











设计一个健壮的数据库模式是软件工程中的基础步骤。该架构的蓝图就是实体-关系图(ERD)。ERD能够可视化数据的结构,定义不同信息片段之间的关联关系。虽然一个功能正确的图能确保数据完整性,但一个清晰、可维护的图才能确保系统在长时间内保持可理解性和可适应性。技术债务往往并非积累在代码本身,而是积累在那些过时或令人困惑的文档和设计文档中。本指南概述了创建能够经受时间考验的ERD的基本原则。
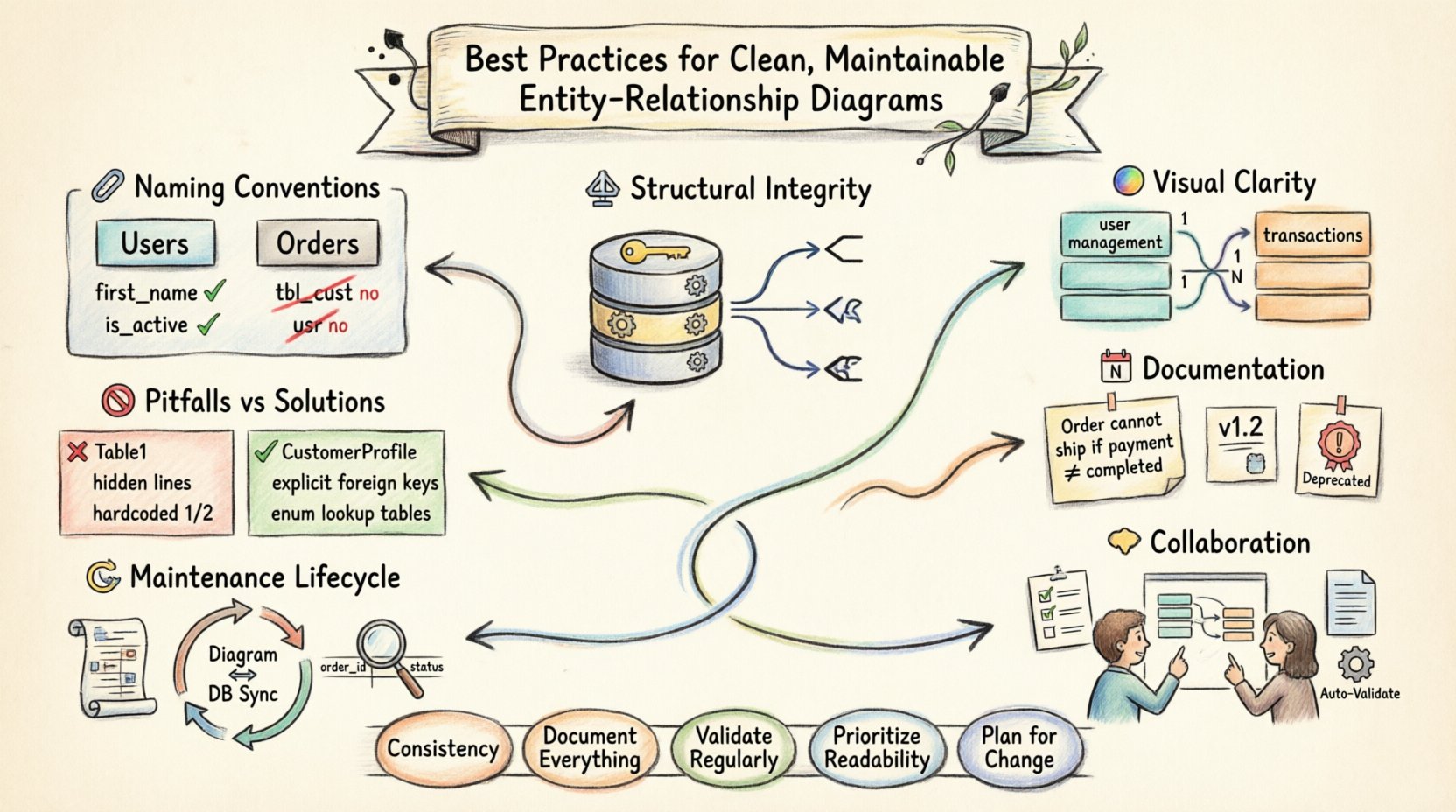
1. 命名规范与标准 🏷️
实体或属性的名称是任何审查模式的开发人员接触到的第一个要素。命名不一致会带来摩擦,减慢入职速度,并增加开发过程中的错误概率。标准化的命名策略不仅仅是美观问题,更是一种沟通协议。
实体命名规则
- 复数形式: 实体通常应使用复数形式命名(例如,
用户,订单),以表示一组记录。单数名称(例如,用户)可能暗示单个实例,而这在关系型表中很少见。 - 驼峰命名法或蛇形命名法: 选择一种风格并统一应用。驼峰命名法(例如,
CustomerOrder)常用于面向对象的上下文中,而蛇形命名法(例如,customer_order)在SQL环境中更受青睐。避免混合使用风格。 - 描述性: 名称必须准确描述其所包含的数据。避免使用如
tbl_cust或ord之类的缩写。如果必须使用缩写,应定义术语表。优先使用Customer而非Cust. - 避免使用保留字: 确保实体名称不与数据库关键字冲突(例如,
Group,Order,Key)。如果冲突不可避免,请将名称用引号括起来或使用前缀,尽管重命名是更优的选择。
属性命名规则
- 小写标准: 对属性使用小写,以确保在不同数据库引擎中保持大小写不敏感。
FirstName应为first_name. - 外键前缀: 在引用另一个实体时,外键名称应尽量与被引用实体的主键名称匹配,通常通过后缀表示来源或前缀表示目标。例如,如果
Users表有一个user_id,那么Orders表应将其引用为user_id. - 布尔值清晰性: 布尔属性应以问题形式或明确的标志命名(例如,
is_active,has_subscription)而不是像状态或标志.
2. 结构完整性和规范化 ⚖️
一个看起来不错但违反规范化原则的图表会导致数据异常。可维护性要求结构支持高效查询并最小化冗余。
主键
- 显式声明: 每个表都必须有明确的主键。切勿依赖数据库引擎在没有文档说明的情况下隐式生成主键。
- 代理键: 考虑使用代理键(自增整数或UUID)而非自然键(如电子邮件地址或社会安全号码)。自然键可能发生变化,需要在整个数据库中进行级联更新,这既危险又昂贵。
- 复合键: 仅在逻辑上必要时(例如,多对多关联表)才使用复合键。避免在主要实体中使用,因为这会使索引和关系变得复杂。
外键和引用完整性
- 定义关系: 每个外键都必须在图表中明确标识。不要仅依赖命名约定来暗示关系。
- 级联规则: 记录删除和更新的行为。当父记录被删除时,子记录是否应被删除?是否应设为空?这些规则(CASCADE、SET NULL、RESTRICT)必须在设计文档中清晰可见。
- 避免循环依赖: 确保关系不会造成循环依赖,以免导致连接操作无法进行或性能不可预测。
3. 视觉清晰度和布局 🎨
ERD是一种视觉工具。如果布局杂乱,数据模型将难以理解。视觉层次结构有助于读者一目了然地理解系统的架构。
分组与组织
- 功能分组: 将相关实体放在一起。例如,将所有用户管理表放在一起,所有事务表放在一个独立的集群中。
- 逻辑分离: 将只读数据与写入密集型数据分开。如果系统包含报表表,请在视觉上将其与操作表区分开。
- 方向性流动: 布局图表以暗示数据流向。通常这意味着将核心参考数据放在顶部或左侧,而事务或日志数据放在底部或右侧。
连接线
- 正交布线:尽可能使用直角线而非对角线。对角线经常相互交叉,造成视觉干扰。
- 减少交叉:调整实体位置,以减少关系线交叉的次数。交叉的线条会遮挡关系的路径。
- 基数表示:一致地使用标准表示法(Crow’s Foot、Chen 或 UML)。确保“一”和“多”端清晰标明。不要仅依赖线条粗细或颜色来表示基数。
4. 文档与元数据 📝
仅靠图表本身是不够的。元数据提供了理解设计决策背后“原因”的必要上下文。
注释与标注
- 业务逻辑:添加注释以解释特定的业务规则。例如,在“
订单”表上添加的注释可能说明:如果支付状态不是已完成. - 约束:记录唯一约束、检查约束和默认值。这些信息在仅查看模式图时常常被忽略。
- 弃用标记:如果某个实体或属性已被弃用但仍为向后兼容而保留,请明确标记。不要隐藏它,因为它可能仍在旧代码中被引用。
版本控制
- 变更日志:维护变更历史。谁修改了模式?何时修改的?为什么修改?这对于调试生产问题至关重要。
- 版本号:用版本号标记图表(例如 v1.0、v1.1)。当多个数据库迁移同时进行时,这可以避免混淆。
5. 协作与评审流程 🤝
数据库设计很少是孤立的任务。它需要后端工程师、数据分析师和业务相关方的共同参与。
同行评审
- 独立审计:请一位未参与设计的开发人员进行评审。新的视角能够发现逻辑漏洞和命名不一致的问题。
- 领域专家验证: 确保模型准确反映业务领域。数据建模人员可能看到一张表,但业务分析师知道这张表是否真正代表了实际的工作流程。
工具与标准
- 标准化模板: 为所有图表使用模板,以确保组织内不同项目之间的一致性。
- 自动化验证: 使用工具将图表与实际的数据库模式进行验证。图表与代码之间的偏差是常见的错误来源。
6. 维护生命周期 🔄
部署后,ERD 不是静态的。它会不断演变。维护这种演变需要纪律。
模式漂移管理
- 定期同步: 定期从生产数据库重新生成图表,以确保其与实际情况一致。
- 迁移脚本: ERD 的每一次变更都必须对应一个迁移脚本。在未更新图表的情况下,绝不能手动修改数据库。
- 影响分析: 在更改主键或删除列之前,分析哪些下游报表或应用程序依赖于它。
性能考虑
- 索引策略: 记录哪些列被索引以及原因。这有助于未来的开发人员理解查询优化的决策。
- 分区: 如果一张表非常庞大,请在图表中注明分区策略。这会影响数据的查询和维护方式。
7. 常见陷阱与反模式 🚫
避免错误与遵循最佳实践同样重要。以下是常见错误与推荐做法的对比。
| 陷阱 | 推荐做法 | 原因 |
|---|---|---|
| 通用名称 例如, 表1, 数据 |
具体名称 例如, 客户资料, 产品库存 |
具体名称使开发人员无需外部文档即可理解数据。 |
| 隐藏的关系 表之间没有绘制连线 |
明确的外键 连线清晰且带有标签 |
隐式关系会导致数据完整性违规和混淆。 |
| 过度规范化 表太多且过于细小 |
适当的规范化 第三范式与性能需求之间的平衡 |
过多的连接会显著降低查询性能。 |
| 缺少元数据 没有描述或类型 |
丰富的元数据 包含数据类型、约束和注释 |
元数据对于入职培训和长期维护至关重要。 |
| 硬编码值 状态码如 1, 2在图表中 |
枚举类型 使用查找表或显式枚举 |
没有图例的硬编码整数毫无意义,且容易发生变化。 |
长期可持续性的结论
创建一个清晰的ERD是对项目未来的投资。它能减轻开发者的认知负担,降低数据损坏的风险,并确保系统能够持续演进而无需完全重写。通过遵循严格的命名规范、保持视觉清晰度并记录元数据,你将建立起一个支持可扩展增长的基础。今天在设计上投入的努力,可以避免明天维护时的混乱。
请记住,ERD是一个动态文档。它需要像其所代表的源代码一样受到同等程度的维护和版本控制。定期审查、遵守标准以及对准确性的承诺,将使你的数据架构保持稳健,团队保持高效。
核心要点 ✅
- 一致性是关键:在整个项目中坚持使用一种命名规范和一种视觉风格。
- 记录一切:不要假设代码能自我解释。为业务逻辑和约束添加注释。
- 定期验证:确保图表与实际数据库状态一致,以防止偏差。
- 优先考虑可读性:如果一张图表难以阅读,那么它也难以维护。简化连接并进行逻辑分组。
- 为变化做好规划:面向未来进行设计。尽可能使用代理键,并避免硬性依赖。