cập nhật nhiều hàng. Đây là một Sự bất thường khi cập nhật.
2. Dạng chuẩn thứ nhất (1NF)
Quy tắc đầu tiên của chuẩn hóa là đảm bảo tính nguyên tử. Mỗi cột chỉ được chứa một giá trị duy nhất, và không được có nhóm lặp lại.
- Quy tắc:Loại bỏ các nhóm lặp lại và đảm bảo các giá trị nguyên tử.
- Áp dụng: Trong ví dụ thư viện của chúng ta, bảng ban đầu có thể đã nguyên tử, nhưng chúng ta phải đảm bảo rằng bảng có khóa chính. Hãy giả sử BookID là duy nhất.
- Kết quả: Bây giờ chúng ta có một bảng mà mỗi ô chỉ chứa một phần dữ liệu.
3. Dạng chuẩn thứ hai (2NF)
Khi một bảng đã ở dạng 1NF, chúng ta kiểm tra các phụ thuộc riêng phần. Một bảng ở dạng 2NF nếu nó ở dạng 1NF và mọi thuộc tính không khóa đều phụ thuộc hoàn toàn vào khóa chính.
- Bối cảnh: Nếu chúng ta có một khóa tổng hợp (ví dụ như BookID + AuthorID), chúng ta sẽ kiểm tra xem AuthorPhone có phụ thuộc vào toàn bộ khóa hay chỉ phần liên quan đến tác giả hay không.
- Hành động: Trong ví dụ của chúng ta, AuthorPhone phụ thuộc vào AuthorName, không phải là BookID. Điều này cho thấy chúng ta nên tách dữ liệu tác giả khỏi dữ liệu sách.
4. Dạng chuẩn thứ ba (3NF)
Đây là nơi phép màu thực sự xảy ra. 3NF loại bỏ các phụ thuộc bắc cầu. Các thuộc tính không khóa không nên phụ thuộc vào các thuộc tính không khóa khác.
- Quy tắc: Không thuộc tính nào được phép phụ thuộc vào một thuộc tính không khóa khác.
- Áp dụng: AuthorPhone phụ thuộc vào AuthorName. Vì AuthorName không phải là khóa chính của bảng sách, nên chúng ta di chuyển thông tin tác giả sang một bảng riêng biệt Authors bảng.
- Kết quả: Bây giờ, cập nhật số điện thoại của một tác giả chỉ yêu cầu thay đổi một bản ghi trong bảng Tác giả bảng, chứ không phải nhiều bản ghi trong bảng Sách bảng.
📋 Chuẩn hóa so với phi chuẩn hóa: Tìm kiếm sự cân bằng
Mặc dù chuẩn hóa rất quan trọng đối với tính toàn vẹn, nhưng nó không phải lúc nào cũng là giải pháp cho hiệu suất. Đôi khi, việc đọc dữ liệu xảy ra thường xuyên hơn việc ghi dữ liệu. Trong những trường hợp này, phi chuẩn hóa có thể mang lại lợi ích.
📉 Khi nào nên phi chuẩn hóa
Việc phi chuẩn hóa bao gồm việc thêm dữ liệu trùng lặp vào cơ sở dữ liệu đã được chuẩn hóa nhằm cải thiện hiệu suất đọc. Đây là một sự đánh đổi giữa dung lượng lưu trữ và tốc độ.
- Lưu lượng đọc cao: Nếu ứng dụng của bạn truy vấn dữ liệu hàng ngàn lần mỗi giây, việc kết hợp các bảng có thể làm chậm hiệu suất.
- Bảng điều khiển báo cáo: Dữ liệu tổng hợp có thể được tính toán trước và lưu trữ để tránh các truy vấn phức tạp.
- Chiến lược bộ nhớ đệm: Đôi khi, các view phi chuẩn hóa hoạt động như một bộ nhớ đệm cho dữ liệu thường xuyên được truy cập.
Tuy nhiên, điều này đi kèm với rủi ro. Bạn phải quản lý việc đồng bộ hóa dữ liệu trùng lặp một cách thủ công hoặc thông qua các trigger. Nếu không được xử lý cẩn thận, tính toàn vẹn dữ liệu sẽ bị ảnh hưởng.
| Yếu tố | Chuẩn hóa | Phi chuẩn hóa |
|---|---|---|
| Tính toàn vẹn dữ liệu | Cao (nguồn duy nhất của sự thật) | Thấp (yêu cầu logic đồng bộ) |
| Tốc độ ghi | Chậm hơn (nhiều bảng) | Nhanh hơn (ít phép nối hơn) |
| Tốc độ đọc | Chậm hơn (nhiều phép nối) | Nhanh hơn (ít phép nối hơn) |
| Bộ nhớ | Hiệu quả | Thừa thãi |
🛠️ Những sai lầm phổ biến trong thiết kế cơ sở dữ liệu
Ngay cả những nhà thiết kế có kinh nghiệm cũng mắc sai lầm. Tránh những cái bẫy phổ biến này để đảm bảo cấu trúc cơ sở dữ liệu của bạn luôn khỏe mạnh.
❌ Bỏ qua kiểu dữ liệu
Việc chọn kiểu dữ liệu sai có thể dẫn đến tình trạng bloat bộ nhớ và vấn đề hiệu suất. Sử dụng trường văn bản cho ngày tháng hoặc số nguyên cho số điện thoại sẽ lãng phí không gian và làm phức tạp quá trình xác thực.
❌ Quá mức chuẩn hóa
Cố gắng đạt 5NF hoặc BCNF (Dạng chuẩn hóa Boyce-Codd) trong mọi tình huống có thể khiến các truy vấn trở nên cực kỳ phức tạp. Đôi khi, 3NF là đủ. Đừng chuẩn hóa chỉ vì muốn chuẩn hóa.
❌ Khóa chính yếu
Sử dụng khóa tự nhiên (như địa chỉ email) làm khóa chính có thể rủi ro nếu dữ liệu thay đổi. Khóa giả (số nguyên tự tăng hoặc UUID) thường an toàn hơn cho các mối quan hệ nội bộ.
❌ Thiếu chỉ mục
Một lược đồ đã được chuẩn hóa tốt vẫn có thể hoạt động kém nếu không có chỉ mục phù hợp. Xác định các cột thường xuyên được sử dụng trong WHERE, JOIN, hoặc ORDER BYcác câu lệnh và chỉ mục hóa chúng.
🔄 Quy trình lặp lại trong thiết kế
Thiết kế cơ sở dữ liệu hiếm khi là tuyến tính. Đó là một quá trình lặp lại. Bạn có thể bắt đầu bằng sơ đồ ERD, chuẩn hóa nó, nhận ra hiệu suất là vấn đề, giảm mức chuẩn hóa một chút, rồi quay lại xem xét ERD để đảm bảo các mối quan hệ vẫn chính xác.
🔄 Các bước tinh chỉnh
- Xem xét yêu cầu:Các tính năng mới có yêu cầu bảng mới không?
- Phân tích truy vấn:Xem xét các truy vấn chậm nhất và xác định các điểm nghẽn.
- Kiểm tra ràng buộc:Đảm bảo các khóa ngoại được định nghĩa đúng để ngăn chặn các bản ghi bị tách rời.
- Tài liệu:Giữ cho sơ đồ ERD của bạn luôn cập nhật. Một sơ đồ lỗi thời còn tệ hơn cả không có sơ đồ.
📈 Các Xét Nghiệm Về Hiệu Năng
Chuẩn hóa chủ yếu giải quyết vấn đề toàn vẹn dữ liệu. Hiệu năng là một vấn đề riêng biệt thường đòi hỏi điều chỉnh. Tuy nhiên, hai yếu tố này có liên hệ với nhau.
🚀 Độ Phức Tạp Của JOIN
Các cơ sở dữ liệu được chuẩn hóa cao yêu cầu thêm JOINthao tác để truy xuất dữ liệu liên quan. Các bộ động cơ cơ sở dữ liệu hiện đại rất giỏi trong việc tối ưu hóa các thao tác JOIN, nhưng việc sử dụng quá nhiều JOIN vẫn có thể ảnh hưởng đến độ trễ.
📦 Bộ Động Cơ Lưu Trữ
Các bộ động cơ lưu trữ khác nhau xử lý dữ liệu theo cách khác nhau. Một số ưu tiên lưu trữ theo hàng, trong khi những bộ khác lại ưu tiên lưu trữ theo cột. Chiến lược chuẩn hóa của bạn có thể cần điều chỉnh tùy theo bộ động cơ nền tảng.
🔒 Ràng Buộc và Triggers
Thực thi các quy tắc chuẩn hóa thông qua ràng buộc (như Khóa Ngoại) đảm bảo chất lượng dữ liệu. Tuy nhiên, việc sử dụng quá nhiều trigger để kiểm tra tính hợp lệ có thể làm chậm các thao tác ghi. Hãy sử dụng chúng một cách khôn ngoan.
🧩 Ví Dụ Thực Tế: Hệ Thống Đơn Hàng Thương Mại Điện Tử
Hãy cùng xem xét một tình huống phức tạp hơn một chút: một cửa hàng trực tuyến.
Khái Niệm ERD Ban Đầu
Ban đầu, bạn có thể có một Đơn Hàngbảng chứa tên sản phẩm, giá cả và thông tin khách hàng. Đây là cách tiếp cận truyền thống “tệp phẳng”.
Cách Tiếp Cận Chuẩn Hóa
Để khắc phục điều này, chúng ta chia nhỏ dữ liệu:
- Bảng Khách Hàng:Lưu trữ thông tin khách hàng (Tên, Địa chỉ, Email).
- Bảng Sản Phẩm:Lưu trữ thông tin sản phẩm (Tên, Giá, Số lượng tồn kho).
- Bảng Đơn Hàng:Lưu trữ giao dịch (CustomerID, NgàyĐặtHàng, TổngCộng).
- Bảng Chi Tiết Đơn Hàng:Liên kết Đơn Hàng và Sản Phẩm (IDĐơnHàng, IDSảnPhẩm, SốLượng, GiáThờiĐiểm).
Cấu trúc này cho phép chúng ta:
- Cập nhật giá sản phẩm tại một nơi duy nhất (bảng Sản Phẩmbảng).
- Theo dõi giá lịch sử trong bảng OrderItems bảng (lưu trạng thái điểm).
- Đảm bảo khách hàng không thể bị xóa nếu họ có đơn hàng đang mở (thông qua khóa ngoại).
🎯 Danh sách kiểm tra các thực hành tốt nhất
Trước khi triển khai lược đồ của bạn, hãy thực hiện danh sách kiểm tra này để đảm bảo chất lượng.
- ✅ Khóa chính: Mỗi bảng đều có một định danh duy nhất.
- ✅ Khóa ngoại: Các mối quan hệ được xác định rõ ràng.
- ✅ Khả năng chấp nhận giá trị null: Các cột được đánh dấu là
KHÔNG RỖNGkhi phù hợp. - ✅ Kiểu dữ liệu: Sử dụng kiểu dữ liệu cụ thể nhất có thể.
- ✅ Quy ước đặt tên: Sử dụng tên nhất quán, rõ ràng cho bảng và cột.
- ✅ Tài liệu: Sơ đồ ERD khớp với lược đồ vật lý.
- ✅ Chiến lược sao lưu: Xem xét cách lược đồ ảnh hưởng đến thời gian sao lưu và khôi phục.
🔮 Tương lai của thiết kế cơ sở dữ liệu
Khi công nghệ phát triển, các nguyên tắc cốt lõi về chuẩn hóa và sơ đồ ERD vẫn giữ được tính phù hợp. Mặc dù cơ sở dữ liệu NoSQL mang lại tính linh hoạt, nhưng mô hình quan hệ vẫn chiếm ưu thế trong các hệ thống giao dịch. Hiểu rõ các nguyên lý cơ bản giúp bạn thích nghi với các công nghệ mới mà không đánh mất tính kỷ luật trong mô hình hóa dữ liệu.
Các cơ sở dữ liệu đám mây giới thiệu những khía cạnh mới, chẳng hạn như chia nhỏ dữ liệu và phân vùng. Tuy nhiên, cấu trúc logic bạn thiết kế bằng sơ đồ ERD và chuẩn hóa vẫn là bản vẽ thiết kế cho cách dữ liệu được phân phối và truy cập.
📝 Tóm tắt những điểm chính cần ghi nhớ
Thiết kế các cấu trúc cơ sở dữ liệu hiệu quả là sự cân bằng giữa cấu trúc và tính linh hoạt. Dưới đây là những điều bạn cần ghi nhớ:
- Sơ đồ ERD là các hướng dẫn trực quan: Chúng giúp bạn xác định các mối quan hệ trước khi tiến hành xây dựng.
- Chuẩn hóa là về cấu trúc: Nó sắp xếp dữ liệu để giảm thiểu sự trùng lặp.
- 3NF là mục tiêu:Hướng đến dạng chuẩn hóa thứ ba cho phần lớn các hệ thống giao dịch.
- Chuẩn hóa ngược một cách khôn ngoan:Chỉ thêm sự trùng lặp khi hiệu suất yêu cầu.
- Lặp lại:Thiết kế chưa bao giờ hoàn tất; nó phát triển cùng với ứng dụng.
Bằng cách kết hợp sự rõ ràng trực quan của sơ đồ quan hệ thực thể với các quy tắc nghiêm ngặt của chuẩn hóa, bạn tạo nên một nền tảng dữ liệu vừa đáng tin cậy vừa mở rộng được. Cách tiếp cận này đảm bảo cơ sở dữ liệu của bạn có thể phát triển cùng ứng dụng, xử lý độ phức tạp mà không làm mất tính toàn vẹn.
Bắt đầu bằng một sơ đồ ERD sạch sẽ. Áp dụng các quy tắc chuẩn hóa từng bước. Kiểm thử truy vấn của bạn. Tinh chỉnh lược đồ của bạn. Và luôn ưu tiên tính toàn vẹn dữ liệu hơn tốc độ ở giai đoạn đầu.