











构建数据库系统类似于建造摩天大楼的地基。如果蓝图有缺陷,结构最终会在压力下开裂。实体关系图(ERD)就是这份蓝图,它定义了数据在应用程序中如何连接、流动和持久化。随着用户数量的增长和数据量的爆炸式增加,静态设计往往会成为瓶颈。为了确保系统的长期可用性,你必须从一开始就采用可扩展的ERD设计原则。本指南探讨了构建持久系统所需的技术策略。
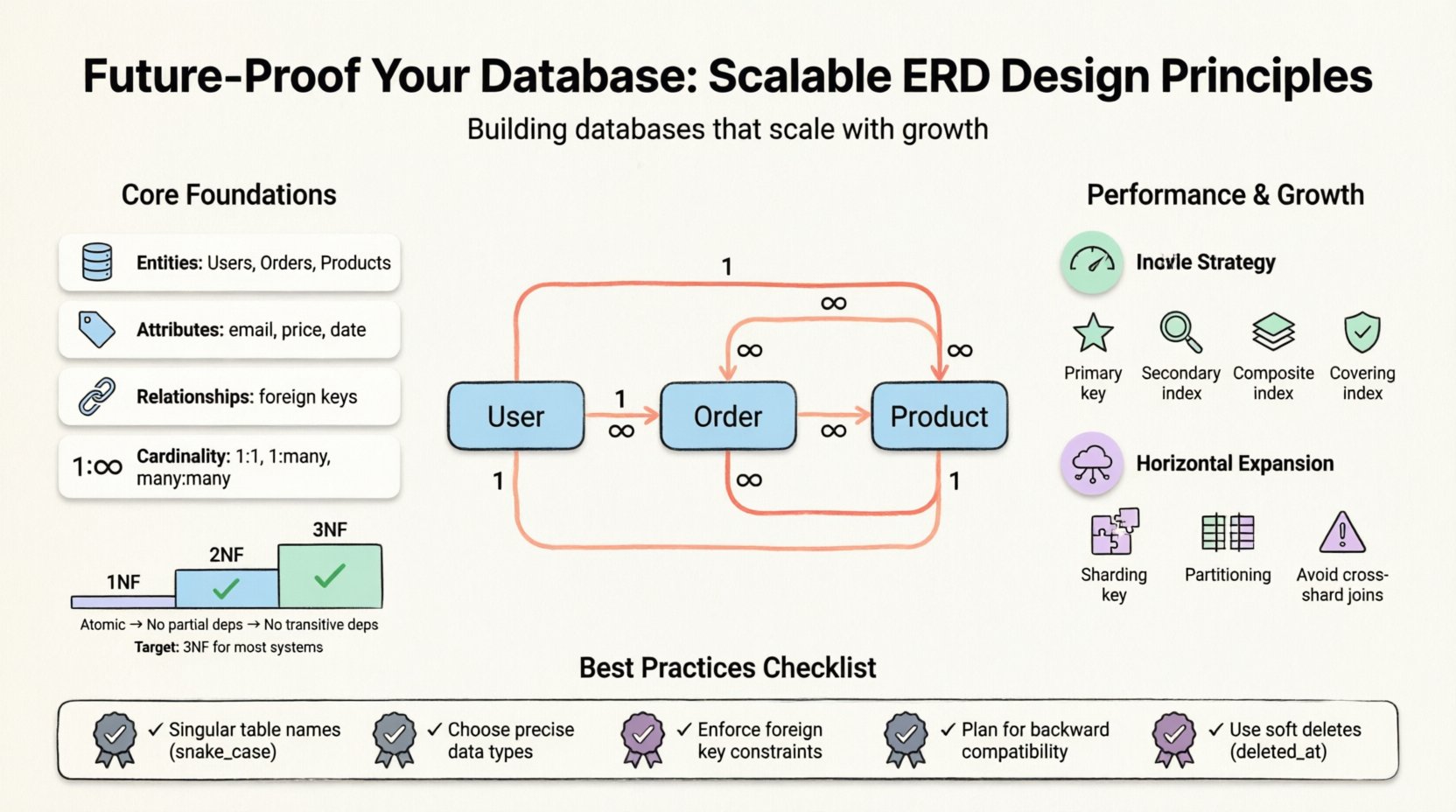
理解数据建模的核心 🧱
在深入具体策略之前,必须理解ERD所代表的含义。它可视化了数据库的逻辑结构,映射实体(表)、属性(列)和关系(键)。一个精心设计的模型在数据完整性和性能之间取得平衡。然而,“最佳实践”会因工作负载的不同而有所差异。读取密集型应用所需的优化与写入密集型事务系统完全不同。
关键组成部分包括:
- 实体: 主要对象,例如用户、订单或产品。
- 属性: 定义实体的属性,例如电子邮件地址或价格。
- 关系: 实体之间的交互方式,通常由外键定义。
- 基数: 实体之间的数值关系(一对一、一对多、多对多)。
规范化:冗余与速度之间的平衡 ⚖️
规范化是通过组织数据来减少冗余并提高完整性的一种过程。尽管常被视为严格规则,但它实际上是一种权衡。高规范化可以最小化异常,但可能通过连接操作增加查询复杂度。低规范化(反规范化)能加快读取速度,但可能导致数据不一致。
规范化的级别
理解标准形式有助于你决定在何处停止。每种形式都针对特定的数据异常。
- 第一范式(1NF): 确保原子性。每一列必须包含不可再分的值。单个单元格内不得存在重复组或数组。
- 第二范式(2NF): 建立在1NF基础上。所有非主键属性必须依赖于整个主键,而不仅仅是其中一部分。这消除了部分依赖。
- 第三范式(3NF): 建立在2NF基础上。非主键属性不得依赖于其他非主键属性。这消除了传递依赖。
- 博伊斯-科德范式(BCNF): 3NF的更严格版本。用于处理决定因素不是候选键的情况。
对于大多数可扩展系统,达到3NF是标准目标。进一步规范化通常收益递减,同时增加维护开销。然而,对于以分析为主的系统,适度地返回反规范化是常见的做法。
规范化权衡表
| 规范化级别 | 主要优势 | 主要缺点 |
|---|---|---|
| 第一范式 | 原子数据存储 | 无 |
| 第二范式 | 消除部分依赖 | 需要更多的连接操作 |
| 第三范式 | 消除传递依赖 | 连接复杂度增加 |
| 反规范化 | 更快的读取查询 | 数据冗余和更新异常 |
面向增长与灵活性的模式设计 📈
仅针对当前设计是不够的。你必须预见未来模式的演变。当业务逻辑发生变化时,僵化的结构会崩溃。灵活的设计能够在不需全面系统迁移的情况下实现扩展。
1. 命名规范与标准
一致性对于可维护性至关重要。混乱的命名方案会导致混淆和错误。尽早建立标准,并在整个团队中严格执行。
- 使用单数名称:表应代表单一实体(例如,
用户,而不是用户们). - 使用一致的分隔符:为表名和列名使用 snake_case,以确保在不同操作系统和工具间的兼容性。
- 使用前缀以增强明确性:使用如
fk_作为外键,或使用idx_作为索引的前缀,以明确其用途。 - 避免保留字: 永远不要使用诸如
order,group,或select作为列名。
2. 数据类型和精度
选择正确的数据类型会影响存储空间和查询速度。过于通用的类型会浪费空间并减慢处理速度。
- 整数: 使用
TINYINT表示标志(0-1)或小计数。仅在预期数据规模极大时使用BIGINT。 - 字符串: 避免使用
TEXT表示短值。使用VARCHAR并指定长度以节省空间并支持索引。 - 日期: 使用
TIMESTAMP表示特定时刻,使用DATE表示日历日期。始终以UTC格式存储,以避免时区混淆。 - 小数: 对于财务数据,应使用定点小数而非浮点数,以避免舍入误差。
关系与基数管理 🔗
实体之间的关联方式决定了数据的完整性。关系管理不当会导致孤立记录和数据丢失。
1. 外键约束
外键强制参照完整性。它们确保一个表中的记录不能引用另一个表中不存在的记录。尽管一些开发者为了性能禁用这些约束,但现代数据库引擎能够高效处理它们。依赖应用层检查容易出错。
2. 处理多对多关系
多对多关系(例如学生和课程)无法直接在两个表中表示,需要一个连接表(关联实体)。
- 创建一个新表,包含两个相关表的主键。
- 添加一个由两个外键组成的复合主键。
- 使用此表存储与关系相关的额外属性,例如注册日期。
3. 可选与必选关系
明确界定关系是否必需。一个 NULL外键列中的 NULL 值表示可选关系。这一决定会影响应用层的验证逻辑。
读取性能的索引策略 🏎️
索引是加速数据检索的主要机制。然而,它们并非免费的。每个索引都会消耗磁盘空间,并减慢写操作(插入、更新、删除)。
1. 主索引
每个表都需要一个主键。这通常是聚集索引,意味着物理数据按键的顺序存储。应选择稳定且从不更新的键。代理键(自增整数)通常比自然键(如电子邮件)在性能上更优。
2. 次要索引
使用次要索引来优化在非主键列上进行过滤或排序的查询。常见场景包括:
- 通过电子邮件地址进行搜索。
- 按状态或类别进行过滤。
- 按日期对结果进行排序。
3. 复合索引
在按多个列查询时,复合索引通常比单独的单列索引更高效。索引中列的顺序很重要,应将选择性最高的列放在前面。
4. 覆盖索引
覆盖索引包含满足查询所需的所有列。这使得数据库可以直接从索引中检索数据,而无需访问主表,显著减少 I/O 操作。
面向水平扩展的设计 🌐
垂直扩展(向单个服务器增加更多资源)有其局限性。最终,你必须将数据分布在多个节点上。ERD 设计必须考虑到这一现实。
1. 分片键
分片涉及将数据分布在多个数据库中。分片键的选择至关重要。它应在查询中频繁使用,以确保数据局部性。如果你按 用户ID,您可以在单个节点上轻松查询该用户的所有数据。
- 良好的分片键: 高基数,经常用于查询。
- 不良的分片键: 低基数(例如,
国家代码)或很少使用。
2. 避免跨分片连接
不同分片之间的连接开销大且复杂。设计您的模式以尽量减少此类需求。如果需要从可能位于不同分片的两个实体获取数据,考虑对数据进行反规范化。将必要的外键数据直接存储在表中,以避免连接操作。
3. 分区
分区将大表拆分为更小、更易管理的部分。可以通过范围(日期)、列表(类别)或哈希进行。这可以在不显著改变应用逻辑的情况下提升维护性和查询性能。
模式演进与迁移 🔄
需求会变化。新功能需要新增列。旧功能会被弃用。一个健壮的ERD能够在不破坏现有功能的前提下适应变化。
1. 向后兼容性
在添加新功能时,确保旧客户端仍能正常运行。首先将新列设为可空。逐步填充数据。不要立即删除列;将其标记为已弃用,并保留一段时间以供迁移使用。
2. 数据模型版本控制
记录模式版本。这样在迁移导致严重故障时可以回滚更改。使用幂等的迁移脚本,即可以多次运行而不会引发错误。
3. 处理数据迁移
迁移大量数据需要仔细规划。大锁可能阻塞生产流量。尽可能在低流量时段进行迁移,或使用蓝绿部署策略。
常见陷阱需避免 ⚠️
即使经验丰富的架构师也会犯错。了解常见错误有助于您避开它们。
- 过度设计: 为尚未达到的规模进行设计。如果刚开始,保持简单。复杂性会增加成本和风险。
- 忽略软删除: 永远不要立即永久删除敏感记录。使用一个
deleted_at时间戳代替。这可以保留审计日志并支持恢复。 - 命名冲突: 为表和列使用相同名称会造成歧义。坚持使用单数表名规则。
- 缺少约束条件:仅依赖应用逻辑来强制执行业务规则会导致数据损坏。应在数据库层面强制实施约束。
- 忽视安全:设计必须包含访问控制字段。确保在模式设计阶段就支持基于角色的访问控制。
长期可持续性的最终考量 🏁
构建可扩展的数据库是一个持续的过程。它需要监控、分析和调整。没有设计在发布时是完美的。目标是建立一个易于修改的基础。
定期审查您的查询。识别缓慢的操作并优化底层模式。使用分析工具了解您的数据是如何被访问的。这种反馈循环可确保随着数据的增长,您的架构依然保持高效。
请记住,技术是不断演进的。新的存储引擎和查询语言不断出现。灵活的模式比僵化的模式更能适应这些变化。专注于核心关系和数据完整性。即使工具发生变化,这些要素依然保持不变。
通过遵循这些原则,您将构建出具有韧性的系统。它们能够优雅地应对增长,并在负载下保持性能。这就是为您的数据库基础设施实现未来适应性的核心所在。