











ソーシャルメディアプラットフォーム用の堅牢なデータベーススキーマを設計するには、ユーザーがどのように相互作用し、情報を共有・消費するかを深く理解する必要がある。従来のトランザクション系システムとは異なり、ソーシャルネットワークは複雑な多対多の関係、再帰的なデータ構造、そして大規模なスケーリング要件を伴う。エンティティ関係図(ERD)は、これらの相互作用の設計図として機能し、データの整合性を保ちながら急速な成長をサポートする。本ガイドでは、ソーシャルメディアのデータを効果的にモデリングするための重要な戦略を検討する。
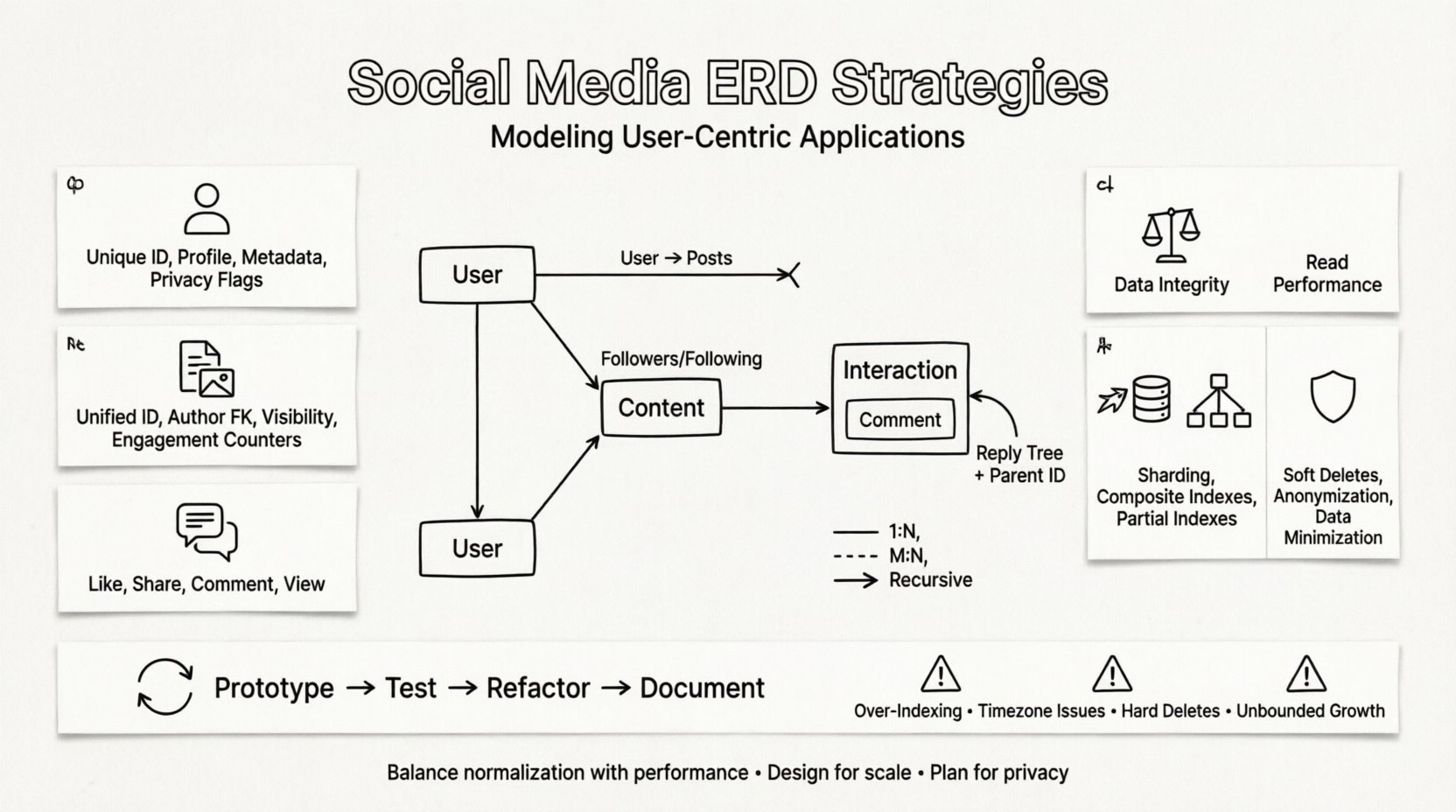
コアの課題を理解する 🧩
ソーシャルメディアアプリケーションは単なるコンテンツの保管庫ではない。それらは動的な関係のネットワークである。シンプルなブログ投稿とソーシャルメディアのフィードは、エンゲージメント層の存在により大きく異なる。いいね、シェア、コメント、フォローといった要素が、正確にモデリングされなければならない関係の網を形成する。不適切なモデリングは、クエリの実行速度の低下、データの不整合、ニュースフィードや友達の提案機能の実装の困難さを引き起こす。
- ボリューム:ソーシャルプラットフォームは1秒間に数百万件のイベントを生成する。
- ベロシティ:データはリアルタイムのストリームとして到着し、即座に処理されなければならない。
- バリエーション:コンテンツにはテキスト、画像、動画、メタデータ、位置情報が含まれる。
- 関係性:コアの価値は、エンティティ間のつながりにある。
ERDを構築する際の主な目的は、正規化とパフォーマンスのバランスを取ることである。過剰な正規化は、高頻度の読み取りに対して結合処理がコスト过高になる。一方、過剰な非正規化はデータの重複や整合性の問題を引き起こす。以下のセクションでは、この分野を定義する具体的なエンティティと関係性について詳述する。
コアエンティティの定義 🔑
すべてのソーシャルメディアシステムは、いくつかの基本的なエンティティの周囲を回転している。これらを正しく特定することは、スケーラブルなスキーマを作成する第一歩である。これらのエンティティはアプリケーションのコアとなる構成要素を表す。
1. ユーザーエンティティ 👤
ユーザーはネットワークの中心的なノードである。このエンティティは認証情報、プロフィール情報、および設定を格納する。数百万件のレコードを効率的に処理できるように設計しなければならない。
- 一意の識別子:パフォーマンスと匿名性の観点から、自然キーではなくサロゲートキーが推奨される。
- プロフィールデータ:名前、自己紹介文、アバター、認証ステータス。
- メタデータ:アカウント作成時刻、最終ログイン時刻、削除時刻のタイムスタンプ。
- プライバシー設定:他のユーザーに対するデータの可視性を制御する設定。
2. コンテンツエンティティ 📝
コンテンツはソーシャルプラットフォームの燃料である。投稿、ストーリー、画像、動画、コメントを含む。コンテンツの種類によって属性が異なるため、柔軟なスキーマが必要となる。
- 統合ID:特定のコンテンツテーブルにリンクする汎用的なID。
- 著者参照: Userエンティティへの外部キー。
- 表示範囲: 公開、非公開、友達限定、または特定のグループ。
- エンゲージメントカウンター: クエリ負荷を軽減するためのいいねやコメントのキャッシュ済みカウント。
3. インタラクションエンティティ 💬
インタラクションは、ユーザーがコンテンツや他のユーザーに対して行う操作を表します。これらは高頻度のトランザクションであり、システムのパフォーマンス要件を左右することが多いです。
- いいね: ユーザーとコンテンツの間の2値状態。
- 共有: 新しい文脈を持つオリジナルコンテンツへの参照。
- コメント: コンテンツへの階層的またはスレッド形式の関係。
- 閲覧: 高頻度かつ整合性の重要度が低いことから、別途ログ記録されることが多い。
関係のモデリング 🕸️
ソーシャルメディアの真の複雑さは、エンティティ間の関係にあります。標準的なリレーショナルモデリング手法は、ソーシャルグラフの再帰的性質に対処しづらいことがよくあります。これらの接続がどのように格納されるかに特に注意を払う必要があります。
1対多の関係
これらは最も一般的で直感的な関係です。たとえば、1人のユーザーが複数の投稿を持つことができますが、1つの投稿は1人のユーザーにのみ所属します。これは子テーブルに外部キーを使用してモデル化されます。
- 例: 投稿テーブル内のユーザーID。
- 利点: 特定のプロフィールのすべての投稿を高速に取得できる。
- 制約: 参照整合性を自動的に維持する。
多対多の関係
フォロワーとフォローは古典的な例です。1人のユーザーが複数のユーザーをフォローし、1人のユーザーは複数のユーザーからフォローされます。この関係を解消するには、中間テーブルが必要です。
- 中間テーブル: ユーザーID AとユーザーID Bを含む。
- タイムスタンプ: そのフォローアクションが発生したとき。
- ステータス: 保留中、承認済み、またはブロック済み。
- パフォーマンス: 外部キーの両方でインデックス作成が重要です。
再帰的関係
一部の関係は同じエンティティタイプを含みます。コメントには返信の返信が含まれる場合があります。これにより、標準的なリレーショナルモデルでは問い合わせが難しいツリー構造が作成されます。
- 親ID: コメントIDを指す外部キー。
- 深さ: 再帰の深さを制限することで、無限ループを防ぎます。
- マテリアライズドパス: より高速な走査のために、ツリーのパスを保存します。
| 関係の種類 | 例 | 実装戦略 | パフォーマンスへの影響 |
|---|---|---|---|
| 1対多 | ユーザー – 投稿 | 子テーブルの外部キー | 低(標準インデックス) |
| 多対多 | ユーザー – フォロー | 結合テーブル | 中(結合のオーバーヘッド) |
| 再帰的 | コメント – 返信 | 自己参照外部キー | 高(複雑なクエリ) |
| 関連型 | タグ – ユーザー | 複合キー | 中程度(検索が多く) |
正規化 vs. 非正規化 ⚖️
ソーシャルメディアシステムでは、読み取り性能が書き込み性能を上回ることが多い。ユーザーは、何百万ものレコードが関係していても、フィードが即座に読み込まれることを期待する。そのため、正規化と非正規化の間で慎重なバランスを取る必要がある。
正規化の利点
正規化はデータの整合性を保証し、重複を減らす。頻繁に変化しないコアデータには不可欠である。
- データの一貫性:更新は1か所で行われる。
- ストレージ効率:重複データのストレージが減る。
- 保守性:ビジネスルールの適用が容易になる。
非正規化の利点
非正規化は、読み取り時に必要な結合の数を減らすためにデータを複製することを含む。これはソーシャルフィードで一般的である。
- 読み取り速度:結合の数が減るため、クエリ実行が速くなる。
- キャッシュ:集計された数値(例:いいねの合計)を直接保存する。
- 書き込みオーバーヘッド:更新はすべてのコピーに伝搬しなければならない。
ハイブリッドアプローチ
実用的な戦略は、コアスキーマを正規化しつつ、頻繁に読み込まれるメトリクスを非正規化することである。例えば、ユーザーIDとともに投稿テーブルにユーザー名を保存する。これにより、投稿を表示する際に結合を回避できるが、時折の同期ロジックのコストがかかる。
ERDのスケーラビリティ戦略 🚀
ユーザー数が増えるにつれて、スキーマは増加する負荷に対応するために進化しなければならない。垂直スケーリングには限界がある。水平スケーリングには、特定のスキーマの配慮が必要となる。
パーティショニング
パーティショニングは、大きなテーブルを小さく管理しやすい部分に分割する。ソーシャルメディアでは、データがユーザーIDや日付でパーティション分けられることが多い。
- 水平パーティショニング:IDの範囲に基づいて、ユーザーを異なるシャードに分割する。
- 垂直パーティショニング: 頻繁にアクセスされない列を別テーブルに移動する。
- 日付パーティショニング: 古い投稿をコールドストレージテーブルにアーカイブする。
インデックス戦略
インデックスはクエリパフォーマンスにとって不可欠だが、書き込みを遅くする。戦略的なインデックス作成アプローチが必要である。
- 複合インデックス: 一般的なクエリパターンをカバーする(例:ユーザーID + タイムスタンプ)。
- 部分インデックス: 関連する行のみをインデックス化する(例:有効な投稿)。
- 検索インデックス: コンテンツ検出にフルテキスト検索エンジンを使用する。
プライバシーおよびコンプライアンスに関する考慮事項 🛡️
現代のデータモデリングは、GDPRやCCPAなどのプライバシー規制を考慮しなければならない。スキーマ設計は、データを匿名化または削除しやすさに影響する。
忘れられる権利
ユーザーは自身のデータの削除を要求できる。ERDは参照整合性を損なわずに、カスケード削除またはソフト削除をサポートしなければならない。
- ソフト削除: 行を削除する代わりに「is_deleted」フラグを追加する。
- 孤立データ: 削除されたユーザーを参照するデータの処理。
- 匿名化: 個人識別情報をハッシュに置き換える。
データ最小化
厳密に必要なデータのみを保存する。過剰なメタデータの収集は、ストレージコストとプライバシーリスクを増加させる。
- 保持ポリシー: 決定された期間後にログを自動削除する。
- 細粒度のアクセス権限: 行レベルのアクセス制御。
- 暗号化: 敏感なフィールドを静止状態で暗号化する。
メタデータおよびログの取り扱い 📉
コアエンティティの外には、システムが膨大な量のメタデータを生成する。これには分析データ、エラーログ、監査トレースが含まれる。これらはメインのトランザクショナルスキーマを混雑させないよう注意すべきである。
関心の分離
トランザクショナルデータベースを整理しておこう。重いログ記録や分析処理は別システムに移譲する。
- イベントストリーム:非同期ログ記録にはメッセージキューを使用する。
- 分析テーブル:歴史的トレンド用に別々のテーブルを用意する。
- 時系列データ:時間経過に伴うメトリクス用の専用ストレージ。
反復的な設計プロセス 🔄
ERDは初稿で完璧な状態になることはめったにない。新しい機能が導入されるにつれて、ソーシャルメディアの要件は急速に変化する。設計プロセスは反復的であるべきである。
- プロトタイプ:コア機能用の最小限の実用的スキーマを構築する。
- テスト:現実的なデータ量で負荷テストを行う。
- リファクタリング:パフォーマンスのボトルネックに基づいて関係性を調整する。
- ドキュメント:将来の開発者向けに、常に最新の図を維持する。
避けるべき一般的な落とし穴 ⚠️
経験豊富なアーキテクトですら、ソーシャルデータのモデル化においてミスを犯すことがある。これらのパターンを認識することで、将来の問題を防ぐことができる。
- 過剰なインデックス化:インデックスが多すぎると、書き込み操作が著しく遅くなる。
- タイムゾーンの無視:タイムゾーンの文脈なしにタイムスタンプを保存すると、混乱を招く。
- ハードコードされた値:スキーマ内にビジネスロジックを埋め込まない(例:特定のステータス値など)。
- ソフトデリートの無視:ハード削除はネットワーク全体の外部キー制約を破壊する可能性がある。
- 制限のない成長: 古いデータをアーカイブしないと、テーブルの肥大化が起こる。
将来の成長のための最終的な考慮事項 🔮
ソーシャルメディアプラットフォームの構築は長期的な取り組みである。データモデルは、完全な再設計を必要とせずに変化に対応できるほど柔軟でなければならない。明確性、スケーラビリティ、保守性に注力する。実際の使用状況に基づいてスキーマを定期的に見直すことで、システムがスケーリングする際にも堅牢性を保つことができる。
- バージョン管理:後方互換性をサポートするスキーマ移行の計画を立てる。
- モニタリング:クエリのパフォーマンスを追跡して、スキーマの弱点を早期に特定する。
- コミュニティからのフィードバック:エンジニアリングチームが実際にデータをどのように使っているかを聞く。
これらの戦略に従うことで、開発者はユーザー中心のアプリケーションの堅固な基盤を構築できる。ERDは単なる図面ではない。それは全体のプラットフォームの構造的整合性そのものである。今、慎重な計画を立てることで、将来の大きな技術的負債を防ぐことができる。