











Projetar um esquema de banco de dados robusto para plataformas de redes sociais exige um profundo entendimento de como os usuários interagem, compartilham e consomem informações. Diferentemente dos sistemas transacionais tradicionais, as redes sociais envolvem relações complexas muitos para muitos, estruturas de dados recursivas e requisitos de escala massiva. O Diagrama Entidade-Relacionamento (ERD) serve como o projeto dessas interações, garantindo a integridade dos dados enquanto suporta crescimento acelerado. Este guia explora as estratégias críticas para modelar dados de redes sociais de forma eficaz.
Compreendendo o Desafio Central 🧩
Aplicações de redes sociais não são meros repositórios de conteúdo; são redes dinâmicas de relacionamentos. Uma publicação simples em um blog difere significativamente de um feed de redes sociais devido à camada de engajamento. Curtidas, compartilhamentos, comentários e seguidores criam uma teia de conexões que devem ser modeladas com precisão. Uma má modelagem leva a desempenho lento de consultas, inconsistência de dados e dificuldades na implementação de funcionalidades como feeds de notícias ou sugestões de amigos.
- Volume:Plataformas sociais geram milhões de eventos por segundo.
- Velocidade:Os dados chegam em fluxos em tempo real que devem ser processados imediatamente.
- Variedade:O conteúdo inclui texto, imagens, vídeos, metadados e dados de localização.
- Relacionamentos:O valor central reside nas conexões entre entidades.
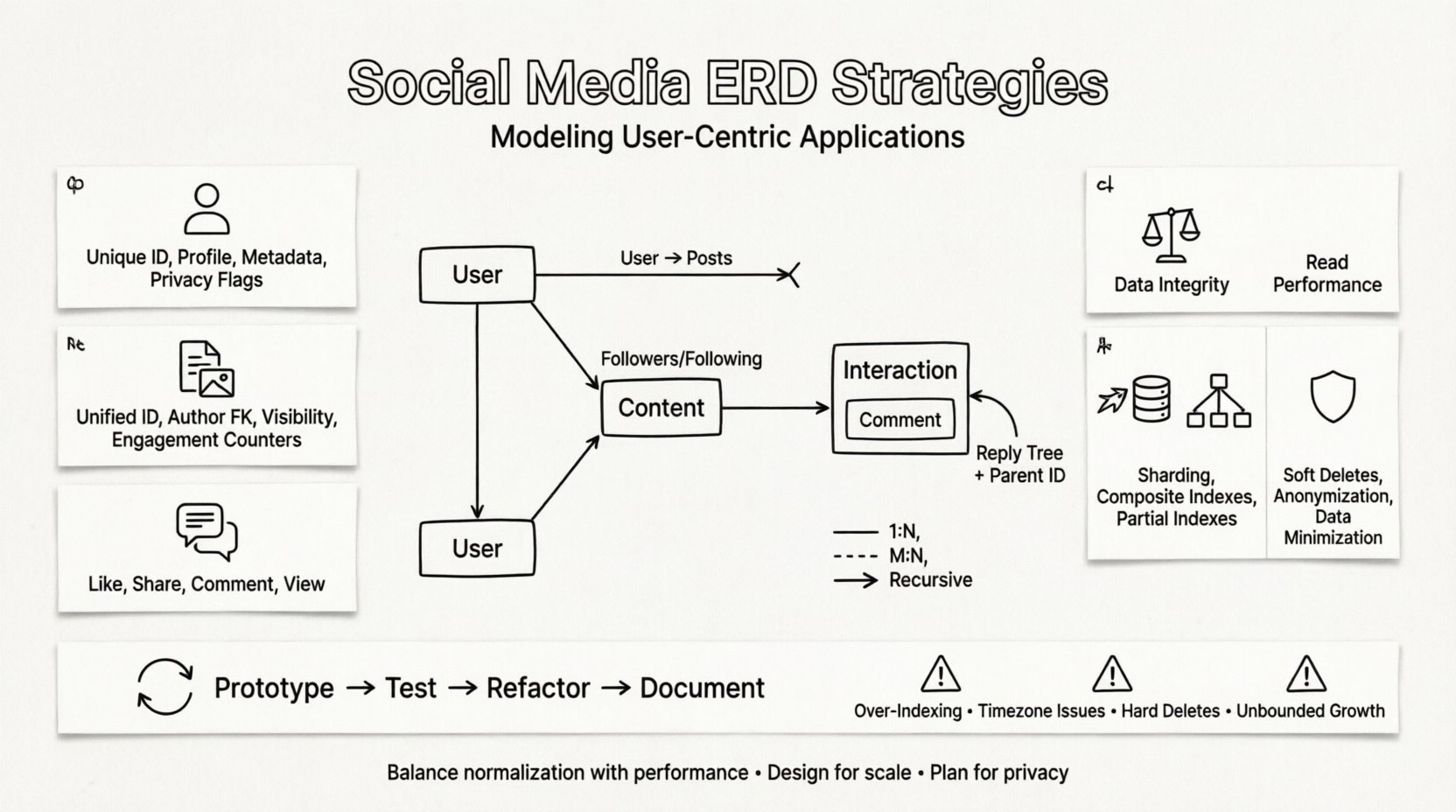
Ao construir um ERD, o objetivo principal é equilibrar a normalização com o desempenho. A sobre-normalização pode tornar as junções muito custosas para leituras de alta frequência. A sobre-desnormalização pode levar a redundância de dados e problemas de consistência. As seções a seguir detalham as entidades e relacionamentos específicos que definem este domínio.
Definindo Entidades Principais 🔑
Cada sistema de redes sociais gira em torno de algumas entidades fundamentais. Identificá-las corretamente é o primeiro passo para criar um esquema escalonável. Essas entidades representam os blocos de construção principais da aplicação.
1. A Entidade Usuário 👤
O usuário é o nó central na rede. Essa entidade armazena detalhes de autenticação, informações do perfil e preferências. Deve ser projetada para lidar com milhões de registros de forma eficiente.
- Identificador Único:É preferível usar uma chave artificial em vez de chaves naturais para desempenho e anonimato.
- Dados do Perfil: Nome, biografia, avatar e status de verificação.
- Metadados:Marcas de tempo para criação da conta, último acesso e exclusão.
- Bandeiras de Privacidade:Configurações que controlam a visibilidade dos dados para outros usuários.
2. A Entidade Conteúdo 📝
O conteúdo é o combustível das plataformas sociais. Ele abrange publicações, histórias, imagens, vídeos e comentários. Um esquema flexível é necessário porque tipos diferentes de conteúdo possuem atributos distintos.
- ID Unificado:Um ID genérico que faz referência a tabelas específicas de conteúdo.
- Referência do Autor: Uma chave estrangeira que faz referência à entidade User.
- Escopo de Visibilidade: Público, privado, apenas amigos ou grupos específicos.
- Contadores de Engajamento: Contagens armazenadas em cache para curtidas e comentários, a fim de reduzir a carga de consultas.
3. A Entidade de Interação 💬
As interações representam as ações que os usuários realizam sobre conteúdo ou outros usuários. São transações de alta volume que frequentemente determinam os requisitos de desempenho do sistema.
- Curtir: Um estado binário entre um usuário e conteúdo.
- Compartilhar: Uma referência ao conteúdo original com um novo contexto.
- Comentar: Uma relação hierárquica ou em fóruns com o conteúdo.
- Visualização: Frequentemente registrada separadamente devido ao alto volume e menor importância para integridade.
Modelagem de Relacionamentos 🕸️
A verdadeira complexidade das mídias sociais reside nas relações entre entidades. Técnicas padrão de modelagem relacional frequentemente têm dificuldade com a natureza recursiva dos grafos sociais. Uma atenção especial deve ser dada à forma como essas conexões são armazenadas.
Relacionamentos Um-Para-Muitos
São os mais comuns e diretos. Por exemplo, um usuário pode ter muitos posts, mas um post pertence a apenas um usuário. Isso é modelado usando uma chave estrangeira na tabela filha.
- Exemplo: ID do Usuário na tabela Posts.
- Benefício: Recuperação rápida de todos os posts para um perfil específico.
- Restrição: Garante a integridade referencial automaticamente.
Relacionamentos Muitos-Para-Muitos
Seguidores e seguidos são o exemplo clássico. Um usuário segue muitos outros, e um usuário é seguido por muitos outros. Isso exige uma tabela de junção para resolver a relação.
- Tabela de Junção: Contém o ID do Usuário A e o ID do Usuário B.
- Horários (timestamps): Quando a ação seguinte ocorreu.
- Status: Pendente, aceito ou bloqueado.
- Desempenho: O indexamento é crítico em ambos os chaves estrangeiras.
Relacionamentos Recursivos
Algumas relações envolvem o mesmo tipo de entidade. Um comentário pode ter respostas a respostas. Isso cria uma estrutura em árvore que é difícil de consultar em modelos relacionais padrão.
- ID do Pai: Uma chave estrangeira que aponta para o ID do Comentário.
- Profundidade: Limitar a profundidade da recursão evita loops infinitos.
- Caminhos Materializados: Armazenando o caminho da árvore para uma navegação mais rápida.
| Tipo de Relação | Exemplo | Estratégia de Implementação | Impacto no Desempenho |
|---|---|---|---|
| Um para Muitos | Usuário – Posts | Chave Estrangeira no Filho | Baixo (Indexação Padrão) |
| Muitos para Muitos | Usuário – Segue | Tabela de Junção | Médio (Custo de Junção) |
| Recursivo | Comentário – Resposta | FK Auto-Referenciada | Alto (Consultas Complexas) |
| Associativo | Tag – Usuário | Chaves Compostas | Médio (Pesquisa Intensa) |
Normalização vs. Denormalização ⚖️
Em sistemas de mídia social, o desempenho de leitura muitas vezes supera o desempenho de escrita. Os usuários esperam que as feeds carreguem instantaneamente, mesmo quando envolvem milhões de registros. Isso exige um equilíbrio cuidadoso entre normalização e denormalização.
O Caso pela Normalização
A normalização garante a integridade dos dados e reduz a redundância. É essencial para dados principais que não mudam com frequência.
- Consistência dos Dados:As atualizações ocorrem em um único local.
- Eficiência de Armazenamento: Menor armazenamento de dados duplicados.
- Manutenibilidade: Mais fácil de aplicar regras de negócios.
O Caso pela Denormalização
A denormalização envolve a duplicação de dados para reduzir o número de junções necessárias durante leituras. Isso é comum em feeds sociais.
- Velocidade de Leitura: Menos junções significam execução de consultas mais rápida.
- Cache: Contagens agregadas (por exemplo, total de curtidas) armazenadas diretamente.
- Carga de Escrita: As atualizações devem ser propagadas para todas as cópias.
Abordagem Híbrida
Uma estratégia prática envolve normalizar o esquema principal enquanto denormaliza métricas frequentemente lidas. Por exemplo, armazene o nome do usuário na tabela de postagens junto com o ID do usuário. Isso evita uma junção ao exibir o post, custando lógica de sincronização ocacional.
Estratégias de Escalabilidade para Modelos ER 🚀
À medida que a base de usuários cresce, o esquema deve evoluir para lidar com a carga aumentada. A escalabilidade vertical tem limites; a escalabilidade horizontal exige considerações específicas no esquema.
Particionamento
O particionamento divide tabelas grandes em pedaços menores e gerenciáveis. Em mídia social, os dados são frequentemente particionados por ID de usuário ou data.
- Particionamento Horizontal: Dividir usuários entre diferentes shards com base em faixas de ID.
- Particionamento Vertical: Movendo colunas pouco acessadas para uma tabela separada.
- Particionamento por data:Arquivando postagens antigas em tabelas de armazenamento frio.
Estratégias de indexação
Índices são vitais para o desempenho das consultas, mas retardam as gravações. É necessária uma abordagem estratégica para a indexação.
- Índices compostos:Cobrindo padrões comuns de consulta (por exemplo, ID do usuário + horário).
- Índices parciais:Indexando apenas as linhas relevantes (por exemplo, postagens ativas).
- Índices de busca:Usando motores de busca de texto completo para descoberta de conteúdo.
Considerações sobre privacidade e conformidade 🛡️
O modelo de dados moderno deve levar em conta regulamentações de privacidade como o GDPR e o CCPA. O design do esquema afeta a facilidade com que os dados podem ser anonimizados ou excluídos.
Direito ao esquecimento
Os usuários podem solicitar a exclusão de seus dados. O diagrama ER deve suportar exclusões em cascata ou exclusões suaves sem comprometer a integridade referencial.
- Exclusões suaves:Adicionando uma flag “is_deleted” em vez de remover as linhas.
- Dados órfãos:Tratamento de dados que referenciam um usuário excluído.
- Anonimização:Substituindo identificadores pessoais por hashes.
Minimização de dados
Armazene apenas dados estritamente necessários. A coleta excessiva de metadados aumenta os custos de armazenamento e os riscos de privacidade.
- Políticas de retenção:Exclusão automática de logs após um período definido.
- Permissões granulares:Controles de acesso ao nível de linha.
- Criptografia:Campos sensíveis criptografados em repouso.
Gerenciamento de metadados e logs 📉
Além das entidades principais, os sistemas geram grandes quantidades de metadados. Isso inclui análises, registros de erros e rastros de auditoria. Esses dados não devem poluir o esquema transacional principal.
Separação de Responsabilidades
Mantenha o banco de dados transacional limpo. Encaminhe o registro pesado e as análises para sistemas separados.
- Fluxos de Eventos:Use filas de mensagens para registro assíncrono.
- Tabelas de Análise:Tabelas separadas para tendências históricas.
- Dados em Séries Temporais:Armazenamento específico para métricas ao longo do tempo.
Processo Iterativo de Design 🔄
Diagramas ER raramente são perfeitos na primeira versão. Os requisitos de redes sociais evoluem rapidamente à medida que novos recursos são introduzidos. O processo de design deve ser iterativo.
- Protótipo:Crie um esquema mínimo viável para o recurso principal.
- Teste:Teste de carga com volumes de dados realistas.
- Refatorar:Ajuste as relações com base nos gargalos de desempenho.
- Documente:Mantenha diagramas atualizados para desenvolvedores futuros.
Armadilhas Comuns para Evitar ⚠️
Mesmo arquitetos experientes cometem erros ao modelar dados sociais. Reconhecer esses padrões ajuda a prevenir problemas futuros.
- Sobrecarga de Índices:Muitos índices retardam significativamente as operações de escrita.
- Ignorar Fuso Horário:Armazenar timestamps sem contexto de fuso horário leva à confusão.
- Valores Codificados:Evite incorporar lógica de negócios no esquema (por exemplo, valores específicos de status).
- Ignorar Exclusão Suave:Exclusões rígidas podem quebrar restrições de chave estrangeira em toda a rede.
- Crescimento Ilimitado: Falhar em arquivar dados antigos leva ao crescimento excessivo das tabelas.
Considerações Finais para o Crescimento Futuro 🔮
Construir uma plataforma de mídia social é uma empreitada de longo prazo. O modelo de dados deve ser flexível o suficiente para acomodar mudanças sem exigir uma reescrita completa. Foque na clareza, escalabilidade e manutenibilidade. Revisões regulares do esquema com base nos padrões reais de uso garantem que o sistema permaneça robusto à medida que escala.
- Versionamento: Planeje migrações de esquema que suportem compatibilidade reversa.
- Monitoramento: Monitore o desempenho das consultas para identificar fraquezas no esquema cedo.
- Feedback da Comunidade: Ouça como os dados são realmente utilizados pela equipe de engenharia.
Ao seguir estas estratégias, os desenvolvedores podem criar uma base sólida para aplicações centradas no usuário. O ERD não é apenas um diagrama; é a integridade estrutural de toda a plataforma. Um planejamento cuidadoso agora evita uma dívida técnica significativa no futuro.