











In the intricate architecture of database design, few concepts challenge engineers quite like the self-referencing entity. Also known as a recursive relationship, this pattern allows a table to link to itself, enabling the modeling of hierarchies and complex structures within a flat schema. Understanding how to implement this correctly is crucial for maintaining data integrity and query performance.
When designing an Entity Relationship Diagram (ERD), most relationships connect two distinct entities. However, real-world data often demands that a single entity relate back to its own kind. A manager manages employees, a category contains subcategories, and a product can be part of a kit. These scenarios require a recursive relationship.
This guide explores the mechanics, design patterns, and best practices for handling self-referencing entities. We will examine how to structure these relationships without relying on specific software tools, focusing on universal database principles.
🧐 What is a Self-Referencing Entity?
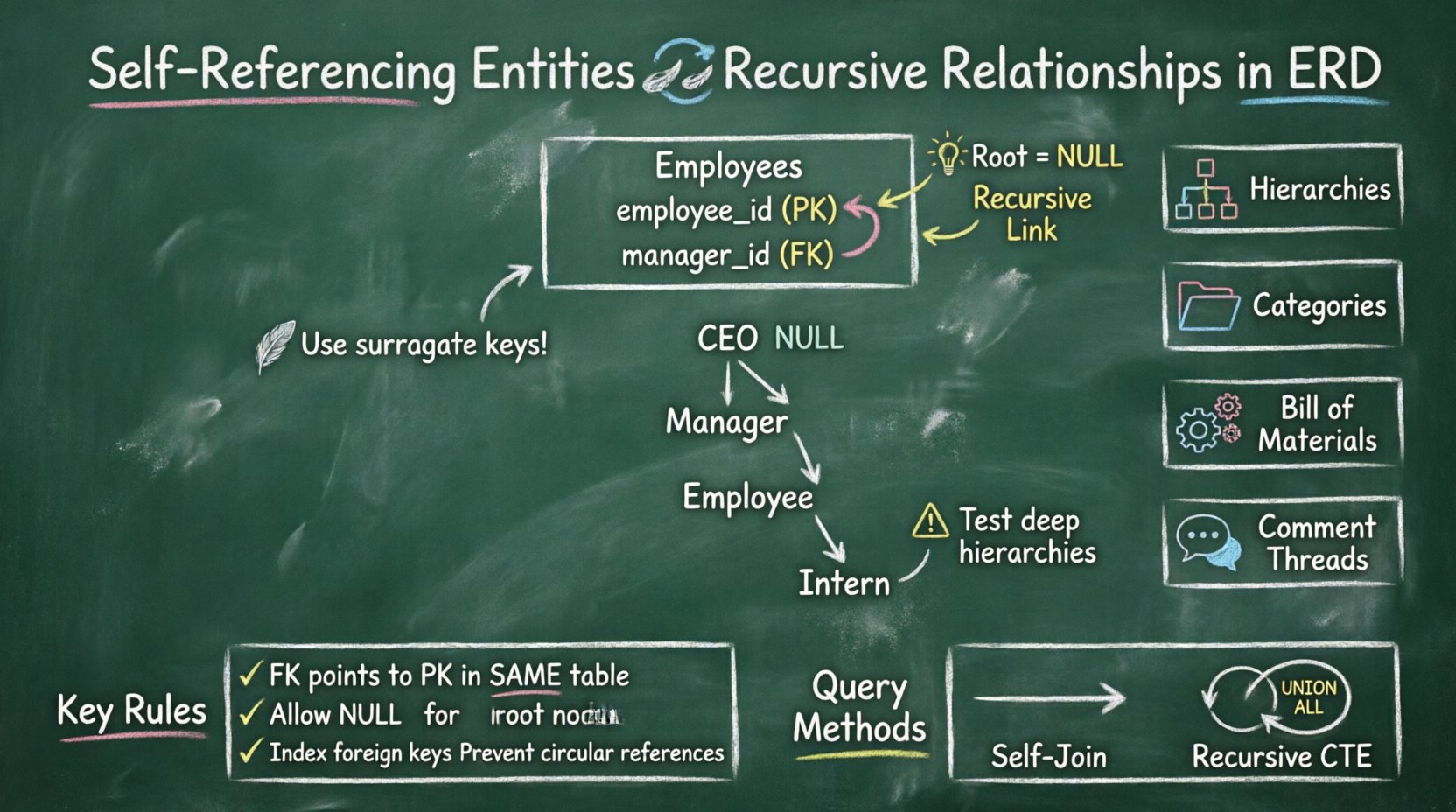
A self-referencing entity occurs when a foreign key in a table points to the primary key of the same table. This creates a loop where data rows within a single table can reference other rows within that same table. It is a fundamental technique for modeling hierarchical data structures.
Key Characteristics:
- Single Table: The relationship exists entirely within one table structure.
- Parent-Child Link: One row acts as the parent, while another acts as the child.
- Null Handling: The root of the hierarchy typically has a null value in the foreign key column.
- Circular Logic: Care must be taken to prevent infinite loops during data retrieval.
🏗️ Core Components of Recursive Relationships
To implement this relationship effectively, specific database components must be aligned. The schema design relies heavily on the interaction between primary keys and foreign keys.
🔑 The Primary Key
Every row in the table must have a unique identifier. This is the anchor point. When a row references another row, it does so by storing the unique identifier of the parent row.
- It must be stable. Changing a primary key is a complex operation.
- It should be indexed for fast lookup performance.
- Commonly, this is an auto-incrementing integer or a UUID.
🔗 The Foreign Key
The foreign key column resides in the same table as the primary key. It holds the value of the parent row’s primary key. This column defines the direction of the relationship.
- Nullable: In a hierarchy, the top-level item (the root) does not have a parent. Therefore, this column must allow null values.
- Constraint: A foreign key constraint ensures that the value stored matches an existing primary key in the same table.
- Indexing: While not always mandatory, indexing the foreign key column significantly speeds up queries that traverse the hierarchy.
📐 Visualizing in an Entity Relationship Diagram
When drawing an ERD to represent a self-referencing entity, the notation can be confusing at first glance. Standard ERD tools use specific lines to denote the connection.
Visual Notation Rules:
- The entity box is drawn once.
- A relationship line connects the primary key to the foreign key within the same box.
- The line often loops back to the entity, creating a visual circle.
- Cardinality markers (1:1, 1:M) are placed on the line to indicate how many children a parent can have.
Example: Organizational Structure
| Concept | Description | ERD Notation |
|---|---|---|
| Employee | The entity being modeled | Box labeled "Employee" |
| Manager | The role referencing the same table | Line from Manager ID to Employee ID |
| Reporting Line | The recursive relationship | Looping arrow |
| Root Node | CEO or top-level boss | Null value in Manager ID |
🌳 Common Use Cases for Recursive Data
Recursive relationships are not theoretical; they solve tangible problems in data modeling. Here are the most frequent scenarios where this pattern is applied.
1️⃣ Organizational Hierarchies
Every company has a structure. Employees report to managers, who report to directors, who report to VPs. This chain is a classic tree structure.
- Data Model: One table named "Employees".
- Columns:
employee_id,name,manager_id. - Logic: The
manager_idcolumn referencesemployee_id. - Benefit: Adding a new hire only requires inserting one row. No need to create a new table for each department.
2️⃣ Category Trees
E-commerce platforms often organize products into nested categories. Electronics > Computers > Laptops.
- Data Model: One table named "Categories".
- Columns:
category_id,name,parent_id. - Logic: A category can have a parent, or it can be a root category (parent_id is null).
- Benefit: Flexibility to add as many subcategories as needed without altering the schema.
3️⃣ Bill of Materials (BOM)
Manufacturing often requires complex parts lists. A car is made of engines, which are made of pistons. Sometimes a piston is part of a different engine type.
- Data Model: One table named "Parts".
- Columns:
part_id,description,assembly_id. - Logic: A part can be an assembly itself, containing other parts.
- Benefit: Allows for multi-level manufacturing structures.
4️⃣ Comment Threads
Forums and blogs allow users to reply to comments. A comment can have a parent comment it is replying to, or it can be a standalone comment.
- Data Model: One table named "Comments".
- Columns:
comment_id,user_id,content,parent_comment_id. - Logic: A reply links back to the original comment ID.
- Benefit: Supports infinite nesting of discussions.
⚙️ Implementation Considerations
Designing the schema is only the first step. Ensuring the data behaves correctly under various conditions requires careful planning.
🛑 Preventing Circular References
A critical risk in recursive relationships is creating a cycle. For example, Employee A manages Employee B, and Employee B manages Employee A. This creates an infinite loop.
- Application Logic: When inserting or updating data, the application should verify the hierarchy depth to ensure no cycles are formed.
- Database Constraints: While standard SQL constraints cannot easily prevent cycles (as they check the current state, not the resulting state), triggers can be used in some systems to validate the path before writing.
- Root Identification: Ensure every valid tree has exactly one root node (where the foreign key is null).
📉 Handling Null Values
The root of the hierarchy is the starting point. In a standard recursive relationship, the root row has a null value in the foreign key column.
- Querying: To find all root nodes, query for rows where the foreign key is NULL.
- Default Values: Do not set a default value for the foreign key if it implies a parent. A default value of 0 or -1 can be misleading and cause data integrity issues.
- Integrity: Ensure the database engine allows NULLs for the foreign key column. A NOT NULL constraint will break the hierarchy model.
📈 Performance and Indexing
As the data grows, querying recursive structures can become slow. A simple query to find all descendants of a specific node can require many joins or recursive queries.
Optimization Strategies:
- Index Foreign Keys: Create an index on the column that holds the parent reference. This speeds up finding children.
- Materialized Paths: Some systems store the full path of the hierarchy in a separate column (e.g., "/1/5/12/20"). This allows for faster string-based filtering, though it requires updates on every insert.
- Nested Sets: An alternative algorithm that uses left and right numbers to represent depth. This is faster for retrieval but slower for insertion.
- Query Depth: Limit the depth of recursion in your queries. Infinite loops can crash the database engine if not capped.
🔍 Querying Recursive Data
Retrieving hierarchical data is more complex than retrieving flat data. Standard JOINs work for one level, but multiple levels require specialized logic.
🔄 Self-Joins
The most common method involves joining the table to itself. You alias the table once as the parent and once as the child.
- One Level: Join the table to itself once to get the immediate parent.
- Multiple Levels: Requires multiple joins, which becomes unwieldy quickly.
- Drawback: The number of joins required equals the depth of the hierarchy.
🔁 Recursive Common Table Expressions (CTEs)
Modern database engines support Recursive CTEs. This allows a query to run a UNION ALL against itself until no more rows are found.
- Anchor Member: The starting point of the recursion (usually the root node).
- Recursive Member: The part of the query that joins the result back to the table to find the next level.
- Termination: The query stops when no more matching rows are found.
- Benefit: Handles any depth of hierarchy without knowing it in advance.
🛡️ Data Integrity and Constraints
Maintaining the integrity of a self-referencing table is vital. If a parent is deleted, what happens to the children?
🗑️ Delete Cascading
When a parent row is removed, the database must decide how to handle child rows.
- RESTRICT: Prevents the deletion of the parent if children exist. This preserves data but might block necessary cleanup.
- CASCADE: Deletes all child rows when the parent is deleted. This is dangerous in deep hierarchies as it can wipe large portions of data accidentally.
- SET NULL: Sets the foreign key of the children to NULL, making them new root nodes. This is often the safest option for preserving data structure.
- SET DEFAULT: Sets the foreign key to a default value (e.g., a specific orphaned category).
🔒 Update Constraints
Changing the primary key of a parent row is risky. If you change the ID of a manager, you must update that ID in every employee record that references them.
- Application Layer: Handle the update transactionally to ensure all references are updated together.
- Database Triggers: Can automate the propagation of ID changes, though this adds complexity.
- Best Practice: Avoid updating primary keys in recursive structures whenever possible. Use surrogate keys (auto-increment integers) rather than natural keys (like employee codes).
🚧 Troubleshooting Common Issues
Even with careful design, issues can arise during development and maintenance.
❓ How do I find the depth of a tree?
To determine the level of a specific row, you must traverse up from the row to the root. Count the number of hops.
- Query Approach: Use a recursive query that counts rows as it moves up.
- Application Approach: Store the depth in a column during insertion. This saves query time but requires maintenance.
❓ How do I handle orphaned nodes?
Orphaned nodes are rows where the foreign key points to a non-existent parent. This usually happens due to bugs or manual data entry errors.
- Validation: Run periodic integrity checks to find rows where the foreign key does not match any primary key.
- Recovery: Decide a policy: move them to a root category, delete them, or flag them for review.
❓ Performance degradation over time
As the tree grows, queries that scan the whole tree become slower.
- Caching: Cache frequently accessed hierarchy structures in application memory.
- Archiving: Move historical or inactive parts of the hierarchy to archive tables.
- Partitioning: If the data is massive, partition the table by root category.
📝 Summary of Best Practices
To ensure a robust implementation of self-referencing entities, adhere to these guidelines.
- Use Surrogate Keys: Prefer auto-incrementing integers over business keys for the primary key.
- Allow NULLs: Ensure the foreign key column allows null values for root nodes.
- Index Foreign Keys: Always index the column that holds the parent reference.
- Validate Cycles: Implement checks to prevent circular references (A -> B -> A).
- Limit Recursion: Cap the depth of recursion in queries to prevent stack overflows.
- Document the Schema: Clearly mark which columns are self-referencing in your ERD documentation.
- Plan for Deletion: Define clear rules for cascading deletes or setting nulls on parent removal.
- Test Deep Hierarchies: Test your queries with at least 10 levels of depth to ensure performance holds.
🔮 Future Considerations
Database technology continues to evolve. While the concept of a self-referencing entity remains constant, the tools to manage it are improving.
- Graph Databases: Some modern systems treat relationships as first-class citizens. They handle recursive paths natively without the SQL complexity.
- JSON Support: Newer database engines allow storing hierarchical data in JSON columns, which can simplify schema design for deeply nested structures.
- ORM Improvements: Object-Relational Mappers are getting better at handling recursive relationships automatically, reducing boilerplate code.
Despite these advancements, the core logic of the recursive relationship remains the same. Understanding the underlying mechanics of primary keys, foreign keys, and table relationships is essential for any technical professional working with data structures.
By following these principles, you can build systems that are flexible enough to handle complex hierarchies while remaining performant and maintainable. The self-referencing entity is a powerful tool in your data modeling arsenal, provided it is used with precision and care.