











Projektowanie solidnej schematu bazy danych dla platform mediów społecznościowych wymaga głębokiego zrozumienia sposobu, w jaki użytkownicy wzajemnie oddziałują, dzielą się informacjami i je konsumują. W przeciwieństwie do tradycyjnych systemów transakcyjnych, sieci społecznościowe obejmują złożone relacje wiele do wielu, rekurencyjne struktury danych oraz wymagania dotyczące ogromnej skali. Diagram związków encji (ERD) pełni rolę projektu tych interakcji, zapewniając integralność danych oraz wspierając szybki rozwój. Niniejszy przewodnik omawia kluczowe strategie modelowania danych mediów społecznościowych w sposób skuteczny.
Zrozumienie podstawowego wyzwania 🧩
Aplikacje mediów społecznościowych to nie tylko repozytoria treści; są to dynamiczne sieci relacji. Prosta publikacja blogowa znacznie różni się od strony mediów społecznościowych ze względu na warstwę zaangażowania. Polubienia, udostępniania, komentarze i subskrypcje tworzą sieć połączeń, które muszą być precyzyjnie zamodelowane. Zła modelacja prowadzi do wolnej wydajności zapytań, niezgodności danych oraz trudności w implementacji funkcji takich jak kanały informacyjne lub propozycje znajomych.
- Objętość:Platformy społecznościowe generują miliony zdarzeń na sekundę.
- Prędkość:Dane przychodzą w strumieniach w czasie rzeczywistym, które muszą być przetwarzane od razu.
- Różnorodność:Zawartość obejmuje tekst, obrazy, filmy, metadane oraz dane lokalizacyjne.
- Relacje:Główna wartość tkwi w połączeniach między encjami.
Podczas tworzenia ERD głównym celem jest zrównoważenie normalizacji z wydajnością. Nadmierna normalizacja może sprawić, że łączenia stają się zbyt kosztowne dla częstych odczytów. Nadmierna denormalizacja może prowadzić do nadmiarowości danych oraz problemów z spójnością. Poniższe sekcje szczegółowo opisują konkretne encje i relacje, które definiują tę dziedzinę.
Definiowanie podstawowych encji 🔑
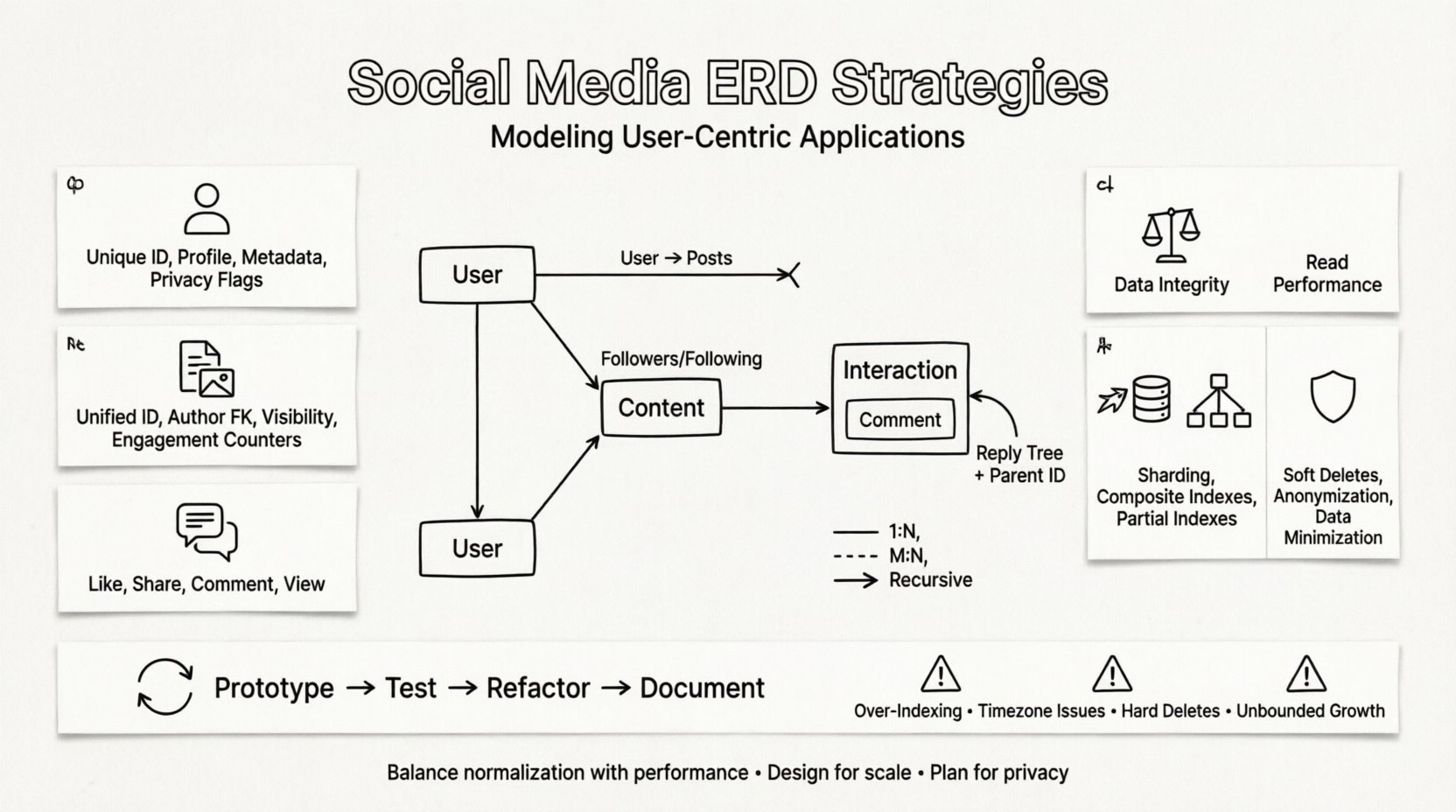
Każdy system mediów społecznościowych opiera się na kilku podstawowych encjach. Poprawne ich zidentyfikowanie to pierwszy krok w tworzeniu skalowalnego schematu. Te encje reprezentują podstawowe elementy budowlane aplikacji.
1. Encja Użytkownika 👤
Użytkownik jest centralnym węzłem w sieci. Ta encja przechowuje dane uwierzytelniania, informacje o profilu oraz preferencje. Musi być zaprojektowana w taki sposób, aby skutecznie obsługiwać miliony rekordów.
- Unikalny identyfikator:Zalecane jest użycie klucza zastępczego zamiast kluczy naturalnych pod kątem wydajności i anonimowości.
- Dane profilu: Imię, biogram, awatar oraz status weryfikacji.
- Metadane:Zegary czasu dla utworzenia konta, ostatniego logowania i usunięcia.
- Flagi prywatności:Ustawienia kontrolujące widoczność danych dla innych użytkowników.
2. Encja Zawartości 📝
Zawartość to paliwo dla platform mediów społecznościowych. Obejmuje posty, historie, obrazy, filmy i komentarze. Wymagany jest elastyczny schemat, ponieważ różne typy treści mają różne atrybuty.
- Unikalny identyfikator:Ogólny identyfikator łączący się z konkretnymi tabelami zawartości.
- Odwołanie do autora: Klucz obcy łączący z encją User.
- Zakres widoczności: Publiczne, prywatne, tylko dla znajomych lub określone grupy.
- Liczniki zaangażowania: Zapisane liczby polubień i komentarzy w celu zmniejszenia obciążenia zapytań.
3. Encja Interakcji 💬
Interakcje reprezentują działania, które użytkownicy podejmują wobec treści lub innych użytkowników. Są to transakcje o wysokim obciążeniu, które często decydują o wymaganiach dotyczących wydajności systemu.
- Polubienie: Stan dwustanowy między użytkownikiem a treścią.
- Udostępnienie: Odwołanie do oryginalnej treści z nowym kontekstem.
- Komentarz: Relacja hierarchiczna lub wątkowa wobec treści.
- Oglądanie: Często logowane oddzielnie z powodu dużego obciążenia i niższego znaczenia dla integralności.
Modelowanie relacji 🕸️
Prawdziwa złożoność mediów społecznościowych tkwi w relacjach między encjami. Standardowe techniki modelowania relacyjnego często mają trudności z rekurencyjną naturą grafów społecznościowych. Należy zwrócić szczególną uwagę na sposób przechowywania tych połączeń.
Relacje jeden do wielu
Są to najbardziej typowe i proste relacje. Na przykład jeden użytkownik może mieć wiele wpisów, ale każdy wpis należy tylko do jednego użytkownika. Relacja ta jest modelowana za pomocą klucza obcego w tabeli potomnej.
- Przykład: ID użytkownika w tabeli Posty.
- Zalety: Szybkie pobieranie wszystkich wpisów dla określonego profilu.
- Ograniczenie: Automatycznie zapewnia integralność referencyjną.
Relacje wiele do wielu
Śledzący i śledzeni to klasyczny przykład. Jeden użytkownik śledzi wielu innych, a jeden użytkownik jest śledzony przez wielu innych. Wymaga to tabeli pośredniej do rozwiązania tej relacji.
- Tabela pośrednia: Zawiera ID użytkownika A i ID użytkownika B.
- Znaczniki czasu: Gdy nastąpiła powyższa akcja.
- Status: Oczekujące, zaakceptowane lub zablokowane.
- Wydajność: Indeksowanie jest kluczowe dla obu kluczy obcych.
Relacje rekurencyjne
Niektóre relacje dotyczą tej samej typu encji. Komentarz może mieć odpowiedzi na odpowiedzi. Powoduje to strukturę drzewa, która jest trudna do zapytania w standardowych modelach relacyjnych.
- ID rodzica: Klucz obcy wskazujący na ID komentarza.
- Głębokość: Ograniczanie głębokości rekursji zapobiega pętlom nieskończonym.
- Scieżki materializowane: Przechowywanie ścieżki drzewa w celu szybszego przeszukiwania.
| Typ relacji | Przykład | Strategia implementacji | Wpływ na wydajność |
|---|---|---|---|
| Jeden do wielu | Użytkownik – Posty | Klucz obcy w dziecku | Niski (standardowe indeksowanie) |
| Wiele do wielu | Użytkownik – Obserwuje | Tabela pośrednicząca | Średni (nakład połączeń) |
| Rekurencyjny | Komentarz – Odpowiedź | Samodzielny klucz obcy | Wysoki (złożone zapytania) |
| Asocjacyjny | Tag – Użytkownik | Klucze złożone | Średnia (dużo wyszukiwań) |
Normalizacja vs. Denormalizacja ⚖️
W systemach mediów społecznościowych wydajność odczytu często przeważa nad wydajnością zapisu. Użytkownicy oczekują, że kanały będą się ładować natychmiastowo, nawet gdy biorą udział miliony rekordów. Wymaga to starannego dopasowania między normalizacją a denormalizacją.
Argumenty na rzecz normalizacji
Normalizacja zapewnia integralność danych i zmniejsza nadmiarowość. Jest niezbędna dla danych głównych, które rzadko się zmieniają.
- Spójność danych: Aktualizacje odbywają się w jednym miejscu.
- Efektywność przechowywania: Mniej powtarzającego się przechowywania danych.
- Łatwość utrzymania: Łatwiejsze stosowanie reguł biznesowych.
Argumenty na rzecz denormalizacji
Denormalizacja polega na powielaniu danych w celu zmniejszenia liczby połączeń wymaganych podczas odczytu. Jest to powszechne w kanałach społecznościowych.
- Szybkość odczytu: Mniejsza liczba połączeń oznacza szybsze wykonywanie zapytań.
- Buforowanie: Agregowane liczby (np. całkowita liczba polubień) przechowywane bezpośrednio.
- Nadmiar zapisu: Aktualizacje muszą być rozprowadzane do wszystkich kopii.
Hybrydowy podejście
Prawdopodobne podejście polega na normalizacji podstawowej schematu, jednocześnie denormalizując często odczytywane metryki. Na przykład, przechowuj imię użytkownika w tabeli postów obok identyfikatora użytkownika. Pozwala to uniknąć połączenia podczas wyświetlania posta, kosztem okazjonalnej logiki synchronizacji.
Strategie skalowalności dla ERD 🚀
Wraz ze wzrostem liczby użytkowników schemat musi ewoluować, aby radzić sobie z rosnącym obciążeniem. Skalowanie pionowe ma limity; skalowanie poziome wymaga specyficznych rozważań dotyczących schematu.
Partycjonowanie
Partycjonowanie dzieli duże tabele na mniejsze, łatwiejsze do zarządzania fragmenty. W mediach społecznościowych dane często są partycjonowane według identyfikatora użytkownika lub daty.
- Partycjonowanie poziome: Podział użytkowników na różne shard-y na podstawie zakresów identyfikatorów.
- Partycjonowanie pionowe: Przenoszenie rzadko używanych kolumn do osobnej tabeli.
- Partycjonowanie według daty: Archiwizowanie starych postów w tabelach przechowywania chłodnego.
Strategie indeksowania
Indeksy są kluczowe dla wydajności zapytań, ale spowalniają zapisy. Wymagana jest strategiczna strategia indeksowania.
- Indeksy złożone: Pokrywanie typowych wzorców zapytań (np. ID użytkownika + znacznik czasu).
- Indeksy częściowe:Indeksowanie tylko odpowiednich wierszy (np. aktywne posty).
- Indeksy wyszukiwania: Używanie silników wyszukiwania pełnotekstowego do odkrywania treści.
Rozważania dotyczące prywatności i zgodności 🛡️
Nowoczesne modelowanie danych musi uwzględniać przepisy dotyczące prywatności, takie jak GDPR i CCPA. Projektowanie schematu wpływa na to, jak łatwo dane można zanonimizować lub usunąć.
Prawo do zapomnienia
Użytkownicy mogą żądać usunięcia swoich danych. ERD musi wspierać usuwanie kaskadowe lub miękkie bez naruszania integralności referencyjnej.
- Miękkie usuwanie: Dodawanie flagi „is_deleted” zamiast usuwania wierszy.
- Zanieczyszczone dane: Obsługa danych odnoszących się do usuniętego użytkownika.
- Anonimizacja: Zastępowanie identyfikatorów osobowych hashami.
Minimalizacja danych
Przechowuj tylko dane, które są naprawdę niezbędne. Nadmierne zbieranie metadanych zwiększa koszty przechowywania i ryzyko prywatności.
- Polityki przechowywania: Automatyczne usuwanie dzienników po ustalonym okresie.
- Czynne uprawnienia: Kontrole dostępu na poziomie wiersza.
- Szyfrowanie:Wrażliwe pola szyfrowane w stanie spoczynku.
Obsługa metadanych i dzienników 📉
Poza podstawowymi jednostkami systemy generują ogromne ilości metadanych. Obejmują one analizy, dzienniki błędów i śledzenie działań. Nie powinny one zanieczyszczać głównego schematu transakcyjnego.
Oddzielenie odpowiedzialności
Utrzymuj bazę danych transakcyjnych czystą. Przenieś intensywne logowanie i analizy do oddzielnych systemów.
- Strumienie zdarzeń: Używaj kolejek komunikatów do asynchronicznego logowania.
- Tabele analizy: Oddzielne tabele dla trendów historycznych.
- Dane szeregów czasowych: Specjalne przechowywanie metryk w czasie.
Iteracyjny proces projektowania 🔄
ERD rzadko są idealne w pierwszym szkicu. Wymagania mediów społecznościowych szybko się zmieniają wraz z wprowadzaniem nowych funkcji. Proces projektowania powinien być iteracyjny.
- Prototyp: Stwórz minimalny funkcjonalny schemat dla kluczowej funkcji.
- Test: Przeprowadź test obciążenia z rzeczywistymi objętościami danych.
- Refaktoryzacja: Dostosuj relacje na podstawie węzłów przepływu wydajności.
- Dokumentacja: Zachowuj aktualne schematy dla przyszłych programistów.
Typowe pułapki do uniknięcia ⚠️
Nawet doświadczeni architekci popełniają błędy podczas modelowania danych społecznościowych. Rozpoznawanie tych wzorców pomaga uniknąć przyszłych problemów.
- Nadmierna indeksacja:Zbyt wiele indeksów znacznie spowalnia operacje zapisu.
- Ignorowanie stref czasowych:Przechowywanie znaczników czasu bez kontekstu strefy czasowej prowadzi do zamieszania.
- Wartości zakodowane w kodzie: Unikaj wbudowywania logiki biznesowej w schemat (np. konkretne wartości statusu).
- Ignorowanie miękkich usuwań:Twarda usunięcie może naruszyć ograniczenia kluczy obcych w całym systemie.
- Bezgraniczny wzrost: Niearchiwizowanie starych danych prowadzi do nadmiernego rozrostu tabel.
Ostateczne rozważania dotyczące przyszłego rozwoju 🔮
Tworzenie platformy społecznościowej to długofalowe przedsięwzięcie. Model danych musi być wystarczająco elastyczny, aby dopasować się do zmian bez konieczności całkowitego przepisania. Skup się na przejrzystości, skalowalności i utrzymalności. Regularne przeglądy schematu pod kątem rzeczywistych wzorców użytkowania zapewniają, że system pozostaje stabilny w miarę skalowania.
- Wersjonowanie:Zaplanuj migracje schematu, które wspierają zgodność wsteczną.
- Monitorowanie:Śledź wydajność zapytań, aby wczesnie wykryć słabe punkty schematu.
- Opinia społeczności:Słuchaj, jak dane są faktycznie wykorzystywane przez zespół inżynierski.
Przestrzeganie tych strategii pozwala programistom stworzyć solidną podstawę dla aplikacji skoncentrowanych na użytkowniku. ERD to nie tylko schemat; to integralność strukturalna całej platformy. Czynny planowanie teraz zapobiega poważnym zadłużeniom technicznym w przyszłości.