











為社交媒體平台設計穩健的資料庫結構,需要深入理解使用者如何互動、分享與消費資訊。與傳統交易系統不同,社交網絡涉及複雜的多對多關係、遞迴資料結構以及巨大的規模需求。實體-關係圖(ERD)作為這些互動的藍圖,確保資料完整性,同時支援快速成長。本指南探討有效建模社交媒體資料的關鍵策略。
理解核心挑戰 🧩
社交媒體應用程式不僅僅是內容的儲存庫;它們是動態的關係網絡。由於互動層的存在,一篇簡單的部落格文章與社交媒體動態訊息有著顯著差異。按讚、分享、留言與追蹤創造出必須精確建模的連結網絡。不良的建模會導致查詢效能低下、資料不一致,並難以實現新聞動態或好友推薦等功能。
- 資料量:社交平台每秒產生數百萬筆事件。
- 速度:資料以即時串流形式到達,必須立即處理。
- 多樣性:內容包含文字、圖片、影片、元資料與位置資料。
- 關係:核心價值在於實體之間的連結。
在建構ERD時,主要目標是平衡正規化與效能。過度正規化會使高頻率讀取時的連接操作成本過高。過度反正規化則可能導致資料重複與一致性問題。以下各節將詳細說明定義此領域的特定實體與關係。
定義核心實體 🔑
每個社交媒體系統都圍繞著幾個基本實體運作。正確識別這些實體是建立可擴展結構的第一步。這些實體代表了應用程式的核心構建模組。
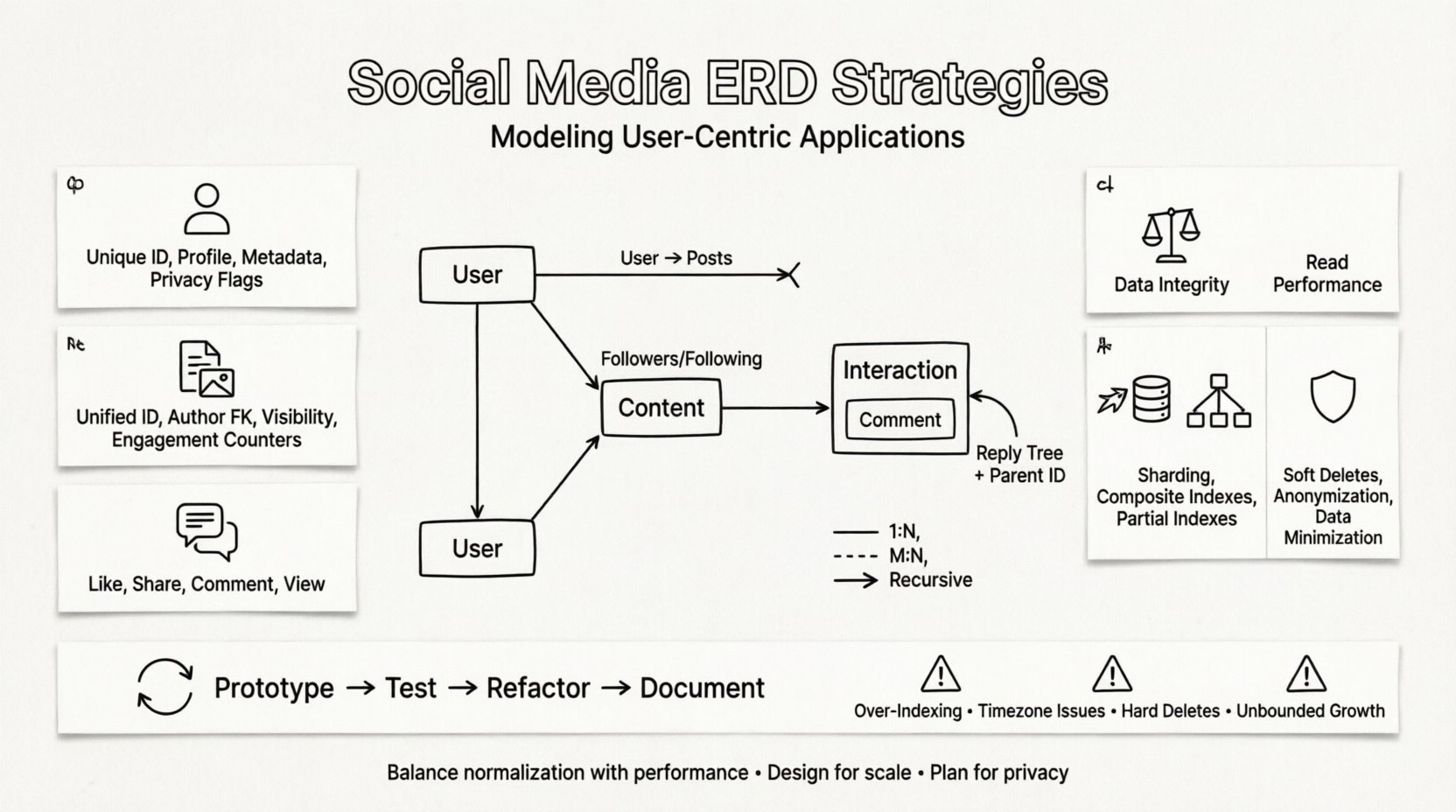
1. 使用者實體 👤
使用者是網絡中的核心節點。此實體儲存驗證資訊、個人檔案資料與偏好設定。它必須設計得能有效處理數百萬筆記錄。
- 唯一識別碼:為提升效能與匿名性,建議使用代理鍵而非自然鍵。
- 個人檔案資料:姓名、個人簡介、頭像與驗證狀態。
- 元資料:帳戶建立、最後登入與刪除的時間戳記。
- 隱私旗標: 控制資料對其他使用者可見性的設定。
2. 內容實體 📝
內容是社交平台的燃料。它涵蓋貼文、故事、圖片、影片與留言。由於不同類型的內容具有不同的屬性,因此需要具備彈性的資料結構。
- 統一識別碼: 連結至特定內容資料表的通用識別碼。
- 作者參考: 一個連結至使用者實體的外鍵。
- 可見範圍: 公開、私人、僅限朋友,或特定群組。
- 互動計數器: 用於減少查詢負載的讚和評論的快取計數。
3. 互動實體 💬
互動代表使用者對內容或其他使用者所採取的動作。這些是高頻率的交易,通常決定了系統的效能需求。
- 讚: 使用者與內容之間的二元狀態。
- 分享: 對原始內容的引用,並加上新的語境。
- 評論: 與內容之間的層次或串列式關係。
- 檢視: 由於數量龐大且對完整性的重要性較低,通常會獨立記錄。
關係建模 🕸️
社群媒體真正的複雜性在於實體之間的關係。標準的關聯式建模技術經常難以應付社交圖形的遞迴性質。必須特別注意這些連結是如何儲存的。
一對多關係
這是最常見且最直接的。例如,一個使用者可以有許多文章,但一篇文章僅屬於一個使用者。這透過在子表中使用外鍵來建模。
- 範例: 文章表中的使用者ID。
- 優點: 可快速取得特定個人檔案的所有文章。
- 限制條件: 自動強制參考完整性。
多對多關係
追蹤者與追蹤中是經典範例。一個使用者追蹤許多其他人,而一個使用者也被許多其他人追蹤。這需要一個交會表來解決此關係。
- 交會表: 包含使用者ID A與使用者ID B。
- 時間戳記: 當發生追蹤動作時。
- 狀態: 等待中、已接受或已被阻止。
- 效能: 在兩個外鍵上進行索引至關重要。
遞迴關係
某些關係涉及相同的實體類型。一則評論可以有對評論的回覆,而這些回覆又可以再有回覆。這會形成一個樹狀結構,難以在標準的關聯式模型中查詢。
- 父項 ID: 指向評論 ID 的外鍵。
- 深度: 限制遞迴深度可防止無限循環。
- 物化路徑: 儲存樹的路徑以加快遍歷速度。
| 關係類型 | 範例 | 實作策略 | 效能影響 |
|---|---|---|---|
| 一對多 | 使用者 – 文章 | 子項中的外鍵 | 低(標準索引) |
| 多對多 | 使用者 – 追蹤 | 交集表 | 中等(JOIN 過載) |
| 遞迴 | 評論 – 回覆 | 自我引用的外鍵 | 高(複雜查詢) |
| 關聯式 | 標籤 – 使用者 | 複合金鑰 | 中等(查詢密集) |
正規化 vs. 非正規化 ⚖️
在社交媒體系統中,讀取效能通常優於寫入效能。使用者期望動態訊息能立即載入,即使涉及數百萬筆記錄也是如此。這需要在正規化與非正規化之間取得精細的平衡。
正規化的理由
正規化確保資料完整性並減少冗餘。對於不常變動的核心資料而言,這至關重要。
- 資料一致性:更新只發生在一個地方。
- 儲存效率:減少重複資料儲存。
- 可維護性:更容易強制執行業務規則。
非正規化的理由
非正規化涉及複製資料,以減少讀取時所需的連接次數。這在社交動態訊息中很常見。
- 讀取速度:較少的連接代表更快的查詢執行。
- 快取:聚合計數(例如總點讚數)直接儲存。
- 寫入負載:更新必須傳播到所有副本。
混合方法
一種實用策略是在保持核心資料結構正規化的同時,對經常讀取的指標進行非正規化。例如,將使用者名稱與使用者ID一同儲存在貼文表格中。這樣在顯示貼文時可避免連接操作,但需付出偶爾同步邏輯的代價。
ERD 的可擴展性策略 🚀
隨著使用者群體擴大,資料結構必須演進以應對增加的負載。垂直擴展有其限制;水平擴展則需要特定的資料結構考量。
分割
分割將大型表格拆分成較小且易於管理的片段。在社交媒體中,資料通常按使用者ID或日期進行分割。
- 水平分割:根據ID範圍,將使用者分散到不同的分片中。
- 垂直分割: 將很少存取的欄位移至獨立的資料表。
- 按日期分割: 將舊的貼文歸檔至冷資料儲存資料表。
索引策略
索引對於查詢效能至關重要,但會降低寫入速度。必須採取策略性的方式來設計索引。
- 複合索引: 覆蓋常見的查詢模式(例如:使用者ID + 時間戳記)。
- 部分索引: 僅對相關資料列建立索引(例如:活躍的貼文)。
- 搜尋索引: 使用全文搜尋引擎進行內容探索。
隱私與合規考量 🛡️
現代資料模型必須考慮隱私法規,如GDPR與CCPA。資料結構設計會影響資料匿名化或刪除的難易程度。
被遺忘的權利
使用者可要求刪除其資料。ERD必須支援級聯刪除或軟刪除,而不破壞參考完整性。
- 軟刪除: 加入「is_deleted」旗標,而非直接移除資料列。
- 孤立資料: 處理指向已刪除使用者的資料。
- 匿名化: 以雜湊值取代個人識別資訊。
資料最小化
僅儲存絕對必要的資料。過度收集元資料會增加儲存成本與隱私風險。
- 保留政策: 在設定期間後自動刪除記錄。
- 細粒度權限: 資料列層級的存取控制。
- 加密: 敏感欄位於靜態時進行加密。
處理元資料與記錄 📉
除了核心實體之外,系統會產生大量元資料。這包括分析資料、錯誤日誌和審計追蹤。這些資料不應混雜在主要的交易模式中。
關注點分離
保持交易資料庫的乾淨。將繁重的日誌記錄和分析工作移至獨立的系統。
- 事件串流: 使用訊息佇列進行非同步日誌記錄。
- 分析資料表: 為歷史趨勢設立獨立的資料表。
- 時間序列資料: 對時間上的指標設立專用儲存空間。
迭代式設計流程 🔄
ERD 在第一稿時很少是完美的。隨著新功能的推出,社群媒體的需求會迅速演變。設計流程應具備迭代性。
- 原型: 為核心功能建立一個最小可行的資料結構。
- 測試: 使用實際的資料量進行負載測試。
- 重構: 根據效能瓶頸調整關係。
- 文件化: 維護最新的圖表,以供未來開發者使用。
應避免的常見陷阱 ⚠️
即使經驗豐富的架構師在建模社交資料時也會犯錯。識別這些模式有助於避免未來的問題。
- 過度索引: 索引過多會顯著降低寫入操作的效率。
- 忽略時區: 在沒有時區背景的情況下儲存時間戳記會導致混淆。
- 硬編碼值: 避免在資料結構中嵌入業務邏輯(例如特定的狀態值)。
- 忽略軟刪除: 硬刪除可能導致整個網絡中的外鍵約束被破壞。
- 無限增長: 未能存檔舊資料會導致資料表膨脹。
未來成長的最終考量 🔮
建構社交媒體平台是一項長期的任務。資料模型必須具有足夠的彈性,以應對變更而不需完全重寫。專注於清晰性、可擴展性和可維護性。定期根據實際使用模式檢視資料結構,確保系統在擴展時仍保持穩健。
- 版本控制: 計畫支援向後相容的資料結構遷移。
- 監控: 追蹤查詢效能,以早期識別資料結構的弱點。
- 社群反饋: 聆聽工程團隊實際如何使用資料。
透過遵循這些策略,開發人員可以為以使用者為中心的應用建立穩固的基礎。ERD 不僅僅是一張圖表;它是整個平台的結構完整性。現在的細心規劃可避免未來產生重大技術負債。