











Merancang skema basis data yang kuat untuk platform media sosial membutuhkan pemahaman mendalam tentang bagaimana pengguna berinteraksi, berbagi, dan mengonsumsi informasi. Berbeda dengan sistem transaksional tradisional, jaringan sosial melibatkan hubungan banyak-ke-banyak yang kompleks, struktur data rekursif, dan persyaratan skala besar. Diagram Entitas-Relasi (ERD) berfungsi sebagai gambaran rancangan untuk interaksi ini, memastikan integritas data sambil mendukung pertumbuhan cepat. Panduan ini mengeksplorasi strategi-strategi kritis untuk memodelkan data media sosial secara efektif.
Memahami Tantangan Inti 🧩
Aplikasi media sosial bukan sekadar penyimpanan konten; mereka adalah jaringan dinamis dari hubungan. Posting blog sederhana berbeda secara signifikan dari feed media sosial karena lapisan keterlibatan. Suka, bagikan, komentar, dan ikuti menciptakan jaringan koneksi yang harus dimodelkan secara akurat. Pemodelan yang buruk mengakibatkan kinerja kueri yang lambat, ketidakkonsistenan data, dan kesulitan dalam menerapkan fitur seperti feed berita atau saran teman.
- Volume:Platform media sosial menghasilkan jutaan peristiwa per detik.
- Kecepatan:Data tiba dalam aliran waktu nyata yang harus diproses segera.
- Variasi:Konten mencakup teks, gambar, video, metadata, dan data lokasi.
- Hubungan:Nilai inti terletak pada koneksi antar entitas.
Ketika membuat ERD, tujuan utamanya adalah menyeimbangkan normalisasi dengan kinerja. Normalisasi berlebihan dapat membuat operasi join terlalu mahal untuk bacaan frekuensi tinggi. Denormalisasi berlebihan dapat menyebabkan redundansi data dan masalah konsistensi. Bagian-bagian berikut menjelaskan entitas dan hubungan spesifik yang mendefinisikan domain ini.
Menentukan Entitas Inti 🔑
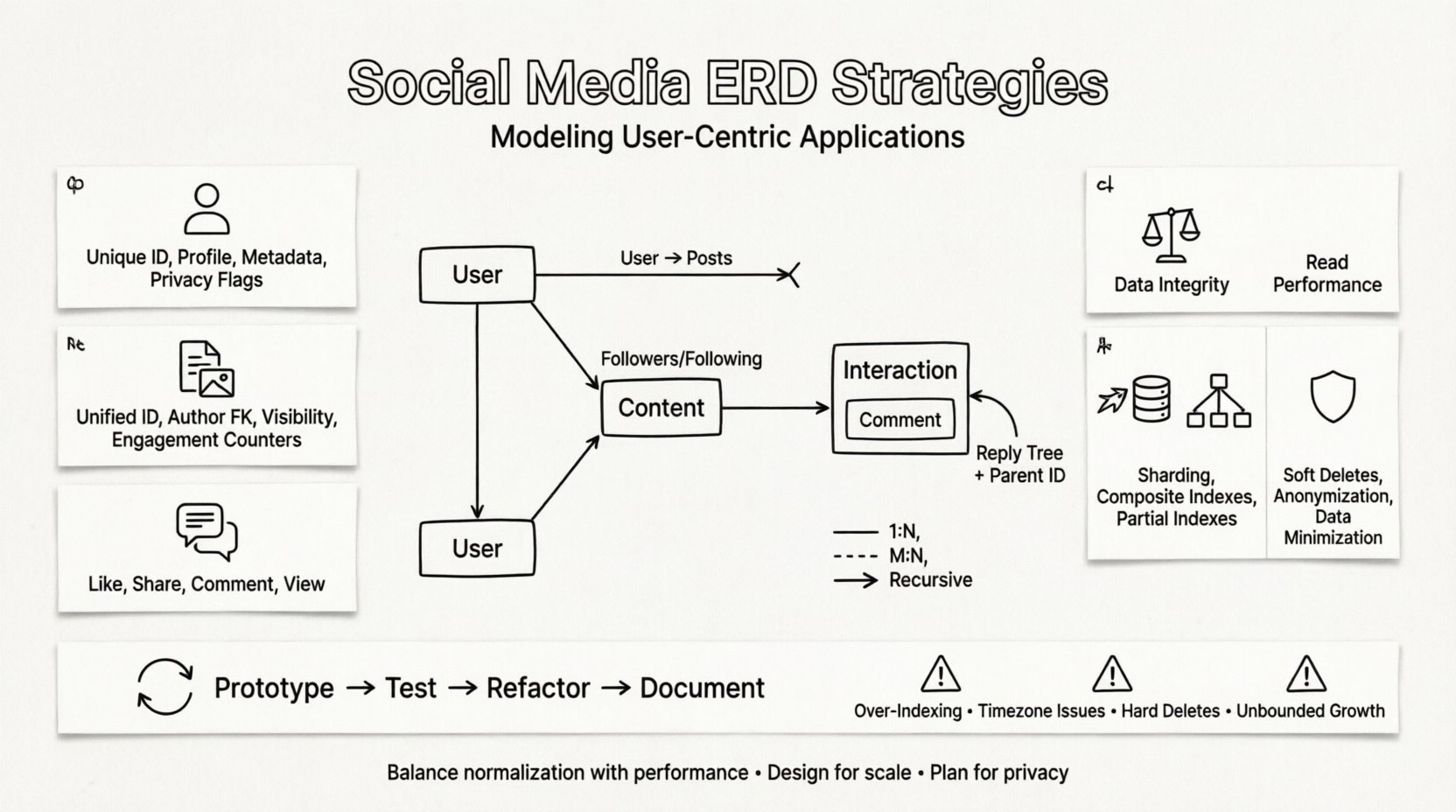
Setiap sistem media sosial berpusat pada beberapa entitas dasar. Mengidentifikasi entitas-entitas ini dengan benar adalah langkah pertama dalam membuat skema yang dapat diskalakan. Entitas-entitas ini mewakili blok bangunan inti dari aplikasi.
1. Entitas Pengguna 👤
Pengguna adalah simpul pusat dalam jaringan. Entitas ini menyimpan detail otentikasi, informasi profil, dan preferensi. Harus dirancang untuk menangani jutaan catatan secara efisien.
- Identifikasi Unik:Kunci pengganti lebih disukai daripada kunci alami untuk kinerja dan anonimitas.
- Data Profil:Nama, bio, avatar, dan status verifikasi.
- Metadata:Timestamp untuk pembuatan akun, login terakhir, dan penghapusan.
- Bendera Privasi:Pengaturan yang mengendalikan visibilitas data bagi pengguna lain.
2. Entitas Konten 📝
Konten adalah bahan bakar platform media sosial. Ini mencakup posting, cerita, gambar, video, dan komentar. Skema yang fleksibel diperlukan karena jenis konten yang berbeda memiliki atribut yang berbeda.
- ID Terpadu:ID umum yang terhubung ke tabel konten tertentu.
- Referensi Penulis: Kunci asing yang menghubungkan ke entitas Pengguna.
- Ruang Lingkup Visibilitas: Publik, pribadi, hanya teman, atau kelompok tertentu.
- Penghitung Keterlibatan: Jumlah yang disimpan sementara untuk suka dan komentar untuk mengurangi beban kueri.
3. Entitas Interaksi 💬
Interaksi mewakili tindakan yang dilakukan pengguna terhadap konten atau pengguna lain. Ini adalah transaksi berjumlah besar yang sering menentukan persyaratan kinerja sistem.
- Suka: Status biner antara pengguna dan konten.
- Bagikan: Referensi ke konten asli dengan konteks baru.
- Komentar: Hubungan hierarkis atau berbentuk benang terhadap konten.
- Tampilan: Sering dicatat secara terpisah karena volume yang tinggi dan pentingnya yang lebih rendah terhadap integritas.
Pemodelan Hubungan 🕸️
Kompleksitas sebenarnya media sosial terletak pada hubungan antar entitas. Teknik pemodelan relasional standar sering kesulitan menghadapi sifat rekursif graf sosial. Perhatian khusus harus diberikan pada bagaimana koneksi-koneksi ini disimpan.
Hubungan Satu-ke-Banyak
Ini adalah yang paling umum dan langsung. Misalnya, satu pengguna dapat memiliki banyak pos, tetapi satu pos hanya dimiliki oleh satu pengguna. Ini dimodelkan menggunakan kunci asing di tabel anak.
- Contoh: ID Pengguna di tabel Pos.
- Manfaat: Pemulihan cepat semua pos untuk profil tertentu.
- Kendala: Memaksa integritas referensial secara otomatis.
Hubungan Banyak-ke-Banyak
Pengikut dan yang diikuti adalah contoh klasik. Satu pengguna mengikuti banyak orang lain, dan satu pengguna diikuti oleh banyak orang lain. Ini membutuhkan tabel sambungan untuk menyelesaikan hubungan.
- Tabel Sambungan: Berisi ID Pengguna A dan ID Pengguna B.
- Waktu Penanda:Ketika tindakan berikut terjadi.
- Status:Tertunda, diterima, atau diblokir.
- Kinerja:Pengindeksan sangat penting pada kedua kunci asing.
Hubungan Rekursif
Beberapa hubungan melibatkan tipe entitas yang sama. Komentar dapat memiliki balasan terhadap balasan. Ini menciptakan struktur pohon yang sulit diquery dalam model relasional standar.
- ID Induk:Kunci asing yang mengarah ke ID Komentar.
- Kedalaman:Membatasi kedalaman rekursi mencegah loop tak terbatas.
- Jalur yang Dibuat Nyata:Menyimpan jalur pohon untuk traversal yang lebih cepat.
| Jenis Hubungan | Contoh | Strategi Implementasi | Dampak Kinerja |
|---|---|---|---|
| Satu-ke-Banyak | Pengguna – Postingan | Kunci Asing di Anak | Rendah (Indeks Standar) |
| Banyak-ke-Banyak | Pengguna – Mengikuti | Tabel Sambungan | Sedang (Overhead Join) |
| Rekursif | Komentar – Balasan | Kunci Asing yang Mengacu pada Diri Sendiri | Tinggi (Kueri yang Kompleks) |
| Asosiatif | Tag – Pengguna | Kunci Komposit | Sedang (Banyak Pencarian) |
Normalisasi vs. Denormalisasi ⚖️
Dalam sistem media sosial, kinerja baca sering kali lebih penting daripada kinerja tulis. Pengguna mengharapkan feed dapat dimuat secara instan, bahkan ketika melibatkan jutaan catatan. Ini mengharuskan keseimbangan yang hati-hati antara normalisasi dan denormalisasi.
Kasus untuk Normalisasi
Normalisasi menjamin integritas data dan mengurangi redundansi. Ini sangat penting untuk data inti yang tidak sering berubah.
- Konsistensi Data:Pembaruan terjadi di satu tempat.
- Efisiensi Penyimpanan:Penyimpanan data duplikat yang lebih sedikit.
- Mudah Diperawat:Lebih mudah untuk menerapkan aturan bisnis.
Kasus untuk Denormalisasi
Denormalisasi melibatkan duplikasi data untuk mengurangi jumlah join yang diperlukan saat membaca data. Ini umum terjadi pada feed media sosial.
- Kecepatan Baca:Lebih sedikit join berarti eksekusi kueri yang lebih cepat.
- Penyimpanan Sementara (Caching):Jumlah teragregasi (misalnya, total suka) disimpan secara langsung.
- Beban Tulis:Pembaruan harus disebarkan ke semua salinan.
Pendekatan Hibrida
Strategi praktis melibatkan normalisasi skema inti sambil melakukan denormalisasi metrik yang sering dibaca. Misalnya, simpan nama pengguna dalam tabel pos bersama dengan ID pengguna. Ini menghindari join saat menampilkan pos, dengan biaya logika sinkronisasi yang sesekali diperlukan.
Strategi Skalabilitas untuk ERD 🚀
Seiring pertumbuhan basis pengguna, skema harus berkembang untuk menangani beban yang meningkat. Skalabilitas vertikal memiliki batasan; skalabilitas horisontal membutuhkan pertimbangan khusus terhadap skema.
Pembagian (Partitioning)
Pembagian membagi tabel besar menjadi bagian-bagian kecil yang lebih mudah dikelola. Dalam media sosial, data sering dibagi berdasarkan ID pengguna atau tanggal.
- Pembagian Horisontal: Membagi pengguna ke shard yang berbeda berdasarkan rentang ID.
- Pembagian Vertikal: Memindahkan kolom yang jarang diakses ke dalam tabel terpisah.
- Pembagian Berdasarkan Tanggal: Mengarsipkan pos lama ke dalam tabel penyimpanan dingin.
Strategi Pengindeksan
Indeks sangat penting untuk kinerja kueri, tetapi mereka memperlambat operasi tulis. Diperlukan pendekatan strategis terhadap pengindeksan.
- Indeks Komposit: Menutupi pola kueri umum (misalnya, ID Pengguna + Timestamp).
- Indeks Parsial: Mengindeks hanya baris yang relevan (misalnya, pos aktif).
- Indeks Pencarian: Menggunakan mesin pencari teks penuh untuk penemuan konten.
Pertimbangan Privasi dan Kepatuhan 🛡️
Pemodelan data modern harus mempertimbangkan regulasi privasi seperti GDPR dan CCPA. Desain skema memengaruhi seberapa mudah data dapat di-anonimkan atau dihapus.
Hak untuk Dilupakan
Pengguna dapat meminta penghapusan data mereka. ERD harus mendukung penghapusan cascading atau penghapusan lunak tanpa melanggar integritas referensial.
- Penghapusan Lunak: Menambahkan flag “is_deleted” alih-alih menghapus baris.
- Data Terlantar: Menangani data yang merujuk ke pengguna yang telah dihapus.
- Anonimisasi: Mengganti identifikasi pribadi dengan hash.
Minimisasi Data
Hanya simpan data yang benar-benar diperlukan. Pengumpulan metadata berlebihan meningkatkan biaya penyimpanan dan risiko privasi.
- Kebijakan Retensi: Penghapusan otomatis log setelah periode tertentu.
- Izin Berbasis Granular: Kontrol akses pada tingkat baris.
- Enkripsi: Bidang sensitif dienkripsi saat dalam penyimpanan.
Penanganan Metadata dan Log 📉
Di luar entitas inti, sistem menghasilkan sejumlah besar metadata. Ini mencakup analitik, log kesalahan, dan jejak audit. Ini sebaiknya tidak memenuhi skema transaksional utama.
Pemisahan Tanggung Jawab
Jaga agar basis data transaksional tetap bersih. Alihkan pencatatan berat dan analitik ke sistem yang terpisah.
- Aliran Acara:Gunakan antrian pesan untuk pencatatan asinkron.
- Tabel Analitik:Tabel terpisah untuk tren historis.
- Data Deret Waktu:Penyimpanan khusus untuk metrik seiring waktu.
Proses Desain Iteratif 🔄
ERD jarang sempurna pada draft pertama. Kebutuhan media sosial berkembang pesat seiring fitur baru diperkenalkan. Proses desain harus bersifat iteratif.
- Prototipe:Bangun skema minimal yang layak untuk fitur inti.
- Uji Coba:Uji beban dengan volume data yang realistis.
- Refaktor:Sesuaikan hubungan berdasarkan hambatan kinerja.
- Dokumentasi:Jaga diagram yang selalu diperbarui untuk pengembang di masa depan.
Jebakan Umum yang Harus Dihindari ⚠️
Bahkan arsitek berpengalaman membuat kesalahan saat memodelkan data sosial. Mengenali pola-pola ini membantu mencegah masalah di masa depan.
- Indeks Berlebihan:Terlalu banyak indeks secara signifikan memperlambat operasi penulisan.
- Mengabaikan Zona Waktu:Menyimpan timestamp tanpa konteks zona waktu menyebabkan kebingungan.
- Nilai yang Dikodekan Secara Keras:Hindari menyematkan logika bisnis dalam skema (misalnya, nilai status tertentu).
- Mengabaikan Penghapusan Lembut:Penghapusan keras dapat merusak keterikatan kunci asing di seluruh jaringan.
- Pertumbuhan Tak Terbatas: Gagal mengarsip data lama menyebabkan pembengkakan tabel.
Pertimbangan Akhir untuk Pertumbuhan Masa Depan 🔮
Membangun platform media sosial adalah upaya jangka panjang. Model data harus cukup fleksibel untuk menampung perubahan tanpa perlu menulis ulang secara keseluruhan. Fokus pada kejelasan, skalabilitas, dan kemudahan pemeliharaan. Tinjauan rutin terhadap skema berdasarkan pola penggunaan dunia nyata memastikan sistem tetap kuat saat berkembang.
- Versi: Rencanakan migrasi skema yang mendukung kompatibilitas mundur.
- Pemantauan: Pantau kinerja query untuk mengidentifikasi kelemahan skema sejak dini.
- Umpan Balik Komunitas: Dengarkan bagaimana data sebenarnya digunakan oleh tim teknik.
Dengan mengikuti strategi-strategi ini, pengembang dapat menciptakan fondasi yang kuat untuk aplikasi berbasis pengguna. ERD bukan hanya sebuah diagram; ia adalah integritas struktural seluruh platform. Perencanaan yang cermat sekarang mencegah utang teknis yang signifikan di masa depan.