










Designing a robust data model requires more than just mapping entities and relationships. It demands an understanding of how data evolves over time. In traditional Entity Relationship Diagrams (ERDs), we often capture the state of a record at a single point in time. We store the current value of a salary, the active status of a user, or the latest price of a product. However, business intelligence and regulatory compliance often require knowing not just what is true now, but what was true in the past.
This is where temporal data modeling enters the conversation. It transforms a static schema into a dynamic history tracker. By integrating time dimensions directly into your ERD, you ensure that every change is documented, auditable, and queryable without losing the context of when those changes occurred. This guide explores the structural techniques required to build time-aware database systems.
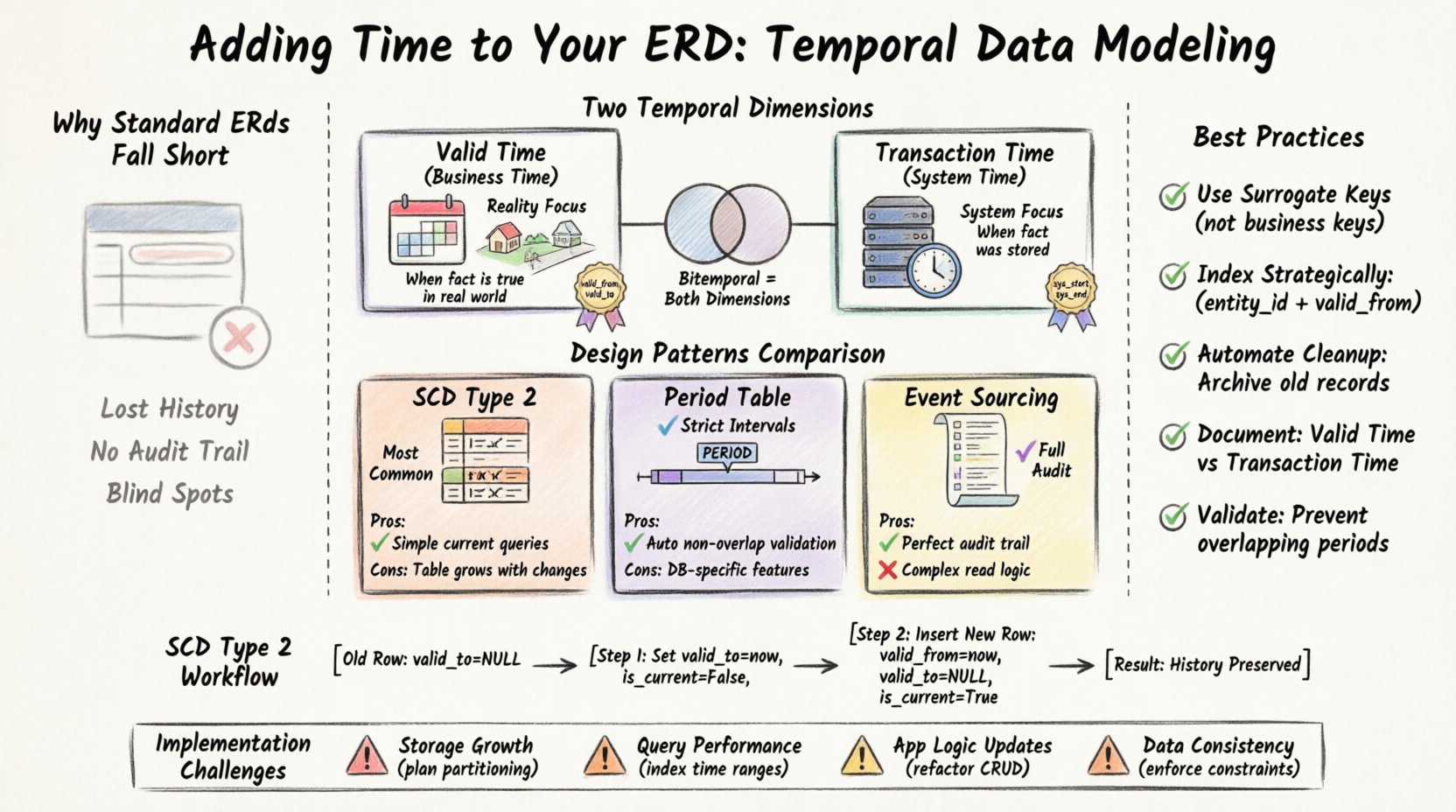
Why Standard ERDs Fall Short for History 📉
A conventional ERD focuses on the present state. When a record is updated, the old value is typically overwritten. While this works for simple operational systems, it creates significant blind spots for analytical needs. Consider a scenario where you need to reconstruct the billing history for a customer over the last five years. A standard table might only show the current address or current subscription tier.
Without temporal modeling, you face several challenges:
- Loss of Context: You cannot determine when a price change actually took effect in the real world versus when it was entered into the system.
- Audit Complexity: Building a separate audit log table requires manual trigger implementation and adds overhead to every write operation.
- Query Difficulty: Reconstructing a timeline often requires complex joins or self-joins that are difficult to maintain and optimize.
- Data Integrity: Without explicit time constraints, it is easy to accidentally overwrite historical data during bulk updates.
By embedding time directly into the schema, you shift the responsibility of history tracking from application logic to the data structure itself.
Understanding Temporal Dimensions ⏳
To model time effectively, you must distinguish between the different ways time exists in a database. There are two primary dimensions to consider: Valid Time and Transaction Time. Understanding the difference is crucial for selecting the right modeling technique.
1. Valid Time (Business Time)
Valid time represents the period during which a fact is true in the real world. This is independent of the database system. For example, if an employee’s department changed from Sales to Engineering on January 1st, the Valid Time for the Engineering assignment begins on that date, regardless of when the HR manager typed it into the system.
- Focus: Reality.
- Use Case: Historical reporting, compliance auditing, reconstructing past states.
- Attributes: Typically implemented with
valid_fromandvalid_totimestamps.
2. Transaction Time (System Time)
Transaction time tracks when a fact was stored in the database. It is managed entirely by the system. If a user edits a record today, the Transaction Time records that specific moment. If the record is deleted, the Transaction Time ensures the system knows when it ceased to be visible in the active set.
- Focus: System operations.
- Use Case: Debugging data issues, understanding system state at a specific moment, rollback capabilities.
- Attributes: Usually managed automatically by the database engine as
sys_startandsys_end.
3. Bitemporal Data
When you need both Valid Time and Transaction Time, you are building a bitemporal table. This is the most comprehensive form of temporal modeling. It allows you to ask questions like, “What did the system believe to be true on March 1st, 2023, regarding the actual state of the world on January 1st, 2023?”
Design Patterns for Time-Aware Schemas 🛠️
There are several architectural patterns for implementing temporal data within an ERD. The choice depends on your query patterns and storage constraints.
The Slowly Changing Dimension (SCD) Type 2 Pattern
This is the most common technique for historical tracking in data warehousing. Instead of updating a row, you insert a new row with a new version identifier. The old row is marked as inactive.
- Key Addition:
surrogate_key(to link to the new version) andis_activeflag. - Benefit: Simple queries to find the current record using a filter.
- Drawback: The table grows linearly with changes. Deleting a row requires updating all previous versions or flagging them.
The Period Table Pattern
In this approach, time is stored as a period type rather than two separate columns. This is often supported natively by modern database engines. It enforces that periods do not overlap.
- Key Addition: A
PERIODdata type constraint. - Benefit: Automatic enforcement of non-overlapping time ranges.
- Drawback: Requires specific database features that may not be available in all systems.
The Event Sourcing Pattern
Rather than storing the current state, you store a sequence of events. The state is reconstructed by replaying these events. This is highly detailed but can be computationally expensive to read.
- Key Addition: An append-only log table.
- Benefit: Perfect audit trail; no data is ever deleted.
- Drawback: Complex read logic; state reconstruction is not immediate.
The SCD Type 2 Approach in Detail 🔄
For most enterprise applications, SCD Type 2 offers the best balance of complexity and utility. Let us look at how this translates into an ERD structure.
Imagine a Customer entity. In a standard model, you have one row per customer ID. In a temporal model, you have multiple rows for the same customer ID, differentiated by time.
Required Attributes:
customer_id: The natural business key.version_id: A unique identifier for each specific record instance.valid_from: The timestamp when this record became effective.valid_to: The timestamp when this record ceased to be effective. Often set to NULL for the current record.is_current: A boolean flag to quickly identify the latest state.
When a customer changes their address, you do not update the existing row. Instead, you:
- Update the
valid_toof the old address row to the current timestamp. - Set
is_currentto False for the old row. - Insert a new row with the new address.
- Set
valid_fromto the current timestamp. - Set
valid_toto NULL. - Set
is_currentto True.
Period Tables and Valid Time 🗓️
While SCD Type 2 is flexible, Period Tables offer a stricter definition of time. In this model, the time interval is a single attribute. This helps prevent logic errors where valid_from is greater than valid_to.
Consider the following schema structure for a Period Table:
| Column Name | Type | Description |
|---|---|---|
entity_id |
UUID | Primary Key for the entity |
data_value |
VARCHAR | The attribute being tracked |
time_period |
PERIOD(TIMESTAMP) | Start and End of validity |
system_version |
INT | Sequence number for the row |
This structure ensures that the database engine validates the time intervals before insertion. If you attempt to insert a record that overlaps with an existing period for the same entity, the operation will fail unless explicitly allowed.
Handling Transaction Time 📝
Valid time tells you what was true. Transaction time tells you when you knew it. Sometimes, you need to know that the database believed a fact to be true, even if that fact was later proven wrong in the real world.
For example, a user might enter a wrong address. The system records it with a Transaction Time. Later, the user corrects it. If you only track Valid Time, you lose the record of the initial error. If you track Transaction Time, you preserve the system’s history of data entry.
Implementing Transaction Time usually involves hiding the columns from the user interface. These columns are managed by the database engine. When querying the “current” state, the system automatically filters out records where the transaction time has expired (i.e., the record was deleted).
Bitemporal Modeling Explained ⚖️
Bitemporal modeling combines Valid Time and Transaction Time. This is the gold standard for regulatory compliance and forensic data analysis.
Schema Implications:
- You need four time-related columns:
valid_from,valid_to,transaction_from,transaction_to. - Your indexing strategy must account for both dimensions.
- Your queries become more complex, often requiring range joins.
Query Example Logic:
To find the state of a record as it was known at a specific point in time, you filter on Transaction Time. To find the state of the world at a specific point in time, you filter on Valid Time. To find the state of the world as the system understood it at a specific point in time, you filter on both.
This level of granularity is essential for industries like finance, healthcare, and legal services, where the provenance of data is as important as the data itself.
Implementation Challenges ⚠️
Adding time to your ERD introduces complexity that must be managed carefully.
1. Storage Bloat
Every change creates a new row. Over years, a table can grow significantly larger than its non-temporal counterpart. You must plan for increased storage requirements. Partitioning by time ranges (e.g., monthly or yearly) is a common strategy to keep queries fast and maintenance easy.
2. Query Performance
Filtering by time ranges is generally fast if indexed correctly. However, reconstructing historical states often requires joining multiple tables. A query that used to take milliseconds might take seconds if it involves scanning a history table with millions of rows.
3. Application Logic Changes
Existing application code that assumes a single row per entity will break. You must refactor all CRUD operations to handle the time attributes. Insert operations become conditional logic updates.
4. Data Consistency
Ensuring that valid_from is always less than valid_to requires database constraints. Without these constraints, you risk creating invalid time periods that break historical reporting.
Best Practices for Maintenance 🧹
To keep a temporal model healthy, follow these guidelines.
- Use Surrogate Keys: Always use an internal ID for the history table, not the business key. This allows the business key to change without breaking referential integrity.
- Index Strategically: Create composite indexes on (
entity_id,valid_from). This speeds up lookups for the current record and historical snapshots. - Automate Cleanup: Implement archiving policies. If a record is 10 years old, move it to a cold storage table to keep the active table lean.
- Document the Timeline: Clearly document the difference between Valid Time and Transaction Time in your data dictionary. Developers need to know which timestamp applies to their use case.
- Validate Overlaps: Use database constraints to prevent overlapping valid periods for the same entity.
Comparison of Temporal Strategies
Selecting the right model depends on your specific needs. The table below summarizes the trade-offs.
| Strategy | Complexity | Storage Cost | Query Speed | Best Use Case |
|---|---|---|---|---|
| SCD Type 2 | Medium | Medium | High | General business history tracking |
| Period Tables | High | Medium | High | Strict regulatory compliance |
| Bitemporal | Very High | High | Medium | Forensic analysis, system auditing |
| Event Sourcing | High | Very High | Low (Read) | State reconstruction, real-time feeds |
Final Considerations for Data Architects
Integrating time into your Entity Relationship Diagram is a decision that impacts the lifecycle of your data. It is not merely a technical adjustment; it is a shift in how you view information.
When you design with time in mind, you acknowledge that data is not static. It flows. It changes. It ages. By building these capabilities into the foundation of your schema, you future-proof your systems against the need for retrospective analysis.
Start by identifying which attributes in your system truly require history. Not every column needs a timestamp. Focus on high-value data points like financial balances, personnel assignments, and product pricing. Apply the temporal patterns selectively to avoid unnecessary overhead.
As your system matures, you may find that the initial design needs refinement. Temporal data models are iterative. Monitor your query performance and storage growth. Adjust your partitioning and indexing strategies as the volume of historical data accumulates.
Ultimately, a time-aware ERD provides a single source of truth that respects the past while serving the present. It ensures that when questions arise about “why” something happened, the answer is already written in your database, waiting to be retrieved.